
第四章 Dynamic Programming 读书笔记
The term dynamic programming (DP) refers to a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP).
The key idea of DP, and of reinforcement learning generally, is the use of value functions to organize and structure the search for good policies.
经典动态规划的局限性
- 需要一个完美的环境模型
- 需要的计算量极大
优点:理论上帮助理解强化学习的方法。
In fact, all of these methods can be viewed as attempts to achieve much the same effect as DP, only with less computation and without assuming a perfect model of the environment.
DP可以用贝尔曼方程转化为需要的值函数和策略。
4.1 策略评定 Policy Evaluation(Prediction)

4.2 策略改进 Policy Improvement
根据值函数 导出策略。
4.3 策略迭代 Policy Iteration

4.4 值迭代 Value Iteration

4.5 异步动态规划 Asynchronous Dynamic Programming
Asynchronous DP algorithms are in-place iterative DP algorithms that are not organized in terms of systematic sweeps of the state set
优先更新更有价值的状态,不意味着不更新部分状态。
更新智能体遇到的状态就是一个应用,智能体遇到的状态是相对重要的状态。
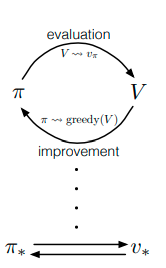
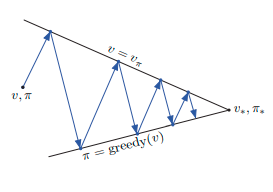
4.6 通用策略迭代 Generalized Policy Iteration
4.7 Efficiency of Dynamic Programming
4.8 总结 Summary
Policy evaluation refers to the (typically) iterative computation of the value function for a given policy. Policy improvement refers to the computation of an improved policy given the value function for that policy.
Putting these two computations together, we obtain policy iteration and value iteration,
the two most popular DP methods.
- DP更新是期望更新,直到赋值后的改变不大时就停止
- GPI的思想。
- 异步DP
- 自举

 浙公网安备 33010602011771号
浙公网安备 33010602011771号