

玻尔兹曼机
能量函数
无向模型中许多有趣的理论结果都依赖于\(\forall x, \tilde{p}(x) > 0\)这个假设。使这个条件满足的一种简单方式是使用基于能量的模型,其中
\(E(\mathbf{x})\)被称作是能量函数。对所有的\(z\),\(exp(z)\)都是正的,这保证了没有一个能量函数会使得某一个状态\(\mathbf{x}\)的概率为0。我们可以完全自由地选择那些能够简化学习过程的能量函数。如果我们直接学习各个团势能,我们需要利用约束。
服从上式的任意分布都是玻尔兹曼分布,因此把许多基于能量的模型称为玻尔兹曼机
分离以及图模型结构
如果它们之间没有路径,或者所有路径都包含可观测的变量,那么它们是分离的。我们认为仅涉及未观察到的变量的路径是 ‘‘活跃’’ 的,而包括可观察变量的路径称为 ‘‘非活跃’’ 的。
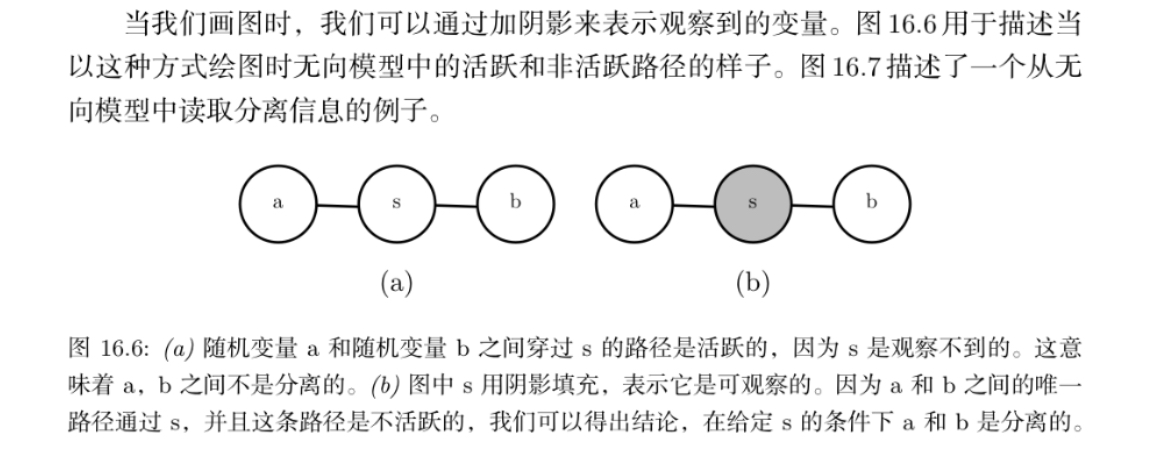
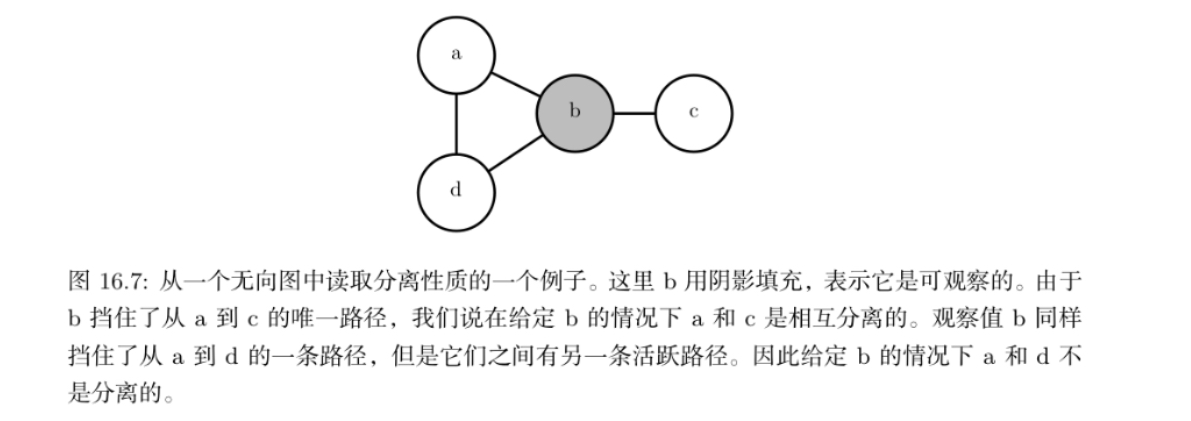
更为一般的图模型结构

有向图和无向图之间的转换
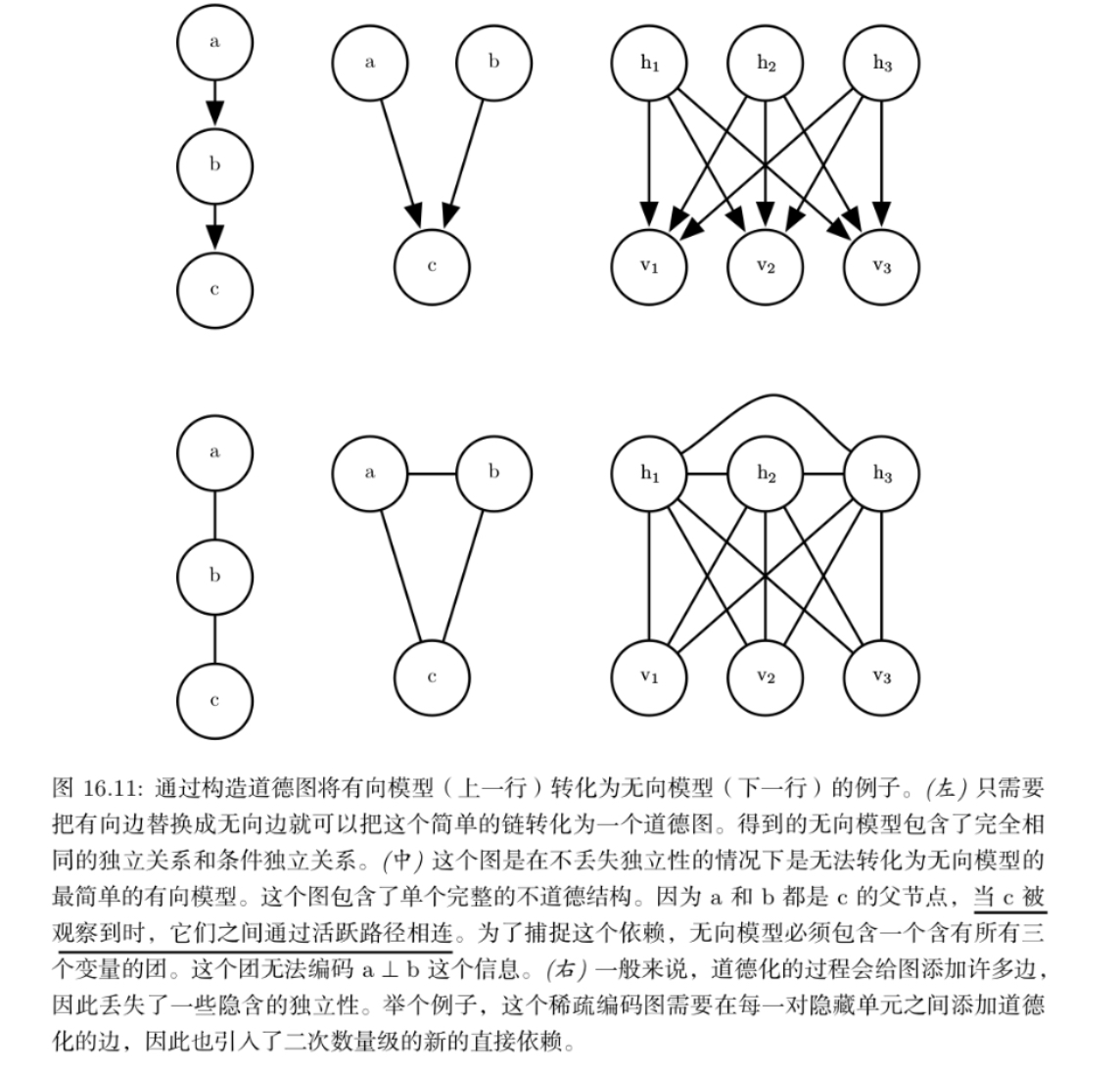
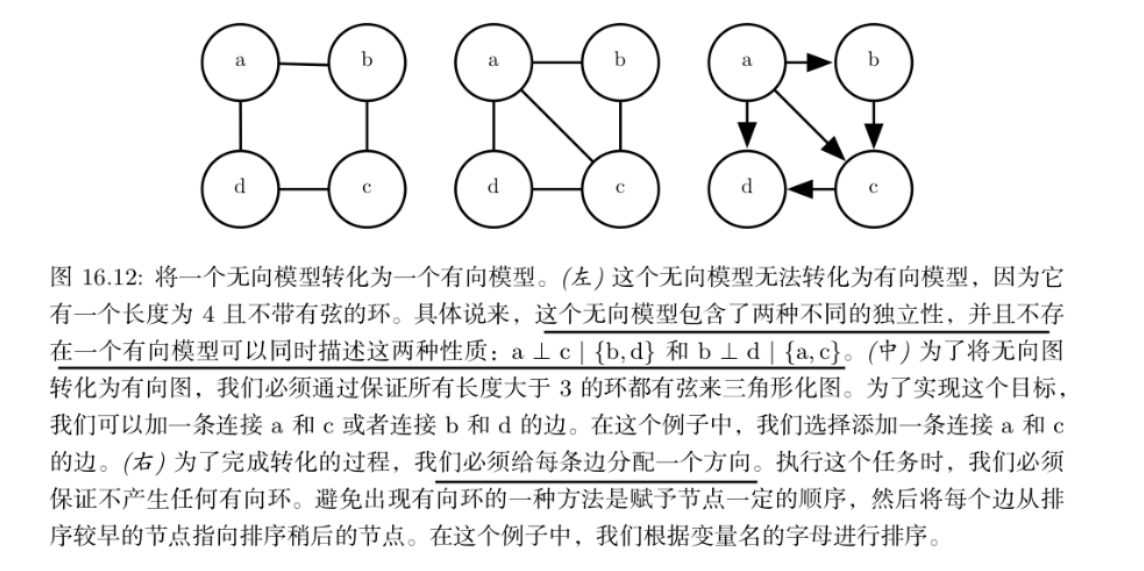
无向模型可以包括有向模型不能完美表示的子结构。具体来说,如果 U 包含长度大于 3 的环,则有向图 D 不能捕获无向模型 U 所包含的所有条件 独立性,除非该环还包含弦
如果 U 具有长度为 4 或更大的环,并且这些环没有弦,我 们必须在将它们转换为有向模型之前添加弦。添加这些弦会丢弃在 U 中编码的一些独立信息。通过将弦添加到 U 形成的图被称为弦图或者三角形化图,因为我们现在可以用更小的、三角的环来描述所有的环
结构化概率模型的深度学习方法
深度学习基本上总是利用分布式表示的思想
分布式表示和局部表示的区别
局部表示
定义:每个概念或类别由单一的、独立的符号或神经元表示。
例如:在传统NLP中,one-hot编码的每个词对应一个唯一的维度(如“猫”= [1, 0, 0], “狗”= [0, 1, 0])。
缺点:
高维稀疏,无法捕捉语义关系(如“猫”和“狗”都是动物,但one-hot编码无法体现这一点)。
泛化能力差,新增类别需扩展维度。
分布式表示
定义:每个概念或类别由多个神经元的协同激活模式表示,且每个神经元参与表示多个概念。
例如:词向量(Word2Vec)中,“猫”= [0.2, -0.5, 0.7],“狗”= [0.3, -0.4, 0.6],它们的向量相似性反映了语义关联。
核心思想:
低维稠密:用连续向量表示特征。
共享表示:不同概念共享底层特征(如“猫”和“狗”共享“动物”这一特征)。
分布式表示和分布式学习
分布式表示
核心思想:用低维稠密向量表示数据,其中每个概念(如单词、图像、类别)由多个神经元协同编码,且每个神经元参与多个概念的表示。
本质:一种数据编码方式,强调如何高效、泛化地表示信息。
嵌入空间:
分布式表示可看作将数据映射到某个流形,其中语义相关的样本在流形上邻近
因子分解视角:
分布式表示可视为对数据联合概率的分解(如矩阵分解、张量分解)。
分布式学习是将机器学习任务的计算过程分布到多个设备(如GPU、服务器)上,以加速训练或处理大规模数据,是一种计算架构,强调如何高效并行化训练。
许多深度学习模型可以设计来加速Gibbs 采样或者变分推断。此外,深度学习模型包含了大量的潜变量,使得高效 的数值计算代码显得格外重要。除了选择高级推断算法之外,这提供了另外的动机, 用于将结点分组成层,相邻两层之间用一个矩阵来描述相互作用。这要求实现算法的单个步骤可以实现高效的矩阵乘积运算,或者专门适用于稀疏连接的操作,例如块对角矩阵乘积或卷积。
推断算法

精确推断问题可以描述为一个优化问题,通过近似这样一个潜在的优化问题,可以推导出近似推断算法。
为了构造这样一个优化问题,假设我们有一个包含可见变量 \(v\)和潜变量\(h\)的概率模型。我们希望计算观察数据的对数概率\(\log p(v; \theta)\)。
有时候如果边缘化消去\(h\)的操作很费时,我们会难以计算 \(\log p(v; \theta)\)。作为替代,我们可以计算一个\(\log p(v; \theta)\)的下界\(\mathcal{L}(v, \theta, q)\)。这个下界被称为证据下界(ELBO)。这个下界的另一个常用名称是负变分自由能。具体地,这个证据下界是这样定义的:
其中\(q\)是关于\(h\)的一个任意概率分布。
因为\(\log p(v)\)和\(\mathcal{L}(v, \theta, q)\)之间的距离是由 KL 散度来衡量的,且 KL 散度总是非负的,我们可以发现\(\mathcal{L}\)总是小于等于所求的对数概率。当且仅当分布\(q\)完全相等于\(p(h \mid v)\)时取到等号。
通过一些计算后,可以进行一些简化,也是证据下届的标准定义:
于是可以将推断问题看作是找一个分布q使得\(\mathcal{L}\)最大的过程
玻尔兹曼机


玻尔兹曼机的学习方法通常基于最大似然,当基于最大似然的学习规则训练时,连接两个单 元的特定权重的更新仅取决于这两个单元在不同分布下收集的统计信息:\(P_{model}(v)\)和\(\hat{P}_{data}(v)P_{model}(h \mid v)\)
受限玻尔兹曼机(RBM)
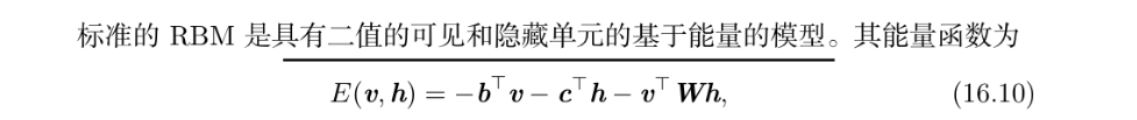

结合这些属性可以得到高效的块吉布斯采样,它在同时采样所有h和同时采样所有v之间交替
RBM 是包含一层可观察变量和单 层潜变量的无向概率图模型。RBM 可以堆叠起来(一个在另一个的顶部)形成更深 的模型。
RBM展示了典型的图模型深度学习方法:使用多层潜变量,并由矩阵参数化层之间的高效相互作用来完成表示学习。
RBM的权重矩阵设计之所以便于学习,核心在于:
对称无向结构:简化了梯度计算和参数更新。
条件独立性:支持高效采样和并行计算。
对比散度算法:避免了配分函数的直接计算。
线性可分性:权重直接反映特征相关性,易于优化和解释。
深度信念网络(DBN)
DBN是生成模型,试图学习数据的概率分布;DNN是判别模型,直接学习输入到输出的映射。
DBN的底层通过RBM堆叠,强调特征的无监督学习;DNN的层是通用的可微模块(如ReLU+线性变换)
只有一个隐藏层的 DBN 只是一个 RBM。

这个术语应特指最深层中具有无向连接,而在所有其他连续 层之间存在向下有向连接的模型。
DBN的连接方式
顶层:DBN的顶层通常是一个RBM,其连接是无向的。
其他层:除了顶层之外,其他层之间的连接是有向的。
层内无连接:DBN中每一层内的神经元之间都没有连接。
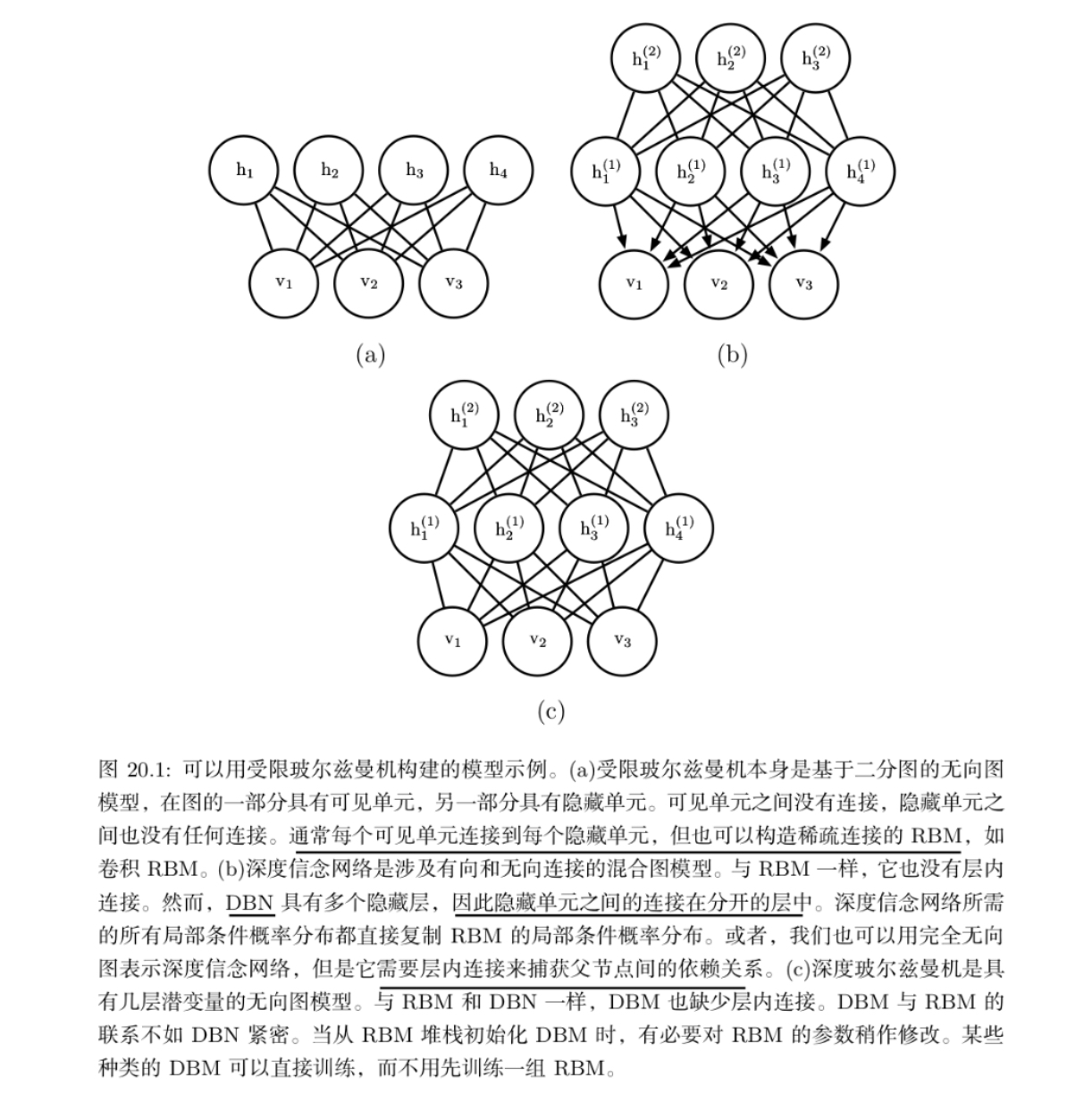
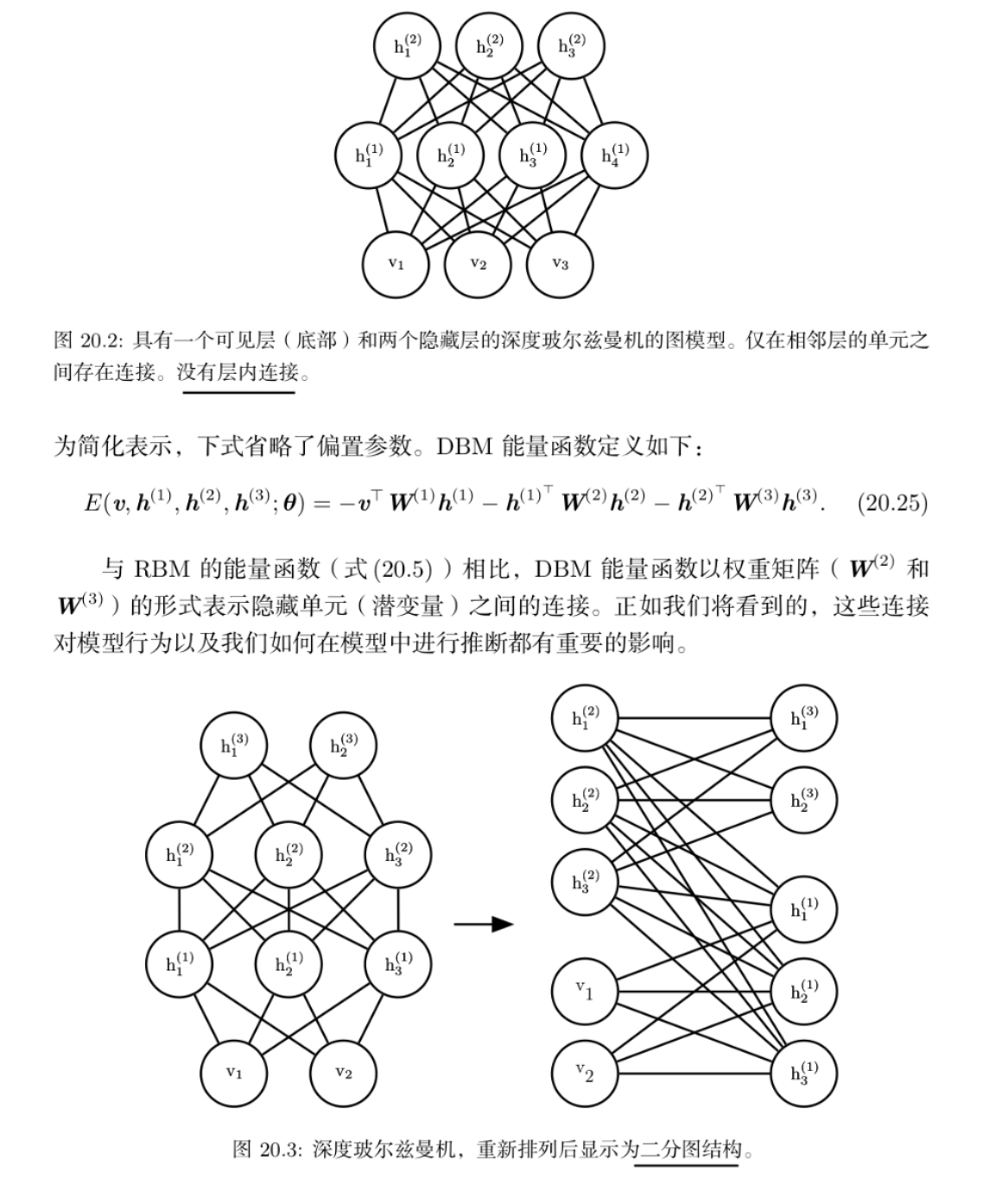
深度玻尔兹曼机(DBM)
深度玻尔兹曼机(DBM)是另一种深度生成模型。
与深度信念网络(DBN)不同的是, 它是一个完全无向的模型。
与 RBM 不同的是,DBM 有几层潜变量(RBM 只有一层)。 但是像 RBM 一样,每一层内的每个变量是相互独立的,并条件于相邻层中的变量。

训练


变分推断与吉布斯采样的结合:
使用均匀场推断快速近似后验(正相),通过吉布斯采样精确估计模型分布(负相)。
对比散度(CD-k):
通过少量吉布斯步(k≈1)近似配分函数的梯度,避免高计算成本。
伯努利分布的核心作用:
所有可见层和隐层单元的激活状态均为二值,采样依赖伯努利分布。
参数更新的高效性:
小批量训练加速收敛,动量或学习率衰减可进一步优化(伪代码中未显式实现)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号