


ElasticSearch集成IK分词器
一、IK分词器是什么
把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,
默认的中文分词是将每个字看成一个词,比如"中国的花"会被分为"中","国","的","花",这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
二、下载IK分词器
链接https://github.com/medcl/elasticsearch-analysis-ik/releases
三、安装IK
-
下载解压后放到ES安装目录plugins下,我创建了一个ik的文件夹,将解压的内容全部放进去
/usr/local/rb2010/elk/elasticsearch/elasticsearch-7.7.0/plugins/ik


- 重新启动ES,会看到加载了IK插件
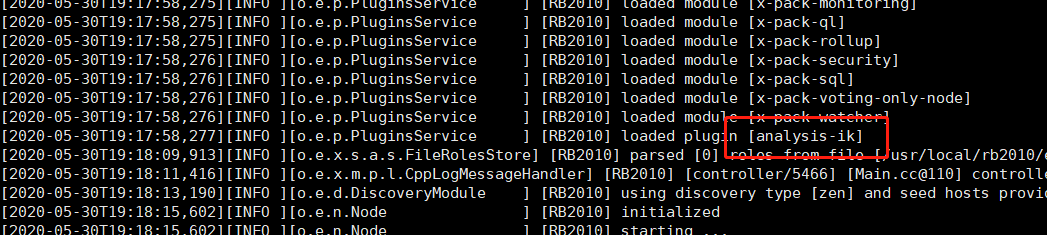
四、测试
-
打开kibana (没有kibana、ES的请参考如下链接)
-
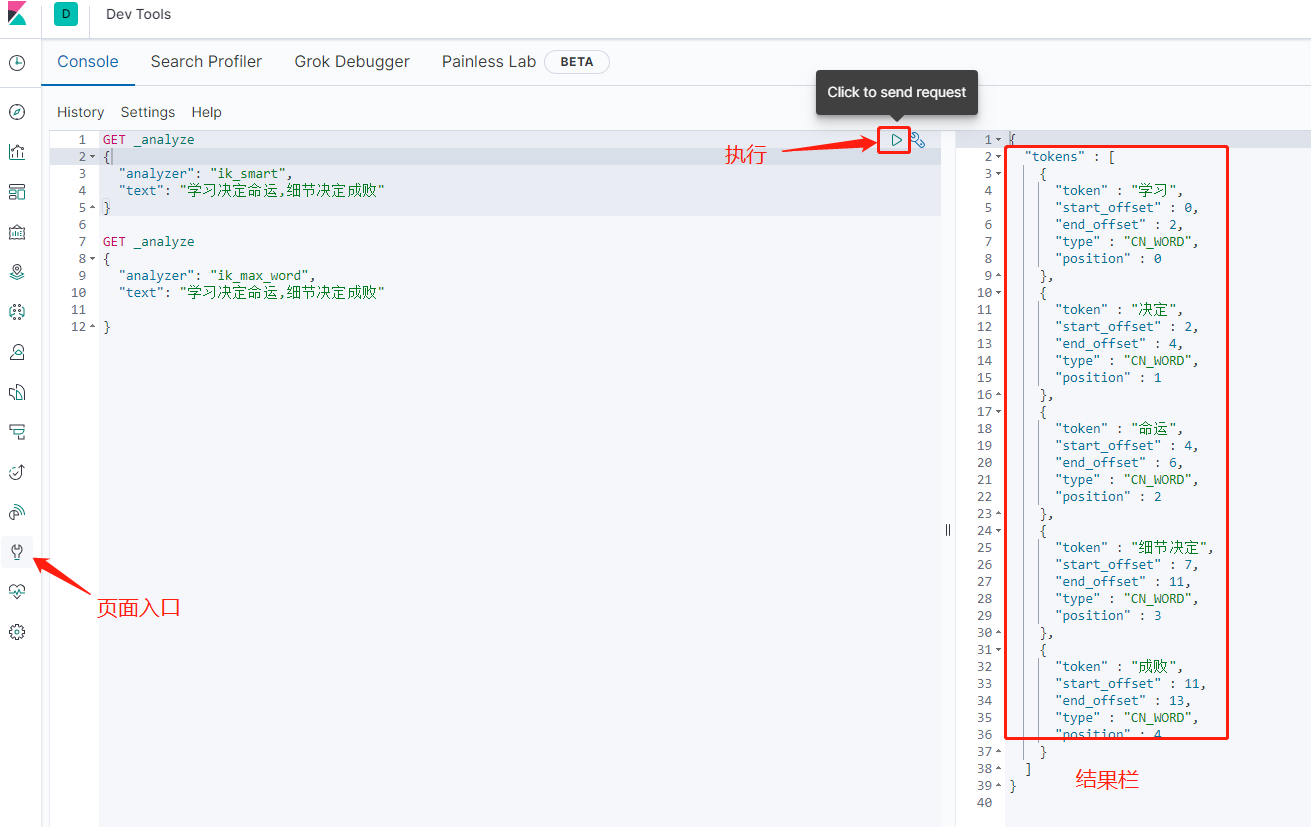
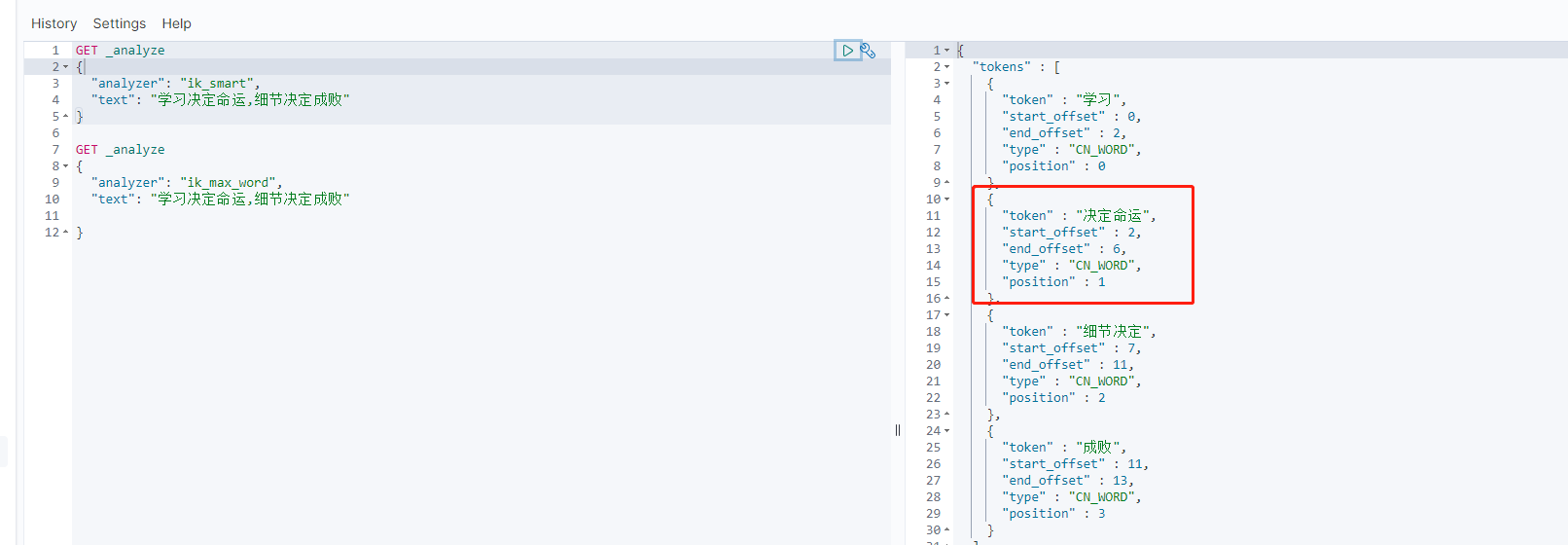
两种分词模式
ik_smart:只是将文本进行拆分
ik_max_word:最大化的将文本进行拆分,将所有拆分可能都列出来
应用场景:搜索的条件尽可能的使用ik_max_word拆分,创建索引的时候使用ik_smart拆分
-
查询方式,对比下就知道怎么回事了
![image-20200530224744043]()
五、自定义词典
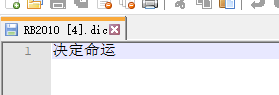
例如上面的例子中,我想让“决定命运”变成一个词,不被拆分,这时我就需要定义自己的词典
- 进入IK分词器的目录(就是刚刚解压放到ES中的目录)
- 打开config,新建一个.dic的文本,里面输入“决定命运”
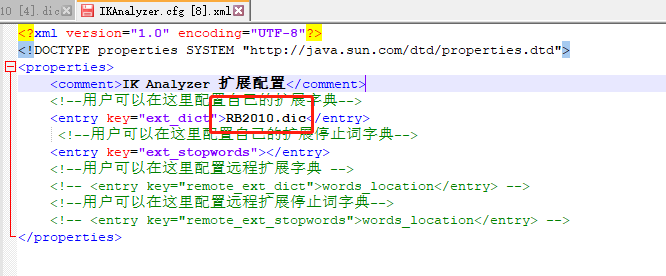
- 修改 IKAnalyzer.cfg.xml 文件,在里面加入自己的词典
4.重启ES后再次使用kabana搜索,刚刚设置的“决定命运”就没有被分割了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号