微视推荐系统的特征工程
source: 浅谈微视推荐系统中的特征工程 - 知乎 (zhihu.com)
这篇博文分为特征提取, 特征选择, 特征重要性三个部分, 围绕短视频平台推荐系统进行了特征工程的介绍
一、特征提取
确定了哪些因素可能与预测目标相关后,我们需要将此信息抽取成特征
从描述对象上,微视推荐系统中的特征可分为:
- user特征
完播率,播放完整度,快速划过率
- item特征
曝光数,互动渗透率,被完播率,被快速划过次数
- context特征
请求时间,网络环境,操作系统,渠道
- session特征
基于用户最近的行为,比如用户近50条流水中分视频类别的完播个数、快速划过个数
1 数值特征
1)分桶
特征值跨越不同的数量级,例如LR往往只对较大的特征值敏感,此时通常采用分桶,即将数值变量离散化,之后进行one-hot编码。
分桶的数量和宽度可以根据业务领域的经验来指定,也有一些常规做法:
- 等距分桶
- 等频分桶
- 模型分桶:例如利用聚类将特征分为多个类别;或者利用树模型,利用特征分割点进行离散化(?)
2)截断
3)缺失值处理
4)特征交叉
- 内积
- 笛卡尔积
- 哈达玛(Hadamard)积
5)标准化与缩放
6)数据平滑
行为次数/曝光次数 是常用的比值类特征
CTR的平滑处理
CTR除了是模型的预测值, 也可以作为其他模型的输入特征
- 贝叶斯平滑
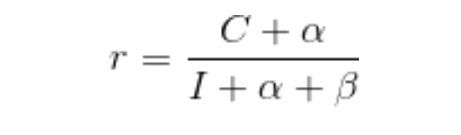
- 威尔逊区间平滑
2 类别特征
2)散列编码
对于取值特别多的类别特征, 使用one-hot编码得到的特征矩阵会非常稀疏
如果特征量和样本量已经很大, 使用聚类, PCA降维的计算量本身也会很大
此时可以引入一种简单的降维方法——特征哈希
5)类别特征之间的交叉组合
6)类别与数值特征的交叉组合
e.g.
1视频类目_曝光次数_快划次数, 某个用户的样本: 王者荣耀_31_31
2视频清晰度等级_用户手机屏幕拉伸度
3 embedding特征
1)视频embedding
2)user embedding
3)作者embedding
4 context特征
通常是客户端带的信息, 在用户授权后可直接获取, 比如请求时间, 用户手机品牌, 手机型号, 操作系统, 当前网络状态(4g/wifi), 用户渠道等
5 session特征
session划分方法:
固定行为数窗口:例如最近100条行为中分视频类别的完播个数
固定时间窗口:例如最近3天里有正向行为的item id
连续行为窗口:例如用户1次打开app到关闭app期间的播放互动行为
获取用户的session数据之后,可以直接将session里对应item id序列作为特征,或者是session内的类别统计数据,也可以将预训练好的item embedding构造成session特征
二、特征选择
特征选择的主要目的:
简化模型,节省存储和计算开销
减少特征数量,改善通用性,降低过拟合风险
Filter
Wrapping
Embedding
三、特征重要性分析
判断哪些特征对模型预测的影响力最大
单特征auc
对每个单特征训练模型,计算对应的auc或gauc。这个方法效率较低。
实际应用中,可以有选择的对某些特征子集进行实验
1)逐个特征值置0
2)某个特征取随机值
3)特征值随机打乱

 浙公网安备 33010602011771号
浙公网安备 33010602011771号