paper 3:Learning to Build User-tag Profile in Recommendation System (CIKM'20)
paper链接: Learning to Build User-tag Profile in Recommendation System - AMiner
原博链接:推荐系统遇上深度学习(九十八)-[微信]推荐系统中更好地学习用户-标签偏好 - 简书 (jianshu.com)
outline:
user profiling是推荐系统最重要的组成部分之一, 在其中有用户的人口统计学信息(性别, 年龄, 地域等) 和用户行为信息(浏览, 搜索历史等)
在user profiling的众多维度中, tagging作为用户兴趣的表达, 是可解释并且被广泛使用的.
该paper主要介绍了微信看一看("Top Stories")中,如何进行用户对标签(tags)的兴趣建模(UTPM),进而提升召回和推荐的效果。
该paper引入了UTPM模型, a multi-label classification using deep neural network.
具体地, UTPM使用了multi-head attention机制(shared query)来学习稀疏特征.
然后类似FM进行特征交叉
最后设计了一种novel joint method来学习用户点击对不同tag的偏好
- 推荐系统架构
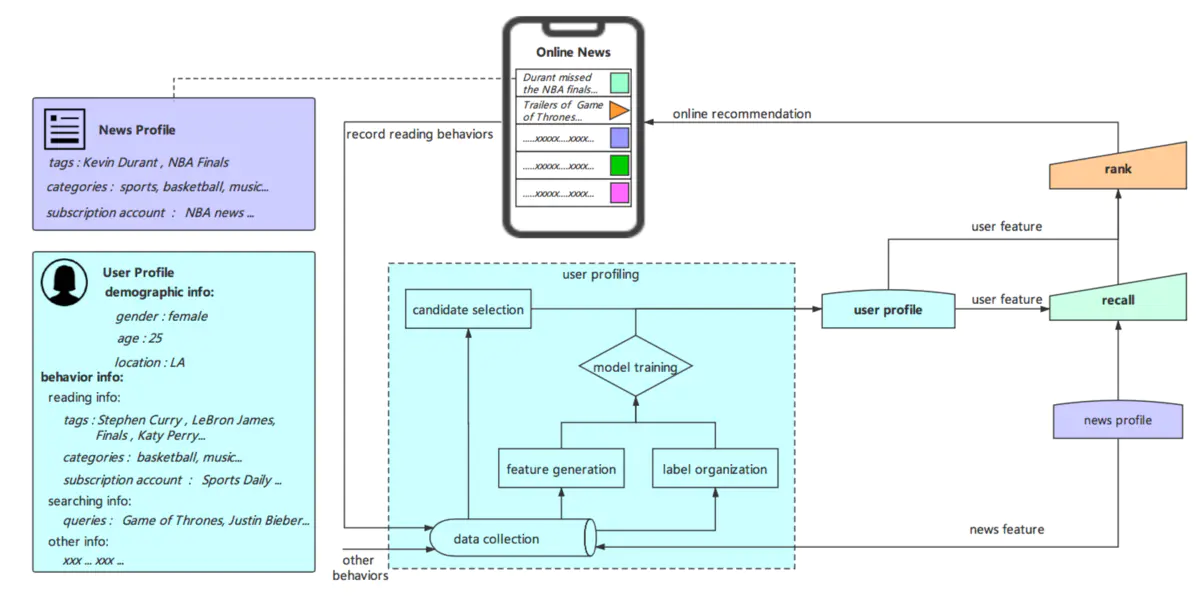
可以看到,整个推荐系统架构主要包含四部分:
- 新闻画像层(news profile layer):对新闻相关的特征如标签,类别等进行提取
- 用户画像层(user profile layer):对用户的基本画像特征和行为特征进行建模。这里很重要的一块是对用户偏好标签的预测,这里将用户点击过的文章对应的标签集合作为候选集,基于后文将要介绍的模型对这些标签进行偏好预测,并用于后续阶段
- 召回层(recall layer):有多种召回方式,包括基于标签的召回、基于协同过滤的召回和基于模型的召回
- 排序层(rank layer):可以使用更为复杂的模型对召回层得到的结果进行精确的排序,最后展示给用户。
本文重点关注如何建模用户对于文章标签的偏好预测,为此提出了UTPM模型。
UTPM模型一共分为5层
- feature input layer:
输入特征包含两部分:
- 用户画像信息:年龄、性别等
- 用户历史阅读信息:用户读过的新闻对应的标签、类别、订阅账户所处field等
所有特征都是categorical的. 对于多值离散特征,会先通过embedding look-up*转换成相同长度(length=128)的向量
* tf.nn.embedding_lookup(params, ids)就是按照ids顺序返回params中的第ids行。
- attention fushion layer
本层采用2-head self-attention, 主要用于解决问题1: 如何自动地选择特征, 并且衡量特征间的交互
field内的特征, 通过multi-head attention后, 将会得到不同的attention weight
以tags为例, 假设第$k$个特征field有$H$个tag feature, $t_i \in \mathbb{R}^E$ 代表第i个tag(embedding look-up向量)
对于第1个attention, 先计算$t_i$的权重$\alpha_{i,1}$
softmax中的指数为query 1与transformed后的$t_i$的dot product, 代表第$i$个tag对分类任务的重要性, 随后进行softmax归一化
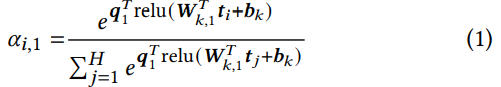
然后, 利用上述weight, 在本特征field内进行加权求和, 得到embedding向量$f_1$.

注意, 全局共享query 1, 第$k$个field内共享变换矩阵$W_{k,1}$.
第2个head的self-attention构建方式类似, 得到$f_2$后, 与$f_1$ concatenate得到本层输出$x \in \mathbb{R}^E$, 喂给下一层.
1.对多值离散特征(embedding look-up后的向量)进行处理,最简单的方法是avg或max-pooling,
但这些方法没有考虑到不同取值的重要性,因此文本采用multi-head self-attention
2. attention机制源于机器翻译, 思路是word在不同的context中会有不同的权重
- cross feature layer
本层主要进行特征交叉,与FM类似,对$x$中每一个维$x_i$,引入对应的隐向量$v_i$,
交叉结果为:$<v_i, v_j>x_ix_j$
为了让线性部分与交叉部分相当, 在线性部分增加了L2正则化项
- fully connect layer
这里将attention层的输出$x$和交叉层的输出$c$进行拼接,
经过两层全连接层可得到最终的用户向量 $u$
- predicting layer
损失函数采用负对数函数:
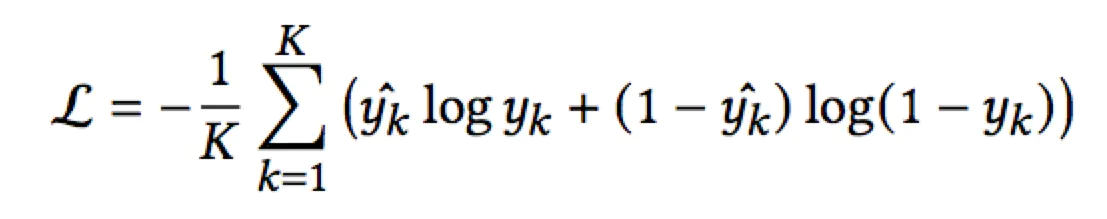
实验结果说明这种学习方式能够取得更好的实验效果。
实验结果
对比了多类模型.包括YouTube, 1-head/2-head attention...
除了负对数损失函数, 研究者还引入了(top K推荐 intersect 点击集)的点击率作为度量
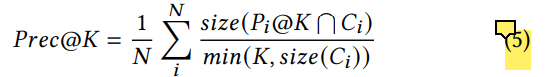
Pi@K指用户i收到的top K个推荐, $C_i$指用户实际点击的集合
* 为避免点击集的size太小导致该度量过小, 分母采用两者的最小值.
遗留问题:
query如何给定?
transform时为何使用relu?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号