学习笔记: sql
Q3:数据倾斜系列
链接:https://zhuanlan.zhihu.com/p/262900663
___________________________________________________________
Q3.1:
什么是数据倾斜?
由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。
具体表现为在执行任务的时候,任务进度长时间维持在99%左右,查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。最长时长远大于平均时长。
可以形象的理解为现在有一堆砖要搬,但是分配任务的时候某个(机器)人1个人接收到了自己要搬10万块转,但是其他人都是几百块转顶多上千块转,最后导致砖一直没搬完,工程进度搁置。
————————————
Q3.2 数据倾斜产生的原因?
通过之前的初识Hadoop和初识hive我们知道
在执行Hive SQL语句的过程中会经历Map和Reduce两个步骤,
下面通过统计单词出现的次数来举例说明:
如图所示:
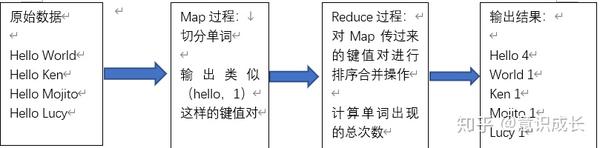
可以看到,Map过程会将原始数据转换成类似于(hello,1)这样的<key,value>键值对,然后Reduce过程会对具有相同key的数据进行合并计算。
在默认情况下,具有相同key的数据会被放在同一个Reduce任务中,因此就会出现一个人累死,其他人闲死的情况,即出现数据倾斜的问题。
在执行Hive SQL语句或者运行MapReduce作业时如果一直卡在Map100%,Reduce99%,一般就是遇到了数据倾斜的问题。
上面只是数据倾斜发生的一种可能,大致来讲,数据倾斜发生的原因一般为以下情况
1)、key分布不均匀(如上图例子)
2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
________________________________________
Q3.3:数据倾斜的解决方案?
A:
1)各节点Reduce操作不均衡: 当使用group by分组时,如果某些key占比非常大,由于相同key的数据会被拉取到相同节点中执行Reduce操作,因此会出现某些节点需要计算的数据量远大于其他节点的情况,造成数据倾斜。最明显的特征是在Reduce任务执行时,进度停留在99%的时间非常长,此时1%的节点计算量甚至可能超过其余99%节点计算量的总和。
通过设置“set hive.map.aggr=true”和“set hive.groupby.skewindata=true”参数可以有效规避这个问题。
此时生成的查询会将此前的一个MapReduce作业拆分成两个任务。
- 在第一个任务中,Map任务的输出结果结合会随机分布到Reduce任务中,每个Reduce任务进行部分聚合操作,并输出结果,这样相同key的数据会被拉取到不同的节点中,从而达到负载均衡的目的。
- 第二个任务根据第一个任务预处理的数据结果将相同key数据分发到同一个Reduce任务中,完成最终的聚合操作。
2)Map任务的计算量非常大: 如执行 count(*) 、 sum(case when...) 等语句时,需要设置Map任务数量的上限,可以通过“set mapred.map.tasks”这条语句设置合理的Map任务数量。
3)如果Hive SQL 语句中计算的数据量非常大,例如下面的语句:
select
a, count(distinct b)from t group by a
此时就会因为 count(distinct b) 函数而出现数据倾斜的问题,可以使用sum...group by 代替该函数,例如:
select a, sum(1) from (select a,b from t group by a,b) group by a
4)当需要执行join操作但是关键字字段存在大量空置时,则可以在join操作过程中忽略空值,然后再通过union操作加上空值。如:
select * from log a join
users b
on a.id=b.id where a.id is not null union all select * from log a where a.id is null
——————————————
多行一列转一行多列
pivot函数
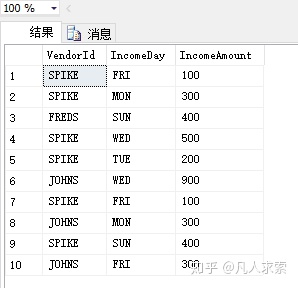
比如说我们想在一行看到一个供应商的各周几总收入
- 方法一: ,可以使用case when + sum + group by 要固定的key值
select VendorId , sum(case when IncomeDay='MoN' then IncomeAmount else 0 end) MON, sum(case when IncomeDay='TUE' then IncomeAmount else 0 end) TUE, sum(case when IncomeDay='WED' then IncomeAmount else 0 end) WED, sum(case when IncomeDay='THU' then IncomeAmount else 0 end) THU, sum(case when IncomeDay='FRI' then IncomeAmount else 0 end) FRI, sum(case when IncomeDay='SAT' then IncomeAmount else 0 end) SAT, sum(case when IncomeDay='SUN' then IncomeAmount else 0 end) SUN from DailyIncome group by VendorId
- 方法二: 先select, 然后用pivot函数, 更加简洁(前提是已知所有列, 非动态转换)(不用group by)
形式为 pivot( 聚合函数() for 枚举列 in (枚举列表) )
select * from DailyIncome --给定数据源
pivot (sum(IncomeAmount) for IncomeDay in ([MON],[TUE],[WED],[THU],[FRI],[SAT],[SUN])) as table_IncomePerDay --新列名须用[]; 最后相当于创建了一个pivot透视表
多行一列转一行一列
链接:https://zhuanlan.zhihu.com/p/332729976
tb_movie.name tb_movie.typ
《八佰》 战争
《八佰》 动作
《八佰》 抗日
《八佰》 剧情
《姜子牙》 动画
《姜子牙》 神话
《姜子牙》 科幻
《姜子牙》 动作
《姜子牙》 伦理
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难
需要实现:
《八佰》 战争,动作,抗日,剧情
《姜子牙》 动画,神话,科幻,动作,伦理
《战狼2》 战争,动作,灾难
使用concat_ws + group by
select
name, concat_ws(",", collect_list(typ)) as category from tb_movie group by name
一行一列转多行一列
链接:https://zhuanlan.zhihu.com/p/214254848
select数据源后, 进行列转行 lateral view + explode + split
如将useridList->[123,345,234,2334]转为
123
345
234
2334
select userid2 from ( select substr(useridList,2,length(useridList)-2) as userid --注意,这里需要将括号去掉。 from a ) t1 lateral view
explode(split(userid, ',')) t1 as userid2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号