paper 2:CTR预测(GBDT+LR)及评价指标
Facebook在2014年的这篇论文中提出了GBDT+LR的CTR预测模型, 利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当作LR模型输入,预估CTR的模型结构。
训练方式
- 方式一: 当在某日训练GBDT+LR模型, 并且在后续若干日(比如6日)测试时发现, 当测试日期离训练日期变远时, 训练误差有1%/天的提高.
- 方式二: 于是作者考虑采用另外一种训练方式, 即每天或每几天训练一个GBDT模型, 然后LR模型以近乎实时的方式训练.
Online Linear Classifier
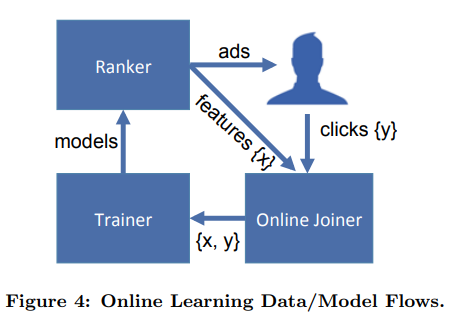
Online Data Joiner
对LR的实时训练需要实时的label-feature joiner
- 负样本的labeling与time window
negative label如何给定:用户看到广告后,在给定周期(time window)内没有点击广告
过长的time window会delay实时的训练数据,增加存储空间的消耗
而过短的time window会导致部分click label的缺失
- 数据流: impression stream + click stream -> training stream
当用户在Facebook完成某个行为后,用户所能看到的内容被刷新, 此时会生成一个新的request ID
数据流从request抵达ranker开始, ranker为该request对应的设备提供候选的ads, 同时ad本身, 和用于ranking的features将被加入impression stream
如果用户选择点击ad, 点击行为将被加入click stream
为了实现stream to stream的join, 系统采用了Hash队列来对impressions打label
trainer连续地从training stream中学习, 并且周期性地publish new models到ranker,
最终形成了一个时间上紧凑的模型学习闭环, 且特征分布和模型表现的变化能被捕捉到
注意, 异常值将可能破坏这个learning system. 例如click stream如果不再更新, 那么empirical CTR几乎为0, 那么trainer的预测CTR将会非常低, 从而ad impressions会大大下降.
于是需要引入异常检测机制, 例如当training data的分布有突变时, 让trainer和joiner的连接自动断开.
CTR预测模型评价指标
- Calibration
\[Calibration = \frac{average \ estimated \ CTR} {average \ empirical \ CTR} \]
- 标准化交叉熵(Normalized Cross-Entropy, 简称NE)
\[ NE = \frac {-\frac {1}{N} \sum_{i=1}^N \frac{1+y_i}{2} log (p_i) + \frac{1-y_i}{2} log (1-p_i)} {-(p \cdot log(p)+ (1-p) \cdot log(1-p))} \]
- Area-Under-ROC(简称AUC)
AUC仅适用于二分类问题. LR作为一个回归模型, 为何要使用AUC评估?
对于如LR这种soft classifier, 给定不同的分类阈值, 会有不同的(TPR, FPR)表现.
当分类阈值减小时, 预测为正例的样本数predicted positives必然增加, 我们有predicted positives = TP + FP.
但TPR= TP/P, FPR=FP/N这两个值的变化趋势不一定.
我们可以注意到:
1. AUC在度量ranking quality*时, 没有考虑calibration;
* (AUC的理解分为两类: 1. ROC线下面积 2. 模型的排序能力. 在第2类理解中, AUC值等价于ranking quality: Wilcoxon-Mann-Witney test中ranking的score, 即所有的(正例, 负例)pair中, 正例的预测值>负例的预测值的pair数的占比.
e.g. $M$个正例, $N$个负例, 总共有$M \times N$对pairs, 若其中有$K$对(正例, 负例)的rank正确, 则$AUC = K / (M \times N)$ [待找资料验证])
2. NE在评价模型预测效果的同时, 隐式体现了calibration.
e.g. 如果模型over-predict了2倍, 将全局的预测CTR乘以0.5, 那么NE会有相应的提升, 但对AUC没有影响.(对排序没有影响)
个人问题: GBDT每次训练后的树不一样, 怎么输入到LR中去?
延伸:
1. LR的损失函数
- 不用回归中常用的平方和损失函数:
因为LR的MSE非凸. 且MSE有梯度消失(只需在NN中考虑?)
- 不用朴素的分类accuracy:
假设有$N$个样本, $y^{i} \in \{+1, -1\}, \ i= 1,\ldots,N$.
注意到sigmoid函数 $g(x) = \frac {1} {1+e^{-x}} $ 存在如下特性: $ g(-x) = 1 - g(x)$
LR模型中的损失函数(负对数似然函数)可以写作: (注意此时与$y^{i} \in \{+1, 0\} $的形式略有差异)
\[ L(\omega) = -\sum_{i=1}^N \log ( g(y^{(i)} \omega^T x^{(i)}) ) \]
此时$L(\omega)$比朴素的分类accuracy更能体现模型之间的差异.
详细推导与例子参见: https://www.cnblogs.com/iloveyouforever/p/4353491.html
2. 一文看懂广告投放系统设计: https://zhuanlan.zhihu.com/p/67578681
3. 广告系统的组成简答:https://www.zhihu.com/question/19662693/answer/60506017
- [面向广告商的工具] 广告商可以根据自己的需要定制投放人群:年龄,性别,地理位置,职业,兴趣等等。
- [算法] 个性化推荐:在众多符合条件的广告中选择最合适的一个。
- [算法] 决定在哪里放广告:这在以前其实不是个事,因为就几个能放广告的固定位置(banner,页面右侧)。然而随着Facebook发明了Feed Ads,在新鲜事里放原生广告成了社交类产品的标配。以微信为例,在朋友圈里的第几个位置放广告其实是个挺有学问的事。放高了影响用户正常体验,放低了没人看得到。这大该就是微信口中的“实时社交混排算法”吧。
- [算法] 定价:放的这个广告该跟广告商要多少钱。这受很多因素影响:放的位置高低,有多少个其他广告一起竞价,等等。
所以,个性化推荐只是整个广告流程的一个小部分。不过,好的个性化推荐可以提高广告的点击率,从而增加产品营收。
4.广告与推荐的区别:
链接:https://www.zhihu.com/question/19662693/answer/757347092
- 对于计算广告来说,本质上要处理的是三方利益的协调问题,这三方分别是广告主、用户和媒体。
- 对于推荐系统来说,本质上要处理的是用户体验的问题。
如果列举出两个领域重点要考虑的技术问题,大家也能体会到二者的不同(排名大致分先后):
- 计算广告:CTR模型,Bidding策略,yield optimization(也许可以叫排期优化),智能预算控制
- 推荐系统:CTR模型及其他推荐模型,探索与利用(exploration & exploitation),冷启动问题,数据有偏问题
当然,具体的技术问题这里肯定会有遗漏,但大家肯定也能感觉出来计算广告问题涉及的方向更广、需要各模块相互配合,协调;
而推荐系统则涉及的问题更细,需要把所有技术都糅合在最终的推荐列表中,但要同时照顾多方面的体验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号