翻译"Deep ANC: A deep learning approach to active noise control"
Deep ANC:主动噪声控制的深度学习方法
原论文地址:Deep ANC: A deep learning approach to active noise control
引文:[1] Hao Z A , Dlwa B . Deep ANC: A deep learning approach to active noise control[J]. Neural Networks, 2021, 141:1-10.
摘要
传统的主动噪声控制(ANC)方法是以最小均方算法为基础的自适应信号处理,主要用于线性系统,但是在存在非线性失真的情况下表现不佳。在本文中,我们将 ANC 表述为一个监督学习问题,并提出了一种称为深度 ANC 的深度学习方法来解决非线性 ANC 问题。主要思想是利用深度学习对不同噪声和环境对应的最优控制参数进行编码。训练卷积递归神经网络(CRN) ,从参考信号中估计出抵消信号的实、虚谱图 ,以便相应的反噪声可以消除或衰减 ANC 系统中的初级噪声。通过采用大规模多条件训练,实现对各种噪声的良好泛化能力和鲁棒性。无论参考信号是噪声还是含噪声的语音,都可以训练深度 ANC 方法来实现主动噪声抵消。此外,还引入了延迟补偿策略来解决 ANC 系统的潜在延时问题。实验结果表明,深度 ANC 对宽带降噪是有效的,并且可以很好地推广到未经训练的噪声。此外,所提出的方法可以在一定的安静区域内实现 ANC,并且对参考信号的变化具有鲁棒性。
关键词:主动噪声控制,深度学习,深 ANC,扬声器非线性,安静区域
1 . 引言
主动噪声控制是一种基于声信号叠加原理的噪声消除方法,即两个叠加的波形信号在振幅相同但相位相反时相互抵消。ANC 系统的目标是生成与主要噪声具有相同幅度和相反相位的抵消噪声来消除主要噪声( Goodwin, Silva, & Quevedo, 2010 )。 ANC不同于被动的噪声控制,例如使用耳塞等吸声屏障,在信号增强中通过处理含噪语音等含噪信号去除噪声( Wang & Chen, 2018)。从根本上说,ANC 需要提前预测空间中给定点的噪声信号的幅度和相位。虽然信号幅度可能会随着时间的推移保持稳定,但由于声波的性质,信号相位在任何空间位置都会一直变化( Hartmann, 2004)。因此 ANC 是一个非常具有挑战性的问题,在实践中它只能衰减低频固定噪声。
在过去的几十年中,ANC 在研究和工业应用中引起了越来越多的关注。有两种 ANC 系统:前馈和反馈 ( Hartmann, 2004 )。一个典型的前馈 ANC 系统如图1所示,它由一个参考麦克风、一个消音扬声器和一个误差麦克风组成。有源噪声控制器将参考麦克风和误差麦克风分别感测到的参考信号和误差信号作为输入,以自适应控制器,使产生的抵消信号可以与要消音的位置的初级噪声叠加。反馈 ANC 仅使用误差传感器来自适应控制器,并且更易于实施。但是,在处理宽带噪声时,它不如前馈 ANC 有效,因为反馈 ANC 不使用来自参考信号的信息。
传统上,有源噪声控制器是使用自适应滤波器实现的,该滤波器通过最小化误差信号来优化滤波器特性 (Manolakis, Ingle, Kogon, et al., 2000)。Filtered-x最小均方(FxLMS) 及其扩展是最广泛使用的有源噪声控制器,因为它们具有简单性、鲁棒性和相对较低的计算负载。如图1所示,FxLMS 算法在次级路径反馈到控制器之前对其进行估计,提前过滤参考信号x(t)来减轻次路径的影响, (Elliott, Stothers, & Nelson, 1987) 。次路径通常作为有限脉冲响应滤波器(FIR) 预先单独估计。然而, 由于放大器和扬声器等电子设备的性能有限,非线性失真不可避免地被引入到 ANC 应用中的抵消噪声中。在存在非线性的情况下,线性自适应算法无法准确识别次要路径。因此,不准确估计的次要路径会降低整体噪声消除性能。 Costa, Bermudez, and Bershad (2002) 对次级路径包含非线性元件时的 FxLMS 行为进行统计分析,并得出即使小的非线性会对自适应滤波器的行为产生重大影响。

文献中已经提出了许多自适应非线性 ANC 算法来解决非线性失真 (Das and Panda, 2004, Ghasemi et al., 2016, Kuo and Wu, 2005, Lashkari, 2006, Napoli and Piroddi, 2009, Tan and Jiang, 2001, Tobias and Seara, 2005) 。Volterra 展开式已被证明对较弱的非线性建模是有效的 (Lashkari, 2006) ,并且已经提出了基于截断二阶 Volterra 滤波器的 FxLMS 算法用于在存在非线性失真的情况下的前馈主动噪声控制 (Guo et al., 2018, Tan and Jiang, 2001)。 Napoli and Piroddi (2009) 利用具有外生变量(NARX)的多项式非线性自回归模型来识别控制器结构,以实现更高效和可靠的非线性 ANC。非线性 FxLMS 和基于切向双曲函数的 FxLMS (THF-FxLMS)算法,通过将次级路径建模为饱和型非线性来处理 ANC 系统的非线性 (Ghasemi et al., 2016) 。其他算法如双线性 FxLMS (Kuo & Wu, 2005)、filtered-s LMS (Das & Panda, 2004)、leaky FxLMS (Tobias & Seara, 2005) 也已被研究以解决非线性问题。然而,在存在强非线性的情况下,它们的性能受到限制。
考虑到神经网络处理非线性关系的能力,神经网络已经被引入来解决非线性 ANC (George & Panda, 2013) 。 Snyder and Tanaka (1995) 引入了多层感知器 (MLP) 网络, 用于主动控制振动,其中神经网络的权重通过使用自适应滤波- x反向传播进行更新。在 Snyder and Tanaka (1995), 给出的非线性主动控制结构的基础上, 又开发了改进的训练算法以提高收敛速度并减少训练的计算量 (Bouchard et al., 1999, Chang and Luoh, 2007). Krukowicz (2010) 。 Krukowicz (2010) 和 Panda and Das (2003) 使用基于功能链接神经网络的高效 ANC 结构来解决 ANC 中的非线性效应。其他的非线性自适应模型,例如径向基函数网络 (Tokhi & Wood, 1997) 、模糊神经网络 (Zhang, Gan, & Zhou, 2006) 和循环神经网络 (Bambang, 2008) ,进一步提高了 ANC 性能。这些用于非线性 ANC 的神经网络架构利用在线自适应或训练来获得最佳控制器参数,因此应被视为自适应算法>。
深度学习能够对复杂的非线性关系进行建模,并可能在解决非线性 ANC 问题中发挥重要作用。为了适用于实际应用,ANC 系统必须能够衰减各种噪声并应对声学环境的变化。传统的 ANC 系统是自适应的,通过适当调整的参数来处理这些变化。对于基于深度学习的监督式 ANC,需要进行大规模的多条件训练,以便在训练期间将 ANC 暴露在各种噪声和变化中。以这种方式训练的深度学习模型可能会推广到未经训练的噪声和环境。
在本文中,我们提出了一种新的方法来解决 ANC,特别是非线性 ANC 问题。我们的方法称为深度 ANC,采用经过训练的深度学习模型来编码对应于不同噪声源的最佳控制参数。考虑到 ANC 本质上对抵消噪声的幅度和相位都很敏感,我们使用复杂的频谱映射来同时估计 ANC 输出的幅度和相位响应 (Fu et al., 2017, Tan and Wang, 2019b, Williamson et al., 2016) 。在训练期间,训练一个CRN 网络 (Tan & Wang, 2019a) 通过参考信号来估计真实和假想的抵消信号的频谱图。随后的抵消噪声是通过将抵消信号通过扬声器和辅助路径来获得的(参见图 1)。最后,误差信号用于计算训练CRN网络模型的损失函数。据我们所知,这项研究是首次尝试将 ANC 表述为监督学习问题并使用深度学习来解决它。
从方法论的角度来看,深度 ANC 可能比传统的 ANC 算法更有优势。除了衰减噪声信号外,还可以训练深度 ANC 来衰减嘈杂语音信号的噪声分量,并让底层语音信号通过。也就是说, 深ANC原则上可以通过选择性地抑制噪声信号中的噪声成分来保持嵌入在噪声中的目标信号 ;目标信号不一定是语音,也可以是其他种类的,比如音乐。这一优势可以极大地扩大 ANC 的适用范围。此外,我们引入了延迟补偿训练策略来解决频域 ANC 算法的缺点:处理延迟。
除了在给定位置点的 ANC,更有用但更具挑战性的任务是在一个小的空间区域内执行 ANC,即生成一个安静区域。 深度ANC方法可以用RIR (房间脉冲响应)独立的方式进行训练,生成这样的安静区。。
该研究的初步版本最近发表 (Zhang & Wang, 2020) 。与会议版本相比,本文提供了更广泛的评估范围,具有更多的噪声、信噪比 (SNR) 和未经训练的语音。 此外,本文还研究了深度ANC在参考信号变化时的鲁棒性,并与其他非线性ANC方法进行了比较 。
本文的其余部分安排如下。第 2节介绍了有源噪声控制的信号模型。第 3节介绍了深度 ANC 方法。评估指标和实验设置在第 4节。第 5节显示了评估结果和比较。第 6节总结了本文。
2 . 主动噪声控制
2.1 . 信号模型
如图1所示,主路径和次路径分别对应于从参考麦克风或抵消扬声器分别到误差麦克风的声学响应,它们的频率响应表示为P(z)和S(z)。参考信号X(t)由参考麦克风拾取并通过有源噪声控制器以获得抵消信号y(t)。抵消信号通过抵消扬声器和辅助路径产生抵消噪声a(t)。 误差麦克风感应到的相应误差信号定义为
其中t是时间指数,d(t)是误差麦克风接收到的主路径信号,w(t)表示有源噪声控制器,fLS{⋅}表示扬声器的作用,∗表示线性卷积,上标T表示转置。此外,p(t)和s(t)分别表示主要和次要路径的脉冲响应。
主动噪声控制旨在产生抵消噪声以消除初级噪声。传统上, 这是通过使用自适应算法对数字滤波器W(z)进行估计,使均方误差最小来完成的。FxLMS算法及其变体通过首先估计次级路径,然后放置估计的\(\widehat{S} (z)\)滤波器来补偿次级路径的影响。辅助路径通常在 ANC 应用的初始阶段使用离线估计,传统ANC 方法的性能很大程度上取决于\(\widehat{S} (z)\)的估计精度。
2.2 . 用于主动噪声控制的深度学习
忽略扬声器的作用,公式(1)的z变换可以写成
假设在自适应滤波器收敛后残差完全衰减,则自适应滤波器的最优解可以表示为如下传递函数
这意味着 ANC 系统必须建模P(z)和S(z)的逆才能达到最佳降噪性能 (Kuo & Morgan, 1999) 。然而,S(z)的逆不一定存在,对于传统的自适应算法来说直接估计滤波器W(z)可能很复杂,更不用说扬声器引入的非线性失真了。
与需要单独估计次级路径和自适应滤波器的传统 ANC 方法不同,深度 ANC 使用监督学习并训练深度神经网络来直接逼近最优控制器\(W^0(z)\)以尽量减少不同情况下的误差信号。深度 ANC 的示意图如图 2 所示。总体目标是从参考信号中估计一个抵消信号,以便产生相应的抵消噪声消除主噪声。在所提出的方法中,我们使用参考信号作为输入,并将理想的抵消噪声设置为训练目标。为了实现完全的噪声消除,理想的抵消噪声应该与初级噪声相同。在训练过程中,深度 ANC 的输出被视为“中间产品”,通过扬声器和辅助路径传递深度 ANC 输出来生成抵消噪声估计。损失函数是根据误差信号计算的。

将 ANC 表述为监督学习问题并非易事。这种表述存在两个概念障碍。首先,定义深度神经网络 (DNN) 的训练目标并不简单。尽管用于衰减初级噪声的理想消除信号是已知的,但由于扬声器和次级路径的存在,它不能直接用作 DNN 的所需输出(见图2)。其次,主要路径和次要路径可能随时间变化,并且 DNN 需要近似的传递函数对于不同的声学条件可能不同。这似乎意味着监督学习模型需要预测一对多映射,这是一项不可能完成的工作。这些障碍可以解释为什么没有从深度学习的角度来处理 ANC。然而,正如下一节中所详述的,我们可以使用理想的抵消噪声来监督 DNN 训练,并且可以训练 DNN 来估计给定输入的不同场景下不同输出的一些平均值。通过这些观察,ANC 可以被表述为一项深度学习任务。
3 . 深度 ANC 方法
3.1 . 特征提取和训练目标
参考信号x(t)以16 kHz 的频率进行采样,并分为 20 毫秒的帧,相邻连续帧之间有 10 毫秒的重叠。 然后对每一个时间帧进行320点短时傅里叶变换( STFT ),产生x (t)的实、虚谱图,在时间m和频率c的一个T-F单元内分别记为Xr ( m , c )和Xi ( m , c )。为深度 ANC提出的CRN神经网络如图 3所示,它需要Xr ( m , c )和Xi ( m , c )作为复杂频谱映射的输入特征。

为了衰减误差麦克风位置的主要噪声,深度 ANC 使用理想的抵消噪声(主要噪声)作为训练目标。CRN 网络被训练为从参考信号的实部和虚部频谱图映射到抵消信号的频谱图Yr(m, c)和Yi (m, c). 这与仅估计幅度谱图和使用输入信号的相位谱图生成估计波形输出的方法不同。我们选择复杂的频谱映射是因为相位在有源噪声控制中的重要性。抵消信号的复频谱图经过傅里叶逆变换得到波形信号 y(t). 然后通过将消除信号通过扬声器和辅助路径来生成可以被视为训练目标的估计的抵消噪声。
3.2 . 两种训练策略和损失函数
在实际应用中,ANC 应用可能需要处理参考信号是嘈杂语音的情况。以降噪耳机为例,当有人在用户附近说话时,耳机上的参考麦克风可能会拾取语音。在这种情况下,参考信号是语音和初级噪声的混合。在这种情况下,ANC 应该理想地允许语音信号通过,同时抑制主要噪声。
通过使用适当的训练数据和损失函数,无论参考信号是噪声还是嘈杂的语音,都可以训练深度 ANC 以实现噪声消除。图 4显示了深度ANC 方法的两种训练策略:

-
使用噪音训练ANC:训练这种模型是为了抵消参考麦克风接收到的噪音。为此,我们采用噪声信号n(t)作为参考信号,训练深度ANC以完全消除主噪声。损失函数定义为:
\[L_n=\frac{\sum_{t=1}^{L}e^2(t)}{L}\tag{4} \] -
使用嘈杂语音训练的深度 ANC :这时深度ANC模型在保留语音信号的同时,可以抵消周围的噪声。训练该深度ANC系统的参考信号是噪声n(t)和语音v(t)的混合信号,对应的主噪声信号d(t)为
\[\begin{aligned} d(t) &=p(t) *[v(t)+n(t)] \\ &=p(t) * v(t)+p(t) * n(t) \end{aligned}\tag{5} \]
其中p(t) * n(t)和p(t) * v(t)分别是主噪声信号的噪声和语音成分。为了只衰减噪声分量,让语音通过,将训练目标设置为噪声分量p(t) * n(t),此时理想的误差信号等价于p(t) * v(t)。用于训练这种深度ANC系统的损失函数定义为:
3.3 . 学习机
Deep ANC 使用 CRN 网络进行复杂的频谱映射 (Tan & Wang, 2019a) 。除了先前的用于复杂的频谱映射和强大的语音增强性能外,CRN 还表现出更高的参数效率并适用于实时处理。CRN 具有编码器-解码器结果,如图3所示,其中编码器和解码器分别包括五个卷积层和五个反卷积层。它们之间是两个具有组策略的循环LSTM(长期短期记忆)层 (Gao et al., 2018) ,其中组数设置为2. 编码器-解码器结构以对称方式设计,其中内核的数量在编码器中逐渐增加,在解码器中逐渐减少。为了聚合前后频谱,在所有卷积层和反卷积层中沿频率维度采用 步长为2。因此,特征映射的频率维度在编码器中逐层减半,在解码器中逐层加倍,以确保输出与输入具有相同的形状。在 CRN网络中使用跳跃连接,以便每个编码器层的输出连接到相应解码器层的输入。在 CRN 网络中,所有的卷积和反卷积是因果关系,因此系统不使用未来信息,因此适合实时运行。 Tan and Wang (2019a) 中提供了 CRN 结构的详细描述。
我们在除输出层外的所有卷积和反卷积层中使用指数线性单元 (ELUs) (Clevert, Unterthiner, & Hochreiter, 2015) ,其中线性激活用于频谱图估计。此外,我们在每次卷积或反卷积后和激活之前使用批处理归一化 (Ioffe & Szegedy, 2015) 。该模型使用 AMSGrad 优化器 (Reddi, Kale, & Kumar, 2019) 进行训练,学习率为 0.001,历时 30 次。
3.4 . 延迟补偿训练
提出的方法使用实部和虚部频谱图作为输入和输出,因此可以将其视为频域 ANC 算法。然而,频域 ANC 算法产生的时间延迟等于 STFT 的帧长度( (Yang, Cao, Wu, Albu, & Yang, 2018) 。这种延迟可能违反 ANC 的因果约束关系,这被认为是频域 ANC 算法的一个缺点。 为了减少这种延迟,人们提出了许多方法,这些方法并不容易被完全消除 (Bendel et al., 2001, Kim et al., 1994, Kuo et al., 2008, Park et al., 2001, Rout et al., 2015) 。
为了解决这个延迟问题,我们为深度 ANC 提出了一种延迟补偿的训练策略。主要思想是训练模型提前几帧预测抵消信号。该策略的示意图如图 5所示,其中N表示输入信号中的总帧数,M表示预测帧的数量。具体来说,输入信号在开始时首先通过填充M帧为0进行扩展。然后利用扩展输入的前N帧作为新的输入信号对模型进行训练。新的输入是M帧的零点和原输入的前N-M帧的集合,而目标信号保持不变,因此相当于利用输入信号提前预测目标的M帧。采用20 ms帧和10 ms帧移位,延时补偿训练节省10×M ms用于主动噪声控制。因此,这种策略原则上可以解决频域ANC系统的时延问题。

4 . 实验装置
4.1 . 性能指标
所提出方法的性能使用归一化均方误差(NMSE)、 可短时客观可懂 (STOI) (Taal, Hendriks, Heusdens, & Jensen, 2011) 和语音质量感知评估(PESQ) (Rix, Beerends, Hollier, & Hekstra, 2001) 对所提出方法的性能进行了评估。
ANC 系统中误差信号的功率通常用作噪声衰减的质量度量 。在本文中,我们使用以 dB 为单位的 NMSE 来衡量 ANC 系统的性能:
其中L是信号的长度。NMSE 的值通常低于零,值越低表示噪声衰减越好。
当参考信号是含噪语音时,STOI 和 PESQ 分别用于测量在误差麦克风处接收到的去噪语音的可懂度和质量。它们是通过比较误差信号和语音分量p(t)*v(t)得到的. STOI分数的范围通常是从 0 到 1。PESQ 分数的范围是从−0.5到 4.5,分数越高越好。
4.2 . 实验设置
为了训练一个与噪声无关的模型,我们在训练阶段将 ANC 模型暴露在各种噪声环境中 (Chen, Wang, Yoho, Wang, & Healy, 2016) 并使用 从音效库 ( http://www.sound-ideas.com )得到的10 000 个非语音环境声音(噪声)创建训练集。来自 NOISEX-92 (Varga & Steeneken, 1993) 的发动机噪声、工厂噪声、咿呀声和语音型噪声(表示为SSN)用于测试。请注意,在训练阶段并不使用测试噪声,因此评估了所提出方法的泛化能力。
ANC 系统的物理结构通常被建模为矩形封闭空间 (Kestell, 2000, Tarabini and Roure, 2008),许多研究表明 ANC 系统在封闭房间内消除噪音方面的有效性 (Cheer, 2012, Samarasinghe et al., 2016, Sommerfeldt et al., 1995) 。在这项研究中,我们模拟了一个大小为 3 m×4m×2m(宽度×长度×高度) 的矩形封闭空间,并利用图像法 (Allen & Berkley, 1979) 为ANC 系统生成房间的主要和次要路径脉冲响应。采用一个典型的场景,参考麦克风位于 (1.5, 1, 1) m 处,抵消扬声器位于 (1.5, 2.5, 1) m 处,误差麦克风位于 (1.5, 3, 1) m 处,主路径噪声源远离墙壁以便于拾取噪声 (Allen & Berkley, 1979) 。训练时,使用五种不同的混响时间(T60s):0.15 s、0.175 s、0.2 s、0.225 s和0.25 s用于生成RIR,RIR的长度均设置为512。 每个T60时间生成两个RIR ,一个用于主路径,另一个用于辅助路径。对于测试,我们使用混响时间为 0.2 s 的 RIR 作为默认测试 RIR,并且使用未经训练的 T60 生成的 RIR 用于测试深度 ANC 的泛化能力。
扬声器产生的饱和效应是 ANC 系统中最重要的非线性来源 (Costa et al., 2002, Ghasemi et al., 2016) 。在扬声器饱和度的 ANC 研究中 (Agerkvist, 2007, Bershad, 1990, Klippel, 2006, Tobias and Seara, 2006),这种非线性通常由尺度误差函数 (SEF) 来表示 (Tobias & Seara, 2006) :
其中y扬声器的输入(见图1),\(\eta^2\)表示非线性的强度。它模拟常见的饱和非线性类型,例如受扬声器尺寸限制的声级饱和度。 SEF随着\(\eta^2\)趋于无穷大而变成线性,随着\(\eta^2\)趋于零而变成硬限制器。为了考察所提方法对非线性失真的鲁棒性,在训练阶段采用4个扬声器函数:\(\eta^2\) = 0.1 (严重非线性),\(\eta^2\) = 1 (中度非线性),\(\eta^2\) = 10 (轻微非线性),\(\eta^2\) =\(\infty\)(线性)。图6绘出了\(\eta^2\)值的SEF。为了测试,我们同时使用训练和未训练的扬声器功能。

训练深度 ANC 以处理参考信号为噪声或含噪语音的情况。为此,我们为每种情况生成 20 000 个训练信号和 100 个测试信号。每个噪声信号都是通过从 10 000 个噪声信号中随机切割一个 6 秒的信号而创建的。 用于产生带噪语音的语音信号是从TIMIT数据集 (Lamel, Kassel, & Seneff, 1989) 中随机选取200个说话人( 100名男性发言者和 100名女性发言者 )得到 。每个说话者在 TIMIT 语料库中有 10 个话语,其中 7 个用于训练,其余 3 个用于测试。为了产生一个含噪语音信号,将一个随机选择的说话人的语音与从10 000个噪声中截取的随机噪声以[ 5、10、15、20] dB随机选择信噪比进行混合。主信号d(t)是由参考信号与主路径随机选择的RIR卷积生成的。抵消噪声a(t)是通过随机选择的扬声器函数和随机选择的二次路径RIR依次传递相应的抵消信号y(t)产生的。在下面的实验中,我们用CRN-n和CRN-ns分别表示用噪声和含噪语音训练的深度ANC模型。
4.3 . 比较方法
深度ANC 方法在线性和非线性情况下与FxLMS算法和 THF-FxLMS算法 进行了比较。FxLMS 的工作原理是根据 FIR 滤波器对次级路径进行建模,并利用估计的模型来调整滤波器系数以适应 ANC 控制器。当辅助路径是线性系统时,FxLMS 实现了良好的噪声衰减。然而,当系统中存在非线性失真时,它无法准确识别次级路径。次要路径的非线性模型用于有源噪声控制以解决非线性失真。THF-FxLMS 是最近提出的非线性 ANC 算法 (Ghasemi et al., 2016) 。它引入了双曲正切函数(THF) 对扬声器的饱和效应进行建模,然后将估计的非线性程度应用到 ANC 控制器的设计中。如 Ghasemi et al. (2016) 所示,在非线性失真情况下,THF-FxLMS 在噪声衰减方面优于 FxLMS 和二阶 Volterra 算法。
FxLMS 和 THF-FxLMS 都是自适应算法,可用于消除不同类型的噪声。然而,它们的性能对诸如步长和滤波器长度等控制参数很敏感。当暴露在不同的噪音和环境中时,需要适当的步长来实现良好的性能。我们实验中的 FxLMS 和 THF-FxLMS 的步长是根据 Chen and Zhang (2011) 以及 Huang and Xu (2012) 给出的标准针对不同的噪声进行启发式选择的,以确保稳定的更新和良好的噪声衰减。比较方法的滤波器长度设置为512,等于主路径和次路径的长度。
此外,我们在第 5.5节中考虑了另一种非线性 ANC 设置,其中将深度 ANC 与基于 Volterra 滤波器的算法和基于MLP的方法进行了比较。
5 . 评估结果和比较
5.1 . 用噪声训练的深度 ANC 的性能
我们首先对用噪声训练的深度ANC模型的性能进行评估。在一个线性系统( \(\eta^2=\infty\))和两个非线性系统( $\eta^2 $= 0.5 , $\eta^2 $ = 0.1 )中分别用4种未训练噪声对本文方法和传统ANC算法进行了测试。 表 1显示了 100 个测试信号的平均NMSE,其中 CRN-n(-1) 和 CRN-n(-2) 表示使用延迟补偿策略训练的模型去提前预测1或2帧。对于发动机噪声、工厂噪声、babble噪声和SSN这四种噪声,更新FxLMS的步长分别设定为0.05、0.4、0.3、0.4,更新THF-FxLMS的步长分别设定为0.05、0.4、0.3、0.4。从该表中可以明显看出,FxLMS 能够衰减不同的噪声,但在涉及非线性 ANC 时其性能会下降。THF-FxLMS 将次级路径建模为非线性系统,并且在不同的非线性情况下实现了良好的噪声衰减。深度 ANC 模型在线性和非线性情况下都优于对比的算法,并且可以很好地推广到未经训练的噪声和未经训练的非线性系统($\eta^2=0.$5)。正如预期的那样,CRN-n 在深度 ANC 模型中表现最好。使用延迟补偿策略提前预测一帧到两帧仍然可以获得良好的噪声衰减水平,高于 FxLMS 和 THF-FxLMS算法,而整体性能随着预测长度的增加会逐渐下降。
在图7中绘制了NMSE和功率谱曲线,进行了进一步的比较。功率谱测量信号相对于频率的功率,这里用来表示在不同频率下实现的相对噪声衰减。图中的结果是在发动机噪声和非线性\(\eta^2\) = 0.1的情况下得到的。可以看出,深度ANC方法始终优于比较方法。 由图7 (b)可知,该方法实现了宽带降噪,而对比方法仅对低频段的噪声衰减有效。众所周知,传统的ANC算法由于收敛和延迟等因素的限制,仅在低频效果明显 (Kuo and Morgan, 1999, Samarasinghe et al., 2016) ,因此,通常只采用窄带噪声或低通滤波噪声作为输入。而深度ANC对低频噪声和高频噪声都是有效的。需要注意的是,本研究使用的测试噪声是宽带的,这也是表1中对比方法的降噪量低于已有文献结果的部分原因。

图 8给出了使用不同 T60 值生成的 RIR 进行测试时深度 ANC 的平均 NMSE。它表明深度 ANC 的降噪性能可以很好地推广到未经训练的 RIR。

5.2 . 用嘈杂语音训练的深度 ANC 的性能
本小节评估参考信号为带噪语音时深度 ANC 的性能。表 2给出了不同算法在不同信噪比水平的噪声和嘈杂语音情况下的比较结果,其中 CRN-ns(-1) 和 CRN-ns(-2) 表示使用延迟补偿策略训练的模型去提前预测1或2帧。在 SNR 为 5、15 和 20 dB三个级别的发动机噪声下, FxLMS 算法的更新步长分别设置为 0.01、0.05、0.01, THF-FxLMS 算法的更新步长分别设置为 0.01、0.01、0.01 。 本表给出的结果是用发动机噪声和一个\(\eta^2\)= 0.1的非线性系统得到的 。"Unprocessed"表示没有ANC的结果, 通过比较主通路信号d(t)与底层语音成分得到unprocessed信号的STOI和PESQ值。表 2中的第二列显示了使用噪声信号测试时的 NMSE 值。可以看出,在仅噪声情况下进行测试时,CRN-ns 的性能与 CRN-n 的性能相当,即使前者的模型是用嘈杂的语音训练的。对于含噪语音的情况,由于语音是信噪比为正的含噪语音中的主要成分,因此总体性能在NMSE方面有所下降。CRN-n模型仍然具有最好的性能,所有信噪比下的NMSE值均低于-8.6dB。也就是说,CRN-n 模型将含噪语音视为“一般噪声”,它能够衰减噪声以及含噪的语音。用含噪语音训练的 CRN-ns 模型旨在去除含噪语音中的噪声分量,误差信号相对应于干净语音的估计。我们使用STOI和PESQ来评估保留语音成分的性能。如表所示,CRN-ns由于具有选择性衰减噪声的能力,提高了客观可懂度和语音质量。例如,在信噪比为5dB的情况下,STOI改善约为0.05、PESQ的提高约为0.3。CRN-ns ( -1 )和CRN-ns ( -2 )的性能与CRN-ns相当,PESQ略有下降。传统的方法和CRN-n侧重于最小化误差信号(衰减参考信号),因此会使语音成分失真,表现为STOI和PESQ值比未处理的含噪语音低很多。
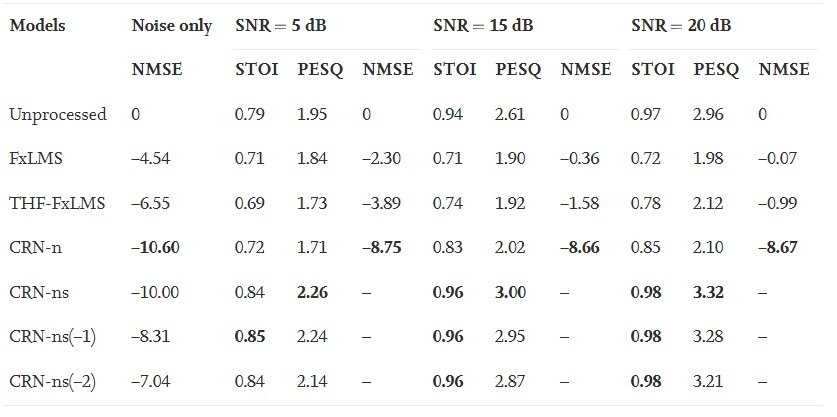
将深度ANC方法在5 d B信噪比下分别用工厂噪声、babble噪声和SSN语音下进行测试,以显示其对不同噪声的鲁棒性。为了清楚地显示STOI和PESQ的改进,我们定义ΔSTOI和ΔPESQ表示ANC引入的这些度量的差异。图 9绘制了这些值和NMSE值。可以看出FxLMS、THF-FxLMS 和 CRN-n 的 ΔSTOI和ΔPESQ值均低于零。用带噪语音训练的模型(CRN-ns、CRN-ns(-1) 和 CRN-ns(-2))很好地泛化到未经训练的噪声,并且能够选择性地衰减带噪语音的噪声分量,从而提高客观语音可懂度和质量。

非线性度η 2 = 0.1的CRN - ns的波形和谱图如图10所示,其中第一行显示了发动机噪声测试结果,第二行显示了噪声语音在5 dB信噪比下测试结果。不言而喻,用含噪语音训练的深层ANC系统(CRN-ns)不仅可以衰减含噪语音中的噪声成分,而且在参考信号中没有语音时也可以抵消噪声。

5.3 . 安静区域
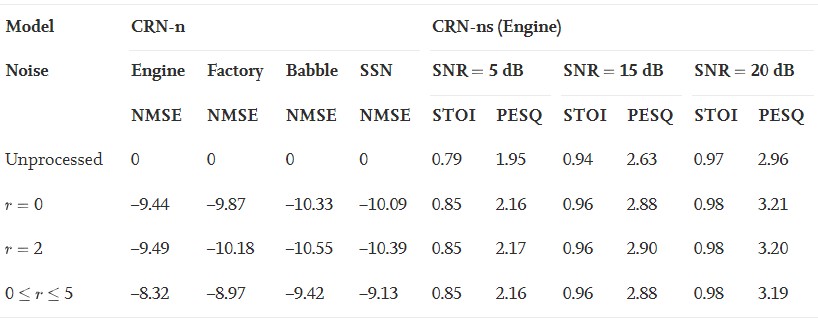
迄今为止,我们主要关注空间给定点处的噪声衰减。一个更具挑战性和可取性的任务将是在一个小的空间区域内实现主动噪声控制,称为安静区 (Kuo et al., 2004, Zhu et al., 2020) 。为了实现一个安静区,在训练过程中,通过将模型暴露在一个小区域内的各种RIR中,深度ANC可以以单独的RIR方式进行训练。具体来说,我们将安静区模拟为半径为5厘米的球体,如车内司机大约一只耳朵的区域。我们在球面内随机选取100个点作为误差传声器的位置,利用图像法 (Allen & Berkley, 1979) 生成100对主、次路径的RIR。在每个情况下用这100对RIR分别针对纯噪声和含噪语音创建2万个训练信号,并用这些数据训练CRN-n和CRN-ns模型。生成三个测试集,每个测试集包含100个信号,用于评估这些模型的性能。
结果如表3所示,其中r表示距离区域中心的距离。对于 r=0 的情况,通过将误差麦克风放置在球心产生测试信号。对于 r = 2,测试集是通过将麦克风放置在距离中心点2厘米的球面内生成的。对于 0≤r≤5,我们将误差麦克风随机放置在球内的10 个不同点上,并使用相应的 10 对 RIR 来创建测试集。CRN-n模型对球内有发动机噪声的带噪语音产生8.32 dB的NMSE。CRN-ns模型对球内5dB信噪比的发动机噪声STOI和PESQ分别得到0.06和0.21的改善。表3中的其他测试条件也观察到类似的NMSE、STOI和PESQ改进量。一般来说,用这种方法训练的深层ANC模型在保持语音的同时,在该范围内的任一点都能实现大幅度的噪声衰减,从而产生一个安静区。
5.4 . 深度 ANC 的稳健性
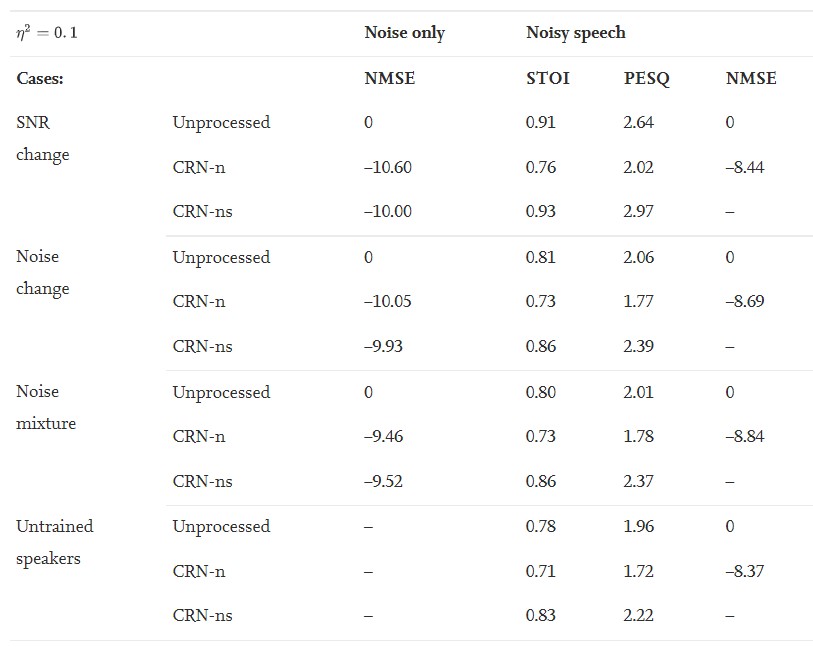
在ANC应用中,参考信号会发生很多变化,如信噪比、噪声类型以及参考信号中同时存在多个噪声。为了检验所提算法对这些变化的鲁棒性,我们分别在4种情况下对第5.1节和5.2节训练的模型进行评估。首先,参考信号在3 s后,含发动机噪声参考信号的信噪比从5 dB变化到20 dB。其次,参考信号的噪声类型在3 s后由发动机噪声变为工厂噪声。第三,参考信号是发动机噪声和工厂噪声的混合信号。第2种和第3种情况的信噪比水平设置为5dB。第四,我们从TIMIT数据集中随机选取20个未受过训练的说话人(10男 10女),并创建100个测试信号( 5dB的信噪比发动机噪声)来评估深度ANC在未受过训练说话人条件下的性能。结果见表4。以含噪语音为参考信号得到‘含噪语音’的结果,以含噪语音的噪声分量为参考信号得到‘只有噪声’结果。本表所示结果证明了深度ANC方法的强鲁棒性。
5.5 . 使用不同的非线性 ANC 设置进行比较
我们在本节中考虑不同的非线性ANC设置,并将深度ANC算法的性能与基于Volterra滤波器的算法和基于神经网络的算法进行了比较。实验按照 Guo et al. (2018) 和Zhou and DeBrunner (2007) 进行设置。
主路径采用Volterra级数建模,主噪声d (t)与参考信号x(t)的关系定义为 (Guo et al., 2018, Zhou and DeBrunner, 2007)
次级路径建模为 Zhou and DeBrunner (2007) 介绍的非线性-线性( NL )结构。在NL结构中,抵消信号y ( t )依次通过一个非线性模型(记为N )和一个z域的FIR滤波器(记为l(z)得到抵消噪声a(t)。
我们利用FxLMS结构( VFxLMS )实现了自适应Volterra控制器, Guo et al. (2018)和Tan and Jiang (2001) 。采用二阶Volterra滤波器对VFxLMS算法的有源噪声控制器和次级路径进行建模,其内存大小为10,步长设置为如 Guo et al. (2018) 所给出的。
基于神经网络的非线性ANC方法是对FxLMS算法的扩展,是将控制器建模为MLP (Chang and Luoh, 2007, Zhou et al., 2005) 。这种方法可以表示为FxMLP,其利用梯度下降 (Chang & Luoh, 2007) 自适应更新MLP的权值。MLP有6个输入,2个隐含层,每层12个神经元,输出层1个神经元。隐层激活函数为Sigmoid函数,最后一层为线性函数。
对于深度ANC,我们从10 000个噪声中再产生20 000个训练信号,重新训练CRN-n模型。这些训练信号是按照4.2节的描述产生的,除主路径和次路径被(9)、(10)、(11)所述路径所代替。
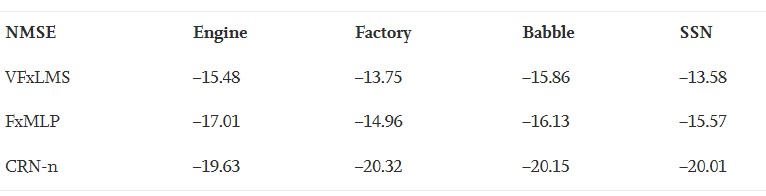
CRN-n、VFxLMS和FxMLP分别针对之前使用的4种噪声进行评估,每种工况产生100个噪声信号。比较结果见表5。可以看出,所有这些方法都能有效地抑制非线性ANC系统的噪声,并且深度ANC系统始终优于其他两种方法。
6 . 结论
在本文中,我们介绍了用于主动噪声控制的深度 ANC 方法。采用卷积循环网络从参考信号中估计抵消信号,从而去除或衰减初级噪声。使用适当的训练数据和损失函数,可以训练深度 ANC 系统不仅可以消除噪声,还可以选择性地消除嘈杂语音中的噪声分量。我们还提出了一种时延补偿的训练策略来解决频域ANC方法的时延问题。此外,该方法能够在空间区域内实现ANC。通过NMSE、STOI和PESQ的系统评价,证明了深度ANC模型在仅含噪声和含噪语音情况下对噪声衰减的有效性和鲁棒性,该模型对不同的语音变化具有良好的泛化能力。
深度ANC方法比传统方法具有重大优势。它具有实现在ANC系统中不可回避的非线性建模的内在能力。深度ANC在训练目标方面是灵活的,例如,它可以在有噪声的语音甚至有噪声的音乐中实现噪声抵消。使用单个抵消扬声器可以产生安静区,而自适应滤波方法需要多个扬声器。与传统方法不同,深度ANC对宽带噪声的去除是有效的。最后,延迟补偿策略除了解决频域算法中的延迟困难外,显著扩大了ANC中因果关系的范围。
未来的工作包括探索深度ANC的时域方法,评估深度ANC对误差麦克风位置变化引起的RIR变化的鲁棒性,以及将深度ANC扩展到多通道版本。此外,在今后的研究中将考虑诸如计算复杂度和设备实现等实际问题。
References
-
Agerkvist F.Modelling loudspeaker non-linearitiesAudio engineering society conference: 32nd international conference: dsp for loudspeakers (2007)[Google Scholar](https://scholar.google.com/scholar_lookup?title=Modelling loudspeaker non-linearities&publication_year=2007&author=F. Agerkvist)
-
Allen J.B., Berkley D.A.Image method for efficiently simulating small-room acousticsJournal of the Acoustical Society of America, 65 (1979), pp. 943-950[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Image method for efficiently simulating small-room acoustics&publication_year=1979&author=J.B. Allen&author=D.A. Berkley)
-
Bambang R.T.Adjoint EKF learning in recurrent neural networks for nonlinear active noise controlApplied Soft Computing, 8 (2008), pp. 1498-1504ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Adjoint EKF learning in recurrent neural networks for nonlinear active noise control&publication_year=2008&author=R.T. Bambang)
-
Bendel Y., Burshtein D., Shalvi O., Weinstein E.Delayless frequency domain acoustic echo cancellationIEEE Transactions on Speech and Audio Processing, 9 (2001), pp. 589-597View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Delayless frequency domain acoustic echo cancellation&publication_year=2001&author=Y. Bendel&author=D. Burshtein&author=O. Shalvi&author=E. Weinstein)
-
Bershad N.J.On weight update saturation nonlinearities in LMS adaptationIEEE Transactions on Acoustics, Speech and Signal Processing, 38 (4) (1990), pp. 623-630View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=On weight update saturation nonlinearities in LMS adaptation&publication_year=1990&author=N.J. Bershad)
-
Bouchard M., Paillard B., Le Dinh C.T.Improved training of neural networks for the nonlinear active control of sound and vibrationIEEE Transactions on Neural Networks, 10 (1999), pp. 391-401View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Improved training of neural networks for the nonlinear active control of sound and vibration&publication_year=1999&author=M. Bouchard&author=B. Paillard&author=C.T. Le Dinh)
-
Chang C.Y., Luoh F.B.Enhancement of active noise control using neural-based filtered-x algorithmJournal of Sound and Vibration, 305 (2007), pp. 348-356ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Enhancement of active noise control using neural-based filtered-x algorithm&publication_year=2007&author=C.Y. Chang&author=F.B. Luoh)
-
Cheer J.Active control of the acoustic environment in an automobile cabin(Ph.D. thesis)University of Southampton (2012)[Google Scholar](https://scholar.google.com/scholar_lookup?title=Active control of the acoustic environment in an automobile cabin&publication_year=2012&author=J. Cheer)
-
Chen J., Wang Y., Yoho S.E., Wang D.L., Healy E.W.Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noisesJournal of the Acoustical Society of America, 139 (2016), pp. 2604-2612[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises&publication_year=2016&author=J. Chen&author=Y. Wang&author=S.E. Yoho&author=D.L. Wang&author=E.W. Healy)
-
Chen W., Zhang Z.Nonlinear adaptive learning control for unknown time-varying parameters and unknown time-varying delaysAsian Journal of Control, 13 (2011), pp. 903-913[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Nonlinear adaptive learning control for unknown time-varying parameters and unknown time-varying delays&publication_year=2011&author=W. Chen&author=Z. Zhang)
-
Clevert D.-A., Unterthiner T., Hochreiter S.Fast and accurate deep network learning by exponential linear units (elus)(2015)arXiv preprint arXiv:1511.07289[Google Scholar](https://scholar.google.com/scholar?q=Fast and accurate deep network learning by exponential linear units)
-
Costa M.H., Bermudez J.C.M., Bershad N.J.Stochastic analysis of the filtered-x LMS algorithm in systems with nonlinear secondary pathsIEEE Transactions on Signal Processing, 50 (2002), pp. 1327-1342View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Stochastic analysis of the filtered-x LMS algorithm in systems with nonlinear secondary paths&publication_year=2002&author=M.H. Costa&author=J.C.M. Bermudez&author=N.J. Bershad)
-
Das D.P., Panda G.Active mitigation of nonlinear noise processes using a novel filtered-s LMS algorithmIEEE Transactions on Speech and Audio Processing, 12 (2004), pp. 313-322View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Active mitigation of nonlinear noise processes using a novel filtered-s LMS algorithm&publication_year=2004&author=D.P. Das&author=G. Panda)
-
Elliott S., Stothers I., Nelson P.A multiple error LMS algorithm and its application to the active control of sound and vibrationIEEE Transactions on Acoustics, Speech and Signal Processing, 35 (1987), pp. 1423-1434View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=A multiple error LMS algorithm and its application to the active control of sound and vibration&publication_year=1987&author=S. Elliott&author=I. Stothers&author=P. Nelson)
-
Fu S.-W., Hu T.-y., Tsao Y., Lu X.Complex spectrogram enhancement by convolutional neural network with multi-metrics learningIEEE 27th international workshop on machine learning for signal processing (2017), pp. 1-6[Google Scholar](https://scholar.google.com/scholar_lookup?title=Complex spectrogram enhancement by convolutional neural network with multi-metrics learning&publication_year=2017&author=S.-W. Fu&author=T.-y. Hu&author=Y. Tsao&author=X. Lu)
-
Gao, F., Wu, L., Zhao, L., Qin, T., Cheng, X., & Liu, T.-Y. (2018). Efficient sequence learning with group recurrent networks. In Proceedings of the 2018 conference of the north american chapter of the association for computational linguistics: human language technologies (pp. 799–808).[Google Scholar]( https://scholar.google.com/scholar?q=Gao , F., Wu, L., Zhao, L., Qin, T., Cheng, X., Liu, T.-Y. . Efficient sequence learning with group recurrent networks. In Proceedings of the 2018 conference of the north american chapter of the association for computational linguistics: human language technologies .)
-
George N.V., Panda G.Advances in active noise control: A survey, with emphasis on recent nonlinear techniquesSignal Processing, 93 (2013), pp. 363-377ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Advances in active noise control%3A A survey%2C with emphasis on recent nonlinear techniques&publication_year=2013&author=N.V. George&author=G. Panda)
-
Ghasemi S., Kamil R., Marhaban M.H.Nonlinear THF-FXLMS algorithm for active noise control with loudspeaker nonlinearityAsian Journal of Control, 18 (2016), pp. 502-513[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Nonlinear THF-FXLMS algorithm for active noise control with loudspeaker nonlinearity&publication_year=2016&author=S. Ghasemi&author=R. Kamil&author=M.H. Marhaban)
-
Goodwin G.C., Silva E.I., Quevedo D.E.Analysis and design of networked control systems using the additive noise model methodologyAsian Journal of Control, 12 (2010), pp. 443-459View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Analysis and design of networked control systems using the additive noise model methodology&publication_year=2010&author=G.C. Goodwin&author=E.I. Silva&author=D.E. Quevedo)
-
Guo X., Li Y., Jiang J., Dong C., Du S., Tan L.Sparse modeling of nonlinear secondary path for nonlinear active noise controlIEEE Transactions on Instrumentation and Measurement, 67 (3) (2018), pp. 482-496[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Sparse modeling of nonlinear secondary path for nonlinear active noise control&publication_year=2018&author=X. Guo&author=Y. Li&author=J. Jiang&author=C. Dong&author=S. Du&author=L. Tan)
-
Hartmann W.M.Signals, sound, and sensationSpringer Science & Business Media (2004)[Google Scholar](https://scholar.google.com/scholar_lookup?title=Signals%2C sound%2C and sensation&publication_year=2004&author=W.M. Hartmann)
-
Huang D., Xu J.-X.Discrete-time adaptive control for nonlinear systems with periodic parameters: A lifting approachAsian Journal of Control, 14 (2012), pp. 373-383[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Discrete-time adaptive control for nonlinear systems with periodic parameters%3A A lifting approach&publication_year=2012&author=D. Huang&author=J.-X. Xu)
-
Ioffe S., Szegedy C.Batch normalization: Accelerating deep network training by reducing internal covariate shift(2015)arXiv preprint arXiv:1502.03167[Google Scholar](https://scholar.google.com/scholar_lookup?title=Batch normalization%3A Accelerating deep network training by reducing internal covariate shift&publication_year=2015&author=S. Ioffe&author=C. Szegedy)
-
Kestell C.D.Active control of sound in a small single engine aircraft cabin with virtual error sensors(Ph.D. thesis)Adelaide University (2000)[Google Scholar](https://scholar.google.com/scholar_lookup?title=Active control of sound in a small single engine aircraft cabin with virtual error sensors&publication_year=2000&author=C.D. Kestell)
-
Kim I.-S., Na H.-S., Kim K.-J., Park Y.Constraint filtered-x and filtered-u least-mean-square algorithms for the active control of noise in ductsJournal of the Acoustical Society of America, 95 (1994), pp. 3379-3389[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Constraint filtered-x and filtered-u least-mean-square algorithms for the active control of noise in ducts&publication_year=1994&author=I.-S. Kim&author=H.-S. Na&author=K.-J. Kim&author=Y. Park)
-
Klippel W.Tutorial: Loudspeaker nonlinearities—Causes, parameters, symptomsJournal of the Audio Engineering Society, 54 (2006), pp. 907-939View Record in Scopus[Google Scholar](https://scholar.google.com/scholar?q=Tutorial: Loudspeaker nonlinearitiesCauses, parameters, symptoms)
-
Krukowicz T.Active noise control algorithm based on a neural network and nonlinear input-output system identification modelArchives of Acoustics, 35 (2010), pp. 191-202View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Active noise control algorithm based on a neural network and nonlinear input-output system identification model&publication_year=2010&author=T. Krukowicz)
-
Kuo S.M., Morgan D.R.Active noise control: a tutorial reviewProceedings of the IEEE, 87 (1999), pp. 943-973View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Active noise control%3A a tutorial review&publication_year=1999&author=S.M. Kuo&author=D.R. Morgan)
-
Kuo S.M., Wu H.-T.Nonlinear adaptive bilinear filters for active noise control systemsIEEE Transactions on Circuits and Systems. I. Regular Papers, 52 (2005), pp. 617-624View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Nonlinear adaptive bilinear filters for active noise control systems&publication_year=2005&author=S.M. Kuo&author=H.-T. Wu)
-
Kuo S.M., Wu H.-T., Chen F.-K., Gunnala M.R.Saturation effects in active noise control systemsIEEE Transactions on Circuits and Systems. I. Regular Papers, 51 (2004), pp. 1163-1171View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Saturation effects in active noise control systems&publication_year=2004&author=S.M. Kuo&author=H.-T. Wu&author=F.-K. Chen&author=M.R. Gunnala)
-
Kuo S.M., Yenduri R.K., Gupta A.Frequency-domain delayless active sound quality control algorithmJournal of Sound and Vibration, 318 (2008), pp. 715-724ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Frequency-domain delayless active sound quality control algorithm&publication_year=2008&author=S.M. Kuo&author=R.K. Yenduri&author=A. Gupta)
-
Lamel L.F., Kassel R.H., Seneff S.Speech database development: Design and analysis of the acoustic-phonetic corpusSpeech input/output assessment and speech databases (1989)[Google Scholar](https://scholar.google.com/scholar_lookup?title=Speech database development%3A Design and analysis of the acoustic-phonetic corpus&publication_year=1989&author=L.F. Lamel&author=R.H. Kassel&author=S. Seneff)
-
Lashkari K.A novel Volterra-Wiener model for equalization of loudspeaker distortions2006 IEEE international conference on acoustics speech and signal processing proceedings (2006), p. V[Google Scholar](https://scholar.google.com/scholar_lookup?title=A novel Volterra-Wiener model for equalization of loudspeaker distortions&publication_year=2006&author=K. Lashkari)
-
Lau S., Tang S.Sound fields in a slightly damped rectangular enclosure under active controlJournal of Sound and Vibration, 238 (2000), pp. 637-660ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Sound fields in a slightly damped rectangular enclosure under active control&publication_year=2000&author=S. Lau&author=S. Tang)
-
Manolakis D.G., Ingle V.K., Kogon S.M., et al.Statistical and adaptive signal processing: spectral estimation, signal modeling, adaptive filtering, and array processingMcGraw-Hill Boston (2000)[Google Scholar](https://scholar.google.com/scholar_lookup?title=Statistical and adaptive signal processing%3A spectral estimation%2C signal modeling%2C adaptive filtering%2C and array processing&publication_year=2000&author=D.G. Manolakis&author=V.K. Ingle&author=S.M. Kogon)
-
Napoli R., Piroddi L.Nonlinear active noise control with NARX modelsIEEE Transactions on Audio, Speech, and Language Processing, 18 (2009), pp. 286-295[Google Scholar](https://scholar.google.com/scholar_lookup?title=Nonlinear active noise control with NARX models&publication_year=2009&author=R. Napoli&author=L. Piroddi)
-
Panda G., Das D.P.Functional link artificial neural network for active control of nonlinear noise processes2003 international workshop on acoustic echo and noise control (2003), pp. 163-166[ View PDF](javascript:😉CrossRef[Google Scholar](https://scholar.google.com/scholar_lookup?title=Functional link artificial neural network for active control of nonlinear noise processes&publication_year=2003&author=G. Panda&author=D.P. Das)
-
Park S.J., Yun J.H., Park Y.C., Youn D.H.A delayless subband active noise control system for wideband noise controlIEEE Transactions on Speech and Audio Processing, 9 (2001), pp. 892-899View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=A delayless subband active noise control system for wideband noise control&publication_year=2001&author=S.J. Park&author=J.H. Yun&author=Y.C. Park&author=D.H. Youn)
-
Reddi S.J., Kale S., Kumar S.On the convergence of adam and beyond(2019)arXiv preprint arXiv:1904.09237[Google Scholar](https://scholar.google.com/scholar_lookup?title=On the convergence of adam and beyond&publication_year=2019&author=S.J. Reddi&author=S. Kale&author=S. Kumar)
-
Rix A.W., Beerends J.G., Hollier M.P., Hekstra A.P.Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs2001 IEEE international conference on acoustics, speech, and signal processing. proceedings (Cat. No. 01CH37221) (2001), pp. 749-752[Google Scholar](https://scholar.google.com/scholar?q=Perceptual evaluation of speech quality -a new method for speech quality assessment of telephone networks and codecs)
-
Rout N.K., Das D.P., Panda G.Computationally efficient algorithm for high sampling-frequency operation of active noise controlMechanical Systems and Signal Processing, 56 (2015), pp. 302-319ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Computationally efficient algorithm for high sampling-frequency operation of active noise control&publication_year=2015&author=N.K. Rout&author=D.P. Das&author=G. Panda)
-
Samarasinghe P.N., Zhang W., Abhayapala T.D.Recent advances in active noise control inside automobile cabins: Toward quieter carsIEEE Signal Processing Magazine, 33 (2016), pp. 61-73View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Recent advances in active noise control inside automobile cabins%3A Toward quieter cars&publication_year=2016&author=P.N. Samarasinghe&author=W. Zhang&author=T.D. Abhayapala)
-
Snyder S.D., Tanaka N.Active control of vibration using a neural networkIEEE Transactions on Neural Networks, 6 (1995), pp. 819-828View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Active control of vibration using a neural network&publication_year=1995&author=S.D. Snyder&author=N. Tanaka)
-
Sommerfeldt, S. D., Parkins, J. W., & Park, Y. C. (1995). Global active noise control in rectangular enclosures. In Proceedings of the inter-noise and noise-con congress and conference (pp. 477–488).[Google Scholar]( https://scholar.google.com/scholar?q=Sommerfeldt , S. D., Parkins, J. W., Park, Y. C. . Global active noise control in rectangular enclosures. In Proceedings of the inter-noise and noise-con congress and conference .)
-
Taal C.H., Hendriks R.C., Heusdens R., Jensen J.An algorithm for intelligibility prediction of time–frequency weighted noisy speechIEEE Transactions on Audio, Speech, and Language Processing, 19 (2011), pp. 2125-2136View Record in Scopus[Google Scholar](https://scholar.google.com/scholar?q=An algorithm for intelligibility prediction of timefrequency weighted noisy speech)
-
Tan L., Jiang J.Adaptive Volterra filters for active control of nonlinear noise processesIEEE Transactions on Signal Processing, 49 (2001), pp. 1667-1676View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Adaptive Volterra filters for active control of nonlinear noise processes&publication_year=2001&author=L. Tan&author=J. Jiang)
-
Tan K., Wang D.L.Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement2019 IEEE international conference on acoustics, speech and signal processing (2019), pp. 6865-6869[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement&publication_year=2019&author=K. Tan&author=D.L. Wang)
-
Tan K., Wang D.L.Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancementIEEE/ACM Transactions on Audio, Speech, and Language Processing, 28 (2019), pp. 380-390[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement&publication_year=2019&author=K. Tan&author=D.L. Wang)
-
Tarabini M., Roure A.Modeling of influencing parameters in active noise control on an enclosure wallJournal of Sound and Vibration, 311 (2008), pp. 1325-1339ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Modeling of influencing parameters in active noise control on an enclosure wall&publication_year=2008&author=M. Tarabini&author=A. Roure)
-
Tobias O.J., Seara R.Leaky-FXLMS algorithm: stochastic analysis for Gaussian data and secondary path modeling errorIEEE Transactions on Speech and Audio Processing, 13 (2005), pp. 1217-1230View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Leaky-FXLMS algorithm%3A stochastic analysis for Gaussian data and secondary path modeling error&publication_year=2005&author=O.J. Tobias&author=R. Seara)
-
Tobias O.J., Seara R.On the LMS algorithm with constant and variable leakage factor in a nonlinear environmentIEEE Transactions on Signal Processing, 54 (9) (2006), pp. 3448-3458View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=On the LMS algorithm with constant and variable leakage factor in a nonlinear environment&publication_year=2006&author=O.J. Tobias&author=R. Seara)
-
Tokhi M., Wood R.Active noise control using radial basis function networksControl Engineering Practice, 5 (1997), pp. 1311-1322ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Active noise control using radial basis function networks&publication_year=1997&author=M. Tokhi&author=R. Wood)
-
Varga A., Steeneken H.J.Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systemsSpeech Communication, 12 (1993), pp. 247-251ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Assessment for automatic speech recognition%3A II. NOISEX-92%3A A database and an experiment to study the effect of additive noise on speech recognition systems&publication_year=1993&author=A. Varga&author=H.J. Steeneken)
-
Wang D.L., Chen J.Supervised speech separation based on deep learning: An overviewIEEE/ACM Transactions on Audio, Speech, and Language Processing, 26 (2018), pp. 1702-1726[ View PDF](javascript:😉CrossRef[Google Scholar](https://scholar.google.com/scholar_lookup?title=Supervised speech separation based on deep learning%3A An overview&publication_year=2018&author=D.L. Wang&author=J. Chen)
-
Williamson D.S., Wang Y., Wang D.L.Complex ratio masking for joint enhancement of magnitude and phase2016 IEEE international conference on acoustics, speech and signal processing (2016), pp. 5220-5224View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Complex ratio masking for joint enhancement of magnitude and phase&publication_year=2016&author=D.S. Williamson&author=Y. Wang&author=D.L. Wang)
-
Yang F., Cao Y., Wu M., Albu F., Yang J.Frequency-domain filtered-x LMS algorithms for active noise control: a review and new insightsApplied Sciences, 8 (2018), p. 2313[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Frequency-domain filtered-x LMS algorithms for active noise control%3A a review and new insights&publication_year=2018&author=F. Yang&author=Y. Cao&author=M. Wu&author=F. Albu&author=J. Yang)
-
Zhang Q.-Z., Gan W.-S., Zhou Y.-l.Adaptive recurrent fuzzy neural networks for active noise controlJournal of Sound and Vibration, 296 (2006), pp. 935-948ArticleDownload PDFView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Adaptive recurrent fuzzy neural networks for active noise control&publication_year=2006&author=Q.-Z. Zhang&author=W.-S. Gan&author=Y.-l. Zhou)
-
Zhang, H., & Wang, D. L. (2020). A deep learning approach to active noise control. In Proceedings of the 2020 conference of the international speech communication association (pp. 1141–1145).[Google Scholar]( https://scholar.google.com/scholar?q=Zhang , H., Wang, D. L. . A deep learning approach to active noise control. In Proceedings of the 2020 conference of the international speech communication association .)
-
Zhou D., DeBrunner V.Efficient adaptive nonlinear filters for nonlinear active noise controlIEEE Transactions on Circuits and Systems. I. Regular Papers, 54 (3) (2007), pp. 669-681View Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=Efficient adaptive nonlinear filters for nonlinear active noise control&publication_year=2007&author=D. Zhou&author=V. DeBrunner)
-
Zhou Y.-L., Zhang Q.-Z., Li X.-D., Gan W.-S.Analysis and DSP implementation of an ANC system using a filtered-error neural networkJournal of Sound and Vibration, 285 (1–2) (2005), pp. 1-25ArticleDownload PDF[Google Scholar](https://scholar.google.com/scholar_lookup?title=Analysis and DSP implementation of an ANC system using a filtered-error neural network&publication_year=2005&author=Y.-L. Zhou&author=Q.-Z. Zhang&author=X.-D. Li&author=W.-S. Gan)
-
Zhu Q., Qiu X., Burnett I.An acoustic modelling based remote error sensing approach for quiet zone generation in a noisy environment2020 IEEE international conference on acoustics, speech and signal processing (2020), pp. 8424-8428[ View PDF](javascript:😉CrossRefView Record in Scopus[Google Scholar](https://scholar.google.com/scholar_lookup?title=An acoustic modelling based remote error sensing approach for quiet zone generation in a noisy environment&publication_year=2020&author=Q. Zhu&author=X. Qiu&author=I. Burnett)
本文来自博客园,作者:{Ray963},转载请注明原文链接:{https://www.cnblogs.com/ray93/}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号