
本地运行LLaMa3:70b
主机配置
OS: CentOS Stream 9
RAM: 128 GB
CPU: Xeon W2465(16核)
GPU: NVIDIA RTX A5000 24GB
安装GPU驱动
First, confirm that your system meets the necessary requirements, including the installation of the NVIDIA driver and CUDA toolkit.
`
docs:Install GPU Driver
安装完成后验证:

`
安装Ollama模型管理容器
官网直达:https://ollama.com/download/linux
配置启动服务
点击查看代码
#vi /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
#配置远程访问
Environment="OLLAMA_HOST=0.0.0.0"
#配置跨域请求
Environment="OLLAMA_ORIGINS=*"
#配置OLLAMA的模型存放路径,防止内存不足,一般的默认路径是/usr/share/ollama/.ollama/models/
Environment="OLLAMA_MODELS=/home/ollama/.ollama/models"
[Install]
WantedBy=default.target
##修改完后执行
sudo systemctl daemon-reload
sudo systemctl enable ollama
修改目录访问权限
chown -R ollama:ollama /home/ollama
安装结束运行Llama3:70b
ollama run llama3:70b
安装Open webui
采用Docker image安装 -> 这里采用共享主机网络: --network=host,因为我ollama没有采用docker安装,docker虚拟进程网络访问本地网络会有问题:
docker run -d -p 3000:8080 --network=host --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
开启局域网防火墙
firewall-cmd --permanent --add-port=3000/tcp
firewall-cmd --reload
这里要注意一下,1是本地主机的防火墙配置,2是路由器配置也要检查一下。
效果
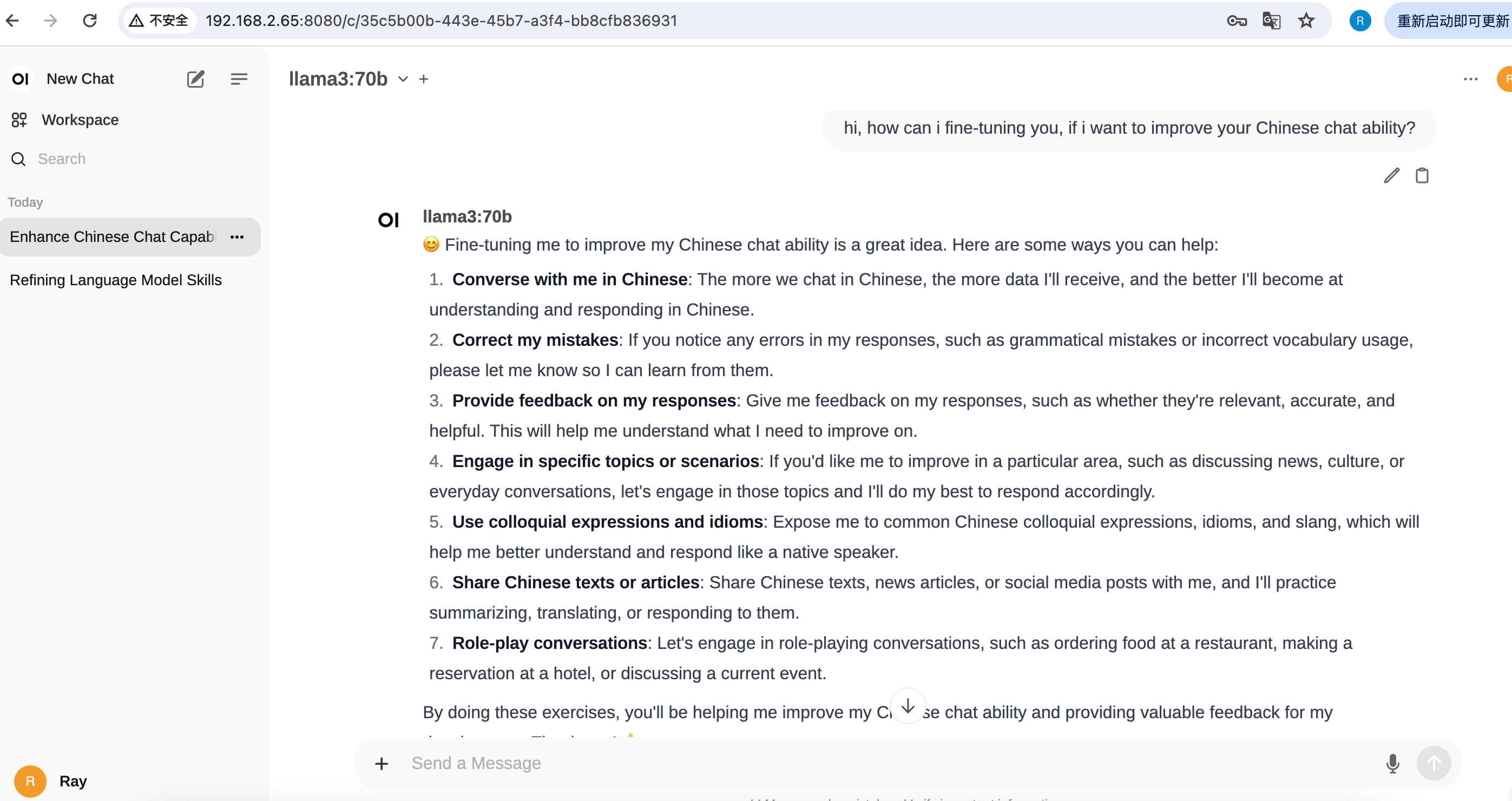
安装LLaMaFactory
官网直达:https://github.com/hiyouga/LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[torch,metrics]
cd /home/lenovo/workspaces/LLaMA-Factory/src
python webui.py
开启局域网防火墙
firewall-cmd --permanent --add-port=7860/tcp
firewall-cmd --reload
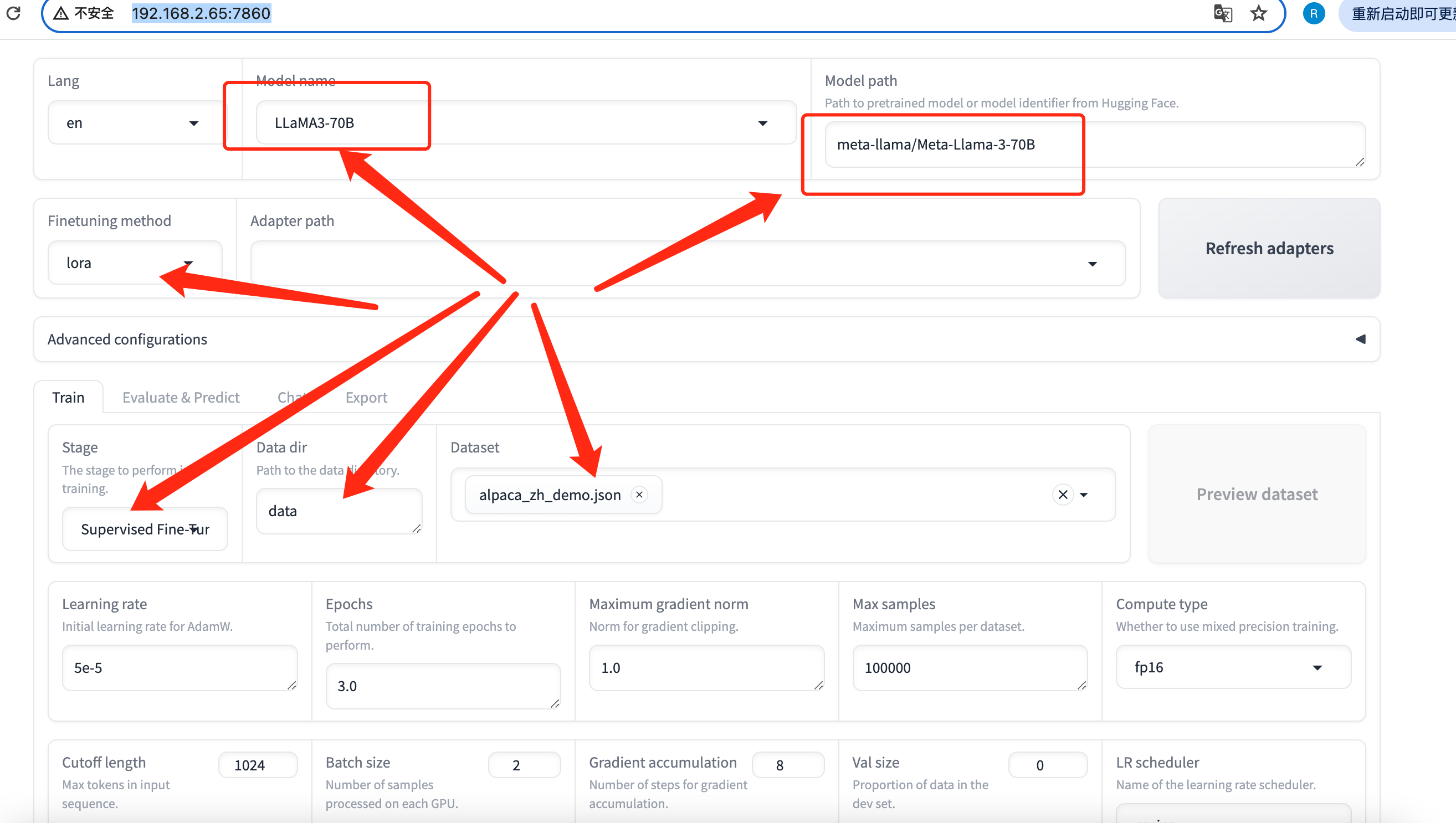
SFT/LoRa LLaMa3:70b 本地其实跑不动,可以考虑HuggingFace服务端训练完,本地只做推理。。。
小记
- 没有**基本下不动40g的包,得先装**,这个可能会比较麻烦;
- 更有性价比的方式,还是使用百度的「文心一言」和阿里的「qwen」,这两个中文支持比较好,LLaMa3的中文支持太弱了,需要自己在做sft,还是比较麻烦的;
- llama3:70b的生成速度A5000的加速效果还是比较明显的,如果能上两张卡,效果会更好一些,后面可以考虑一下;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号