
4. vision transformer
原视频是:【逐行手敲代码并详解Vision Transformer(ViT)】https://www.bilibili.com/video/BV1c97szNEkM?vd_source=364e8fc0912c5a05202db5a7ef7965d7
我只是学习然后自己敲一遍
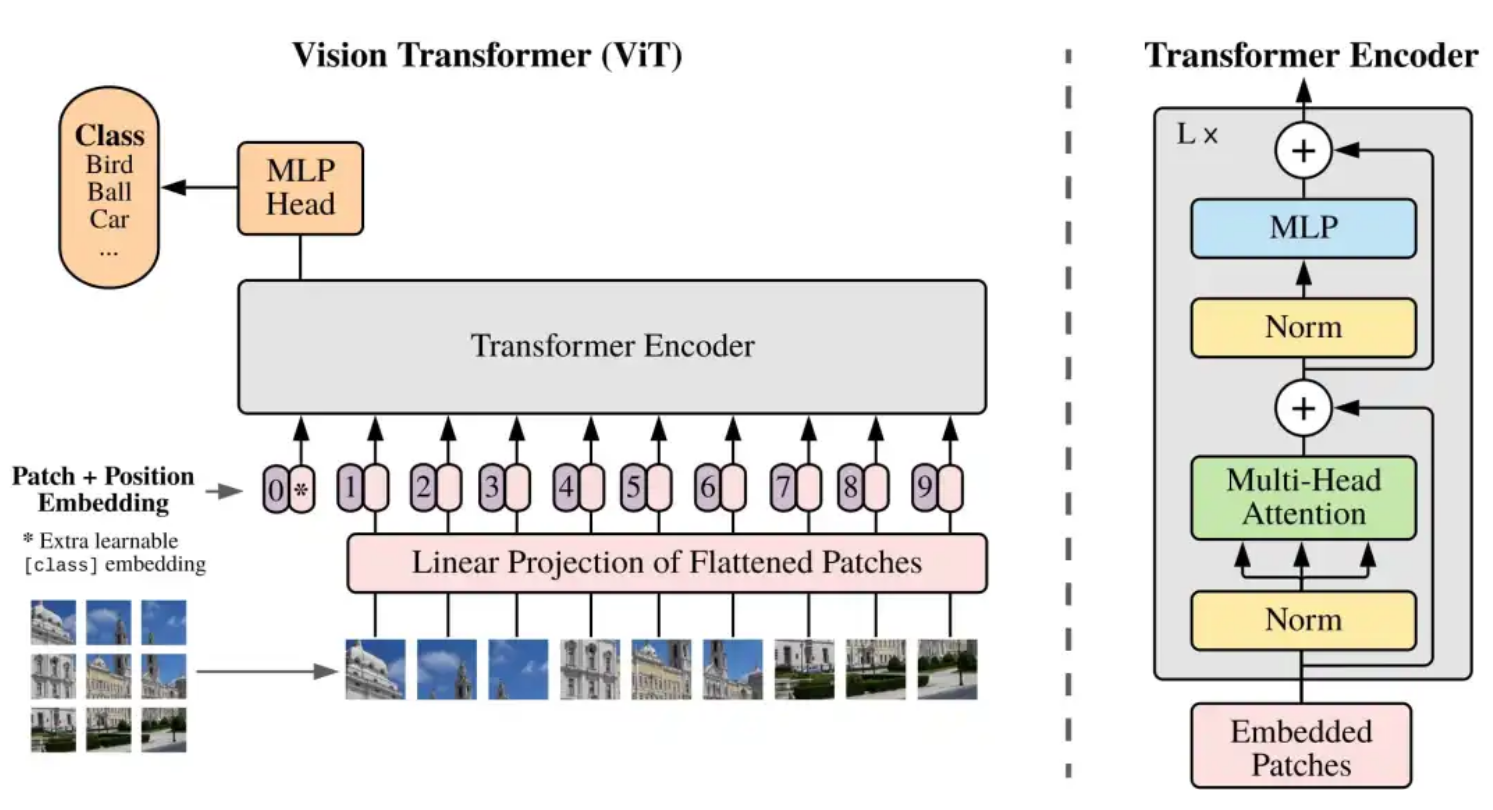
PatchEmbed
class PatchEmbed(nn.Module):
def __init__(self, image_size=224, patch_size=16, in_channels=3, embed_dim=768, norm_layer=None):
super().__init__()
image_size = (image_size, image_size)
patch_size = (patch_size, patch_size)
self.image_size = image_size[0]
self.patch_size = patch_size[0]
self.grid_size = (image_size[0] // patch_size[0], image_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else None
def forward(self, x):
B, C, H, W = x.shape
# 检查维度是否匹配
if H != self.image_size or W != self.image_size:
raise ValueError(f"Input image size ({H}x{W}) doesn't match model ({self.image_size}x{self.image_size}).")
# (b, 3, 224, 224) -> (b, 768, 14, 14) -> (b, 768, 196) -> (b, 196, 768)
# 14是 (224 + 2*1 - 16) // 16 + 1
x = self.proj(x).flatten(2).transpose(1, 2)
if self.norm:
x = self.norm(x)
return x # (B, N, C) where N is number of patches
Attention
class Attention(nn.Module):
def __init__(
self,
dim,#输入的token维度,768
num_heads=8,# 注意力的头数,为8
qkv_bias=False,#生成QkV的时候是否添加偏置
qk_scale=None,#用于缩放Qk的系数,如果None,则使用1/sqrt(head_dim)
attn_drop_ratio=0.,#注意力分数的dropout的比率,防止过拟合
proj_drop_ratio=0.): #最终投影层的dropout比例
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = qk_scale or self.head_dim ** -0.5 # qk的缩放因子
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) #通过全连接层生成QKV,为了并行计算,提高计算效率,参数更少
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj_drop = nn.Dropout(proj_drop_ratio)
#将每个head得到的输出进行concat拼接,然后通过线性变换映射回原本的嵌入dim
self.proj = nn.Linear(dim, dim)
def forward(self, x):
B, N, C = x.shape # batch, num_patchs+1, embed_dim 这个1为class token
# (B, N, C) -> (B, N, 3*C) -> (B, N, 3, num_heads, head_dim) -> (3, B, num_heads, N, head_dim)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
# 用切片拿到QkV,形状B,self.num_heads,N,c//self.num_heads
q, k, v = qkv[0], qkv[1], qkv[2]
#计算gk的点积,并进行缩放得到注意力分数
#Q :[B, num_heads, N, C//self.num_heads]
#K :[B, num_heads, N, C//self.num_heads] -> [B, num_heads, C//self.num_heads, N]
attn = (q @ k.transpose(-2, -1)) * self.scale # [B, num_heads, N, N]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# v :[B, num_heads, N, C//self.num_heads]
# transpose: [B, num_heads, N, C//self.num_heads] -> [B, num_heads, C//self.num_heads, N]
# reshape: [B, num_heads, C//self.num_heads, N] -> [B, N, C] 将最后两个维度信息拼接,合并多个头输出,回到总的嵌入维度
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
# 将每个head得到的输出进行concat拼接,然后通过线性变换映射回原本的嵌入dim
x = self.proj(x)
x = self.proj_drop(x)
return x
MLP
class MLP(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop_ratio=0.):
# in features输入的维度 hidden feature隐藏层的维度通常为in_features的4倍,out_features维度通常与in_features相同
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop_ratio)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
Block
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None,
drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)
self.drop_path = nn.Dropout(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop_ratio=drop_ratio)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) # 残差连接
x = x + self.drop_path(self.mlp(self.norm2(x))) # 残差连接
return x

 浙公网安备 33010602011771号
浙公网安备 33010602011771号