2. UNet
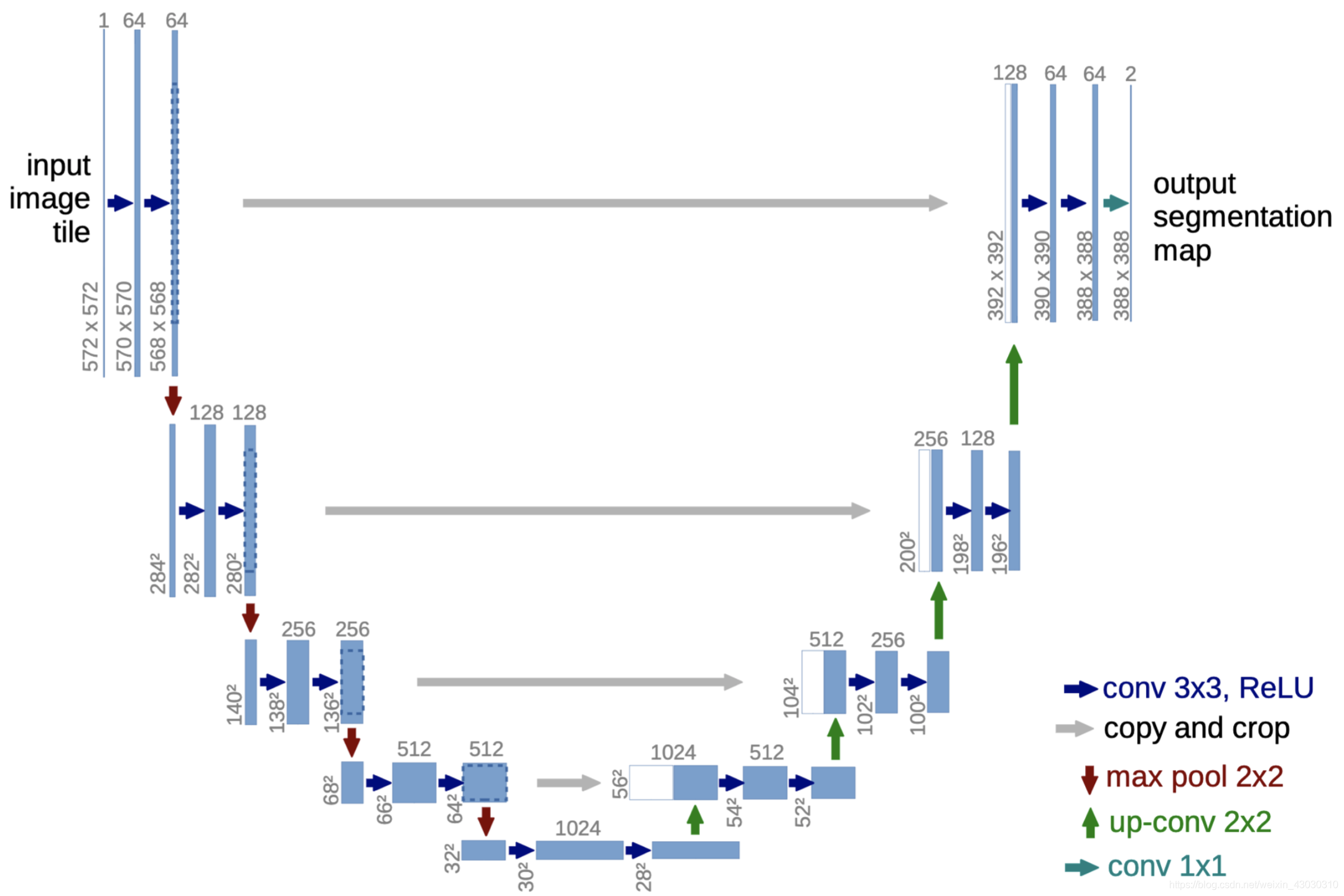
import torch
import torch.nn as nn
from torch.autograd import Variable as V
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.down1 = self.conv_stage(3, 8)
self.down2 = self.conv_stage(8, 16)
self.down3 = self.conv_stage(16, 32)
self.down4 = self.conv_stage(32, 64)
self.down5 = self.conv_stage(64, 128)
self.down6 = self.conv_stage(128, 256)
self.down7 = self.conv_stage(256, 512)
self.center = self.conv_stage(512, 1024)
#self.center_res = self.resblock(1024)
self.up7 = self.conv_stage(1024, 512)
self.up6 = self.conv_stage(512, 256)
self.up5 = self.conv_stage(256, 128)
self.up4 = self.conv_stage(128, 64)
self.up3 = self.conv_stage(64, 32)
self.up2 = self.conv_stage(32, 16)
self.up1 = self.conv_stage(16, 8)
self.trans7 = self.upsample(1024, 512)
self.trans6 = self.upsample(512, 256)
self.trans5 = self.upsample(256, 128)
self.trans4 = self.upsample(128, 64)
self.trans3 = self.upsample(64, 32)
self.trans2 = self.upsample(32, 16)
self.trans1 = self.upsample(16, 8)
self.conv_last = nn.Sequential(
nn.Conv2d(8, 1, 3, 1, 1),
nn.Sigmoid()
)
self.max_pool = nn.MaxPool2d(2)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
if m.bias is not None:
m.bias.data.zero_()
def conv_stage(self, dim_in, dim_out, kernel_size=3, stride=1, padding=1, bias=True, useBN=False):
if useBN:
return nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias),
nn.BatchNorm2d(dim_out),
#nn.LeakyReLU(0.1),
nn.ReLU(),
nn.Conv2d(dim_out, dim_out, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias),
nn.BatchNorm2d(dim_out),
#nn.LeakyReLU(0.1),
nn.ReLU(),
)
else:
return nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias),
nn.ReLU(),
nn.Conv2d(dim_out, dim_out, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias),
nn.ReLU()
)
def upsample(self, ch_coarse, ch_fine):
return nn.Sequential(
nn.ConvTranspose2d(ch_coarse, ch_fine, 4, 2, 1, bias=False),
nn.ReLU()
)
def forward(self, x):
conv1_out = self.down1(x)
conv2_out = self.down2(self.max_pool(conv1_out))
conv3_out = self.down3(self.max_pool(conv2_out))
conv4_out = self.down4(self.max_pool(conv3_out))
conv5_out = self.down5(self.max_pool(conv4_out))
conv6_out = self.down6(self.max_pool(conv5_out))
conv7_out = self.down7(self.max_pool(conv6_out))
out = self.center(self.max_pool(conv7_out))
#out = self.center_res(out)
out = self.up7(torch.cat((self.trans7(out), conv7_out), 1))
out = self.up6(torch.cat((self.trans6(out), conv6_out), 1))
out = self.up5(torch.cat((self.trans5(out), conv5_out), 1))
out = self.up4(torch.cat((self.trans4(out), conv4_out), 1))
out = self.up3(torch.cat((self.trans3(out), conv3_out), 1))
out = self.up2(torch.cat((self.trans2(out), conv2_out), 1))
out = self.up1(torch.cat((self.trans1(out), conv1_out), 1))
out = self.conv_last(out)
return out
bilibili有up一步一步教写改良后的,【图像分割UNet硬核讲解(带你手撸unet代码)】https://www.bilibili.com/video/BV11341127iK

 浙公网安备 33010602011771号
浙公网安备 33010602011771号