numpy库学习
1. 初始化
numpy数组即numpy的ndarray对象,创建numpy数组就是把一个列表传入np.array()方法。
下面介绍4种方法:
- 从Python中的列表、元组等类型创建ndarray数组。
x = np.array(list/tuple)
x = np.array(list/tuple, dtype=np.float32) # 可以指定类型
x = np.array([[1, 2], [8, 9], (0.1, 0.2)])
- 使用NumPy中函数创建ndarray数组,如: arange,ones,zeros等



需要注意的是,`ones''zeros''eyes'创建的都是浮点数类型的数组,arange生成的是整数类型,有需要可以指定类型
x = np.ones((3,6) , dtype = np.int32)
# [[1 1 1 1 1 1]
# [1 1 1 1 1 1]
# [1 1 1 1 1 1]]
x = np.ones((3,6))
# [[1. 1. 1. 1. 1. 1.]
# [1. 1. 1. 1. 1. 1.]
# [1. 1. 1. 1. 1. 1.]]
a = np.linspace(1,10,4) # array([ 1., 4., 7., 10.])
b = np.linspace(1,10,4,endpoint=False) # array([ 1. , 3.25, 5.5 , 7.75])
c = np.concatenate((a, b)) # array([ 1. , 4. , 7. , 10. , 1. , 3.25, 5.5 , 7.75])
- 从字节流(raw bytes )中创建ndarray数组。
- 从文件中读取特定格式,创建ndarray数组。
2. 常用属性
| 属性 | 解释 |
|---|---|
| T | 数组的转置(对高维数组而言) |
| dtype | 数组元素的数据类型 |
| size | 数组元素的个数 |
| ndim | 数组的维数 |
| shape | 数组的维度大小(以元组形式) |
| astype | 类型转换 |
2.1 shape获取行列数
arr = np.array([[1, 2, 3], [4, 5, 6]])
arr.ndim # 2
arr.shape # (2, 3)
arr.shape[0] # 2 提取行数
arr.shape[1] # 3 提取列数
arr.size # 6
arr.dtype # dtype('int32')
2.2 元素类型
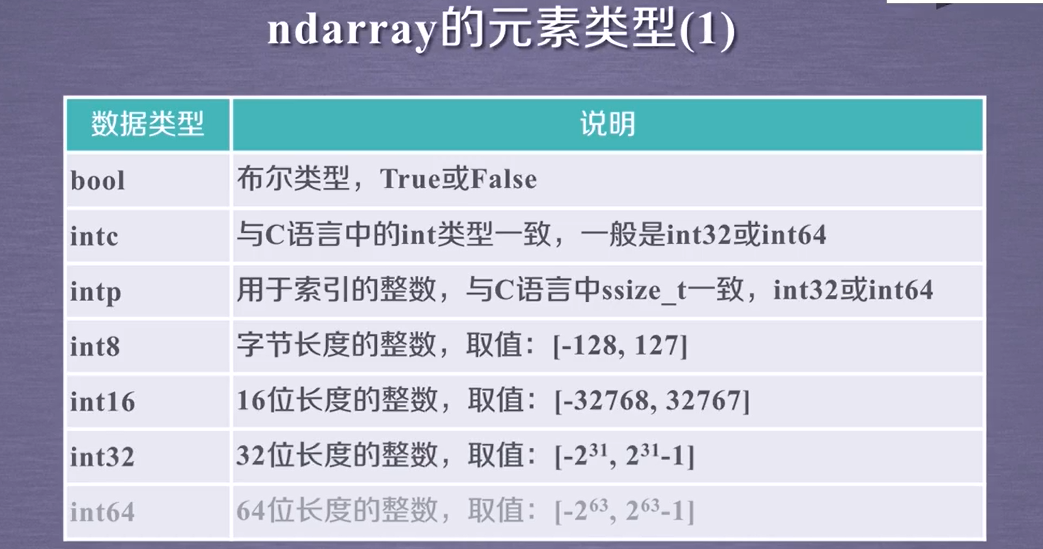
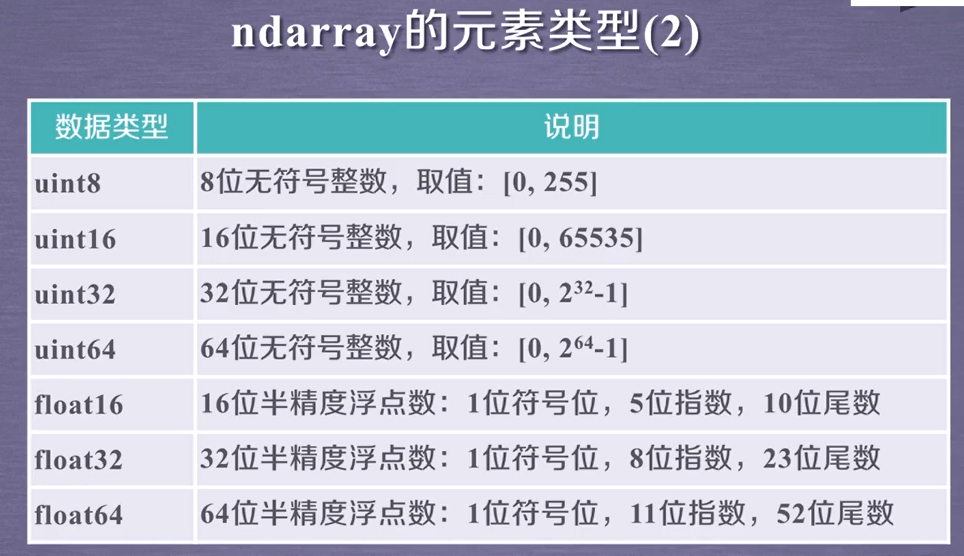

2.3 类型转换

astype()方法一定会创建新的数组(原始数据的一个拷贝),即使两个类型一致。
还可以使用tolist函数向列表转换

2.4. 数组的维度变换

a = np.ones((2, 3, 4))
a.reshape(3, 8)
a.resize(3, 8)
a.flatten()
3. 数组的索引和切片
一维数组的索引和切片: 与Python的列表类似
多维数组的索引:
a = np.arange(24).reshape((2,3,4))
# [[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# [[12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]]
a[1, 2, 3] # 23
a[-1, -2, -3] # 17
多维数组的切片:
依然以上面的a数组为例进行切片

4. 数组的运算
常用函数
| 分类 | 函数 | 功能说明 |
|---|---|---|
| 基本数学 | np.sqrt(x) | 计算平方根 |
| np.exp(x) | 计算指数(e^x) | |
| np.log(x) | 计算自然对数(ln(x)) | |
| np.sin(x) | 计算正弦值 | |
| np.abs(x) | 计算绝对值 | |
| np.power(a, b) | 计算 a 的 b 次幂 | |
| np.round(x, n) | 四舍五入(保留 n 位小数) | |
| 统计 | np.sum(x) | 求和 |
| np.mean(x) | 计算均值 | |
| np.median(x) | 计算中位数 | |
| np.std(x) | 计算标准差 | |
| np.var(x) | 计算方差 | |
| np.min(x) / np.max(x) | 查找最小值/最大值 | |
| np.percentile(x, q) | 计算分位数(q: 0~100) | |
| 比较 | np.greater(a, b) | 元素级比较 a > b |
| np.less(a, b) | 元素级比较 a < b | |
| np.equal(a, b) | 元素级比较 a == b | |
| np.logical_and(a, b) | 逻辑与(逐元素) | |
| np.where(condition, x, y) | 根据条件选择元素 | |
| 排序 | np.sort(x) | 返回排序后的副本 |
| x.sort() | 原地排序(修改原数组) | |
| np.argsort(x) | 返回排序后的索引 | |
| np.lexsort(keys) | 多键排序(按最后一列优先) | |
| 去重 | np.unique(x) | 返回唯一值并排序 |
| np.in1d(a, b) | 检查 a 的元素是否在 b 中存在 | |
| 其他实用 | np.concatenate((a, b)) | 数组拼接 |
| np.split(x, indices) | 分割数组 | |
| np.reshape(x, shape) | 调整数组形状 | |
| np.copy(x) | 创建数组的深拷贝 | |
| np.isnan(x) | 检测 NaN 值 |
4.1 与标量的运算
数组与标量之间的运算作用于数组的每一个元素
a = np.arange(24).reshape((2,3,4))
a = a/a.mean() # a.mean() = 11.5
# array([[[0. , 0.08695652, 0.17391304, 0.26086957],
# [0.34782609, 0.43478261, 0.52173913, 0.60869565],
# [0.69565217, 0.7826087 , 0.86956522, 0.95652174]],
# [[1.04347826, 1.13043478, 1.2173913 , 1.30434783],
# [1.39130435, 1.47826087, 1.56521739, 1.65217391],
# [1.73913043, 1.82608696, 1.91304348, 2. ]]])
4.2 一元函数
运算时需要注意原数组的值是否改变,几乎所有的函数都不会改变原数组,如需改变,需要重新赋值


4.3 二元函数
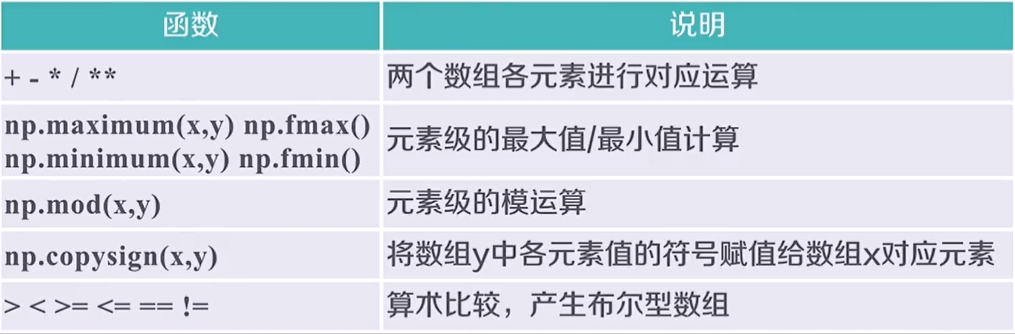
5. 数据的CSV存取
5.1 存入数据
np.savetxt(frame, array, fmt= '%.18e', delimiter=None)
- frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件。
- array:存入文件的数组
- fmt: 写入文件的格式,例如: %d %.2f %.18e
- delimiter: 分割字符串,默认是任何空格
a = np.arange(100).reshape(5,20)
np.savetxt('a.csv', a, fmt='%d', delimiter=',')
生成的文件打开如下所示:

5.2 读取数据
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
- frame:文件、字符串或产生器,i可以是.gz或.bz2的压缩文件。
- dtype:数据类型,可选。
- delimiter: 分割字符串,默认是任何空格
- unpack:如果True,读入属性将分别写人不同变量

上述方法也具有一定缺点,即只能存取一维和二维数组。
6. 多维数据的存取
6.1 存入数据
a.tofile(frame, sep=", format='s')
- frame: 文件、字符串。
- sep: 数据分割字符串,如果是空串,写入文件为二进制。
- format:写入数据的格式
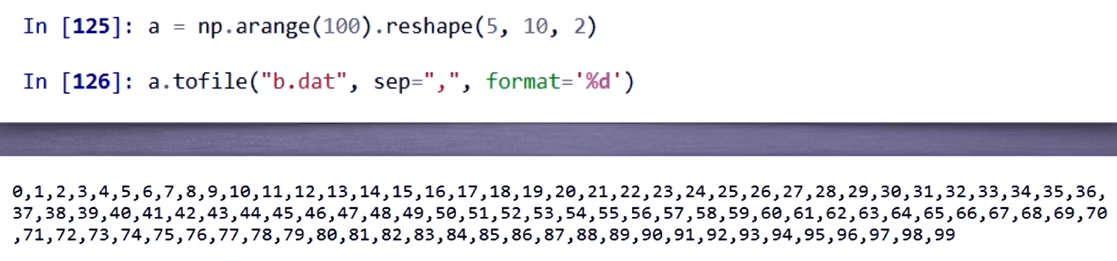
如果sep是空串,就会生成二进制文件:
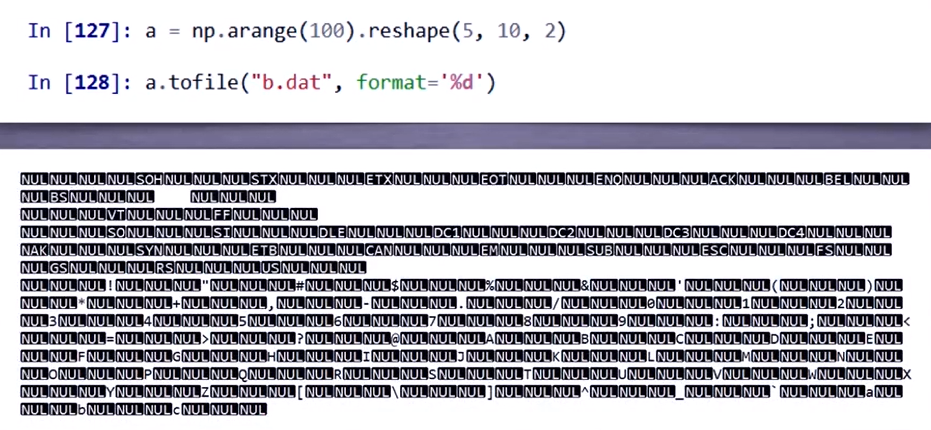
6.2 读取数据
np.fromfile(frame, dtype=float, count=-1, sep=")
- frame:文件、字符串。
- dtype:读取的数据类型
- count:读人元素个数,-1表示读入整个文件。
- sep:数据分割字符串,如果是空串,写入文件为二进制。

该方法需要读取时知道存人文件时数组的维度和元素类型
a.tofile()和np.fromfile()需要配合使用
7. NumPy的便捷文件存取
np.save(fname, array) np.savez(fname, array)
- frame: 文件名,以.npy为扩展名,压缩扩展名为.npz
- array:数组变量
np.load(fname)
- fname: 文件名,以.npy为扩展名,压缩扩展名为.npz

8. 常用函数
8.1 随机数函数
np.random的随机数函数:



a = np.random.randint(100,200,(3,4))
# array([[175, 122, 151, 185],
# [103, 112, 135, 196],
# [110, 161, 118, 109]])
np.random.shuffle(a) # 此时a会发生改变,而permutation(a)不会使a发生改变
# array([[103, 112, 135, 196],
# [175, 122, 151, 185],
# [110, 161, 118, 109]])
b = np.random.randint(100,200,(8,)) # array([193,175,186,137,111,121,133,195])
np.random.choice(b,(3,2)) # array([[137,193],[193,121],[175,193]])
np.random.choice(b,(3,2),replace=False) # array([[111,175],[193,195],[186,133]])
np.random.choice(b,(3,2),p= b/np.sum(b)) # array([[121,175],[193,186],[193,175]])
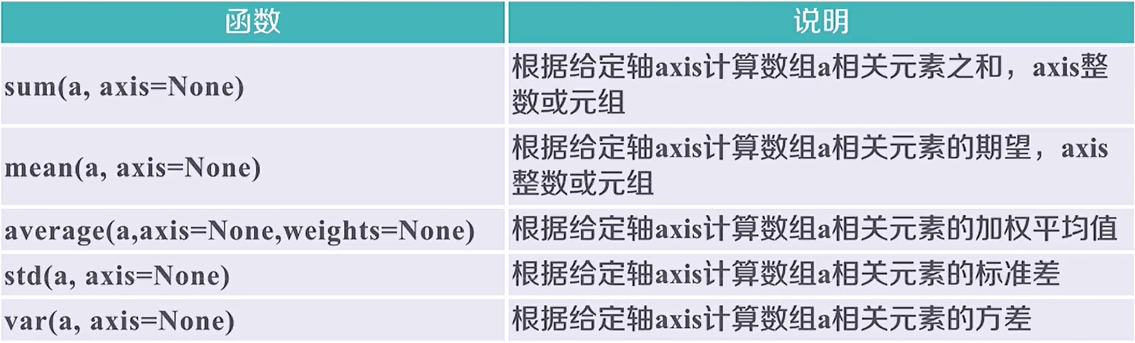
8.2 统计函数
np的统计函数:
a = np.arange(15).reshape(3,5)
# [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]]
np.sum(a) # 105
np.mean(a, axis=1) # array([ 2.,7., 12.]),只在第二维做运算
np.mean(a,axis=0) # [5. 6. 7. 8. 9.]
np.average(a, axis=0,weights=[10,5,1]) # [2.1875 3.1875 4.1875 5.1875 6.1875]
# 4.1875 = (2*10 + 7*5 + 12*1)/16
np.std(a) # 4.3204937989385739
np.var(a) # 18.666666666666668
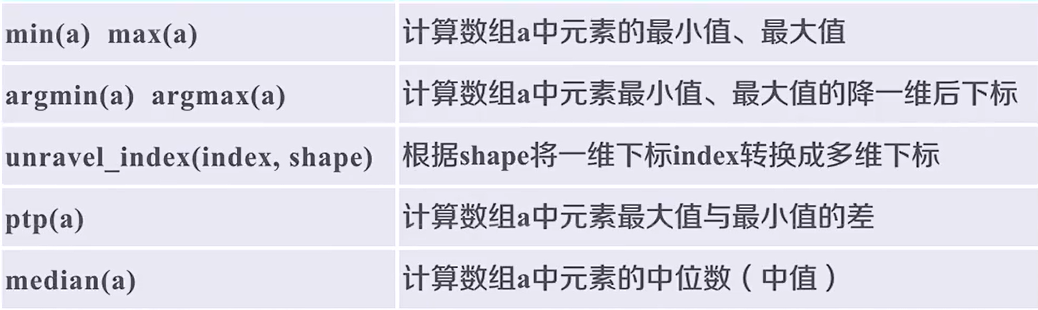
np.max(b) # 14
np.argmax(b) # 14,扁平化后的下标
np.unravel_index(np.argmax(b), bshape) # (2,4)
np.ptp(b) # 14
np.median(b) # 7.0
8.3 梯度函数
np.gradient(f)计算数组f中元素的梯度,当f为多维时,返回每个维度梯度
梯度: 连续值之间的变化率,即斜率,XY坐标轴连续三个X坐标对应的Y轴值: a,b,c,其中,b的梯度是:(c-a)/2
a = np.random.randint(0 , 20 , 5) # [19 0 17 5 0]
print(np.gradient(a)) # [-19. -1. 2.5 -8.5 -5. ]
# 两侧值:-1 = (17-19)/2 , 一侧值:-5 = (0-5)/1
# 多维:
a = np.random.randint(0 , 50 , (3,5))
# [[17 43 7 43 28]
# [27 4 34 28 40]
# [34 36 14 28 47]]
np.gradient(a)
# [array([[ 10. , -39. , 27. , -15. , 12. ], 最外层维度的梯度
# [ 8.5, -3.5, 3.5, -7.5, 9.5],
# [ 7. , 32. , -20. , 0. , 7. ]]),
# array([[ 26. , -5. , 0. , 10.5, -15. ], 第二层维度的梯度
# [-23. , 3.5, 12. , 3. , 12. ],
# [ 2. , -10. , -4. , 16.5, 19. ]])]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号