
2.2数据结构(2)
1.Trie树 , 高速地存储和查找字符串集合的数据结构
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int son[N][26] , cnt[N] , idx;
char str[N];
void insert(char str[]){
int t = 0;
for(int i = 0 ; str[i] ; i++){
int u = str[i] - 'a';
if(!son[t][u]) son[t][u] = ++idx;
t = son[t][u];
}
cnt[t]++;
}
int query(char str[]){
int t = 0;
for(int i = 0 ; str[i] ; i++){
int u = str[i] - 'a';
if(!son[t][u]) return 0;
t = son[t][u];
}
return cnt[t];
}
int main()
{
int n;
scanf("%d", &n);
char op[5];
while (n -- ){
scanf("%s%s" , op , str);
if(op[0]=='I') insert(str);
else printf("%d\n" , query(str));
}
return 0;
}
2.并查集

会实现一个路径压缩的优化
#include <iostream>
using namespace std;
const int N = 100010;
int p[N];//存储每个数的根节点
int m , n ;
//整个代码的核心好吧,包含路径压缩的优化
int find(int n){
if(p[n]!=n) p[n] = find(p[n]);//使n的根节点等于祖宗节点
return p[n];
}
int main(){
scanf("%d%d" , &n , &m);
for(int i = 1 ; i <= n ; i++) p[i] = i;
while(m--){
char op[2];
int a,b;
scanf("%s%d%d" , op , &a , &b);
if(op[0]=='M') p[find(a)] = find(b);//把a所在集合放在b的祖宗节点下面
else{
if(find(a)==find(b)) printf("Yes\n");
else printf("No\n");
}
}
return 0;
}
3.堆



#include <iostream>
using namespace std;
const int N = 100010;
int a[N] , s;
void down(int x){//排序
int t = x;
if(2*x <= s and a[t] > a[2*x]) t = 2*x;
if(2*x+1 <= s and a[t]> a[2*x+1]) t = 2*x+1;
if(t!=x) swap(a[x] , a[t]) , down(t);
}
int main(){
int m , n;
scanf("%d%d" , &n,&m);
for(int i = 1 ; i <= n ; i++) scanf("%d" , &a[i]);
s = n;
for(int i = n/2 ; i ; i--) down(i);
while(m--){
printf("%d " , a[1]);
a[1] = a[s];//让队尾的来到队头,然后排序,记得要把数s减一
s--;
down(1);
}
return 0;
}这种写法比用sort快一点欸 ,虽然也没快很多
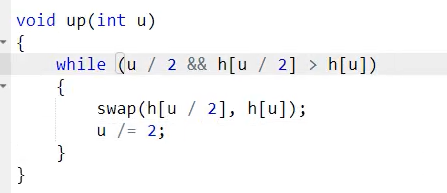
这是up:不用判断两次

 浙公网安备 33010602011771号
浙公网安备 33010602011771号