付资婷---第二次作业
| 这个作业属于哪个课程 | 至诚软工实践F班 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/homework/12532 |
| 这个作业的目标 | 1.利用fiddler实现爬虫抓取数据处理 2.代码编写规范 3.对过程进行记录、思考 |
| Github 地址 | https://github.com/rarecard/pupu_python_fiddler |
前言
此次作业涉及的内容,根据我所查到的相关资料主要是计算机网络和python,一个是了解客户端和服务端如何传输数据,一个是利用python来实现数据的发送和接收。python我是不熟悉的,计算机网络也是这学期刚开课,所以刚面对这次作业我是感觉十分棘手,只能一点一点的去查资料,花费了我很多时间,因为相比较去网上按照教程直接实现功能,我更希望理解背后的原理,所以查资料的时候很多是关于原理方面内容,只有理解了才能更好的使用和进步,所以此次我的博客内容会有很多我关于对本次作业的思路和思考,代码方面就比较强差人意了。
任务:【必做】基础:使用 fiddler 抓包工具+代码,实时监控朴朴上某产品的详细价格信息
一、解题思路描述
1. 了解fiddler抓包工具的使用是怎么使用和原理,简单配置fiddler,然后研究如何抓取app数据
- 遇见问题:
(1)校园网一使用fiddler就会掉线
(2)ios设备无法连接到本机IP:8888网页下载证书
(3)配置完手动代理之后无法上网 - 解决思路:
(1)因为校园网一使用fiddler就会掉线,所以我这里使用手机开热点用pc+ipad(ios设备)来进行连接测试,网络上的教程大同小异,当我按照步骤一步一步往下做却还是遇见了这些问题。
(2)问题的时候我先是检查防火墙,cmd中ping ios设备IP,测试是否连通,确保二者是可以连通状态,然后直接将证书文件通过网络发给ios设备,安装开启证书,解决失败。然后发现ipad网络设置中有个私人地址的开关,关闭即可
(3)配置完手动代理之后一定要去开启证书信任,就可以正常上网,此时fiddler也可以正常抓取app数据了
(第二天再次使用我手机热点尝试连接ipad时,尝试了各种方法始终连不上,但是切换了室友的热点后神奇的又可以正常抓取数据了,虽然问题解决,真正的原因还是不太明白)
2. 编程语言的选择(Java or python?)
- 为什么我没有用Java?
最开始我尝试使用java进行代码编写实现,因为上学期刚学的java所以比较熟悉,网上查资料大多都是只能http链接抓取,或者需要使用spring框架,网上关于java+fiddler获取https的教程也比较少,感官上觉得比较复杂,而且我也不懂爬虫的原理,原来也没尝试过这方面内容,一时之间有些无从下手,后来上课看到助教演示,决定用python来实现,查资料的时候python+fiddler实现爬虫的教程也比较多,算是新手友好max程度了,总算是有点头绪,于是开始往这方面进行研究
(因为我一开始对本次作业的理解是要求程序通过fiddler来抓取数据,也就是java程序→fiddler→向服务器发送请求,实际上还是fiddler发送请求,琢磨如何程序连接fiddler,查找资料的方向也是这方面,所以展开很不顺利,后续学习python的时候发现只是需要从fiddler获得的信息来进行使用即可,同理使用java也是一样,不过还是python编写起来更简单些)
3. python学习
- 首先,我先去搜索python基础教程,了解一下它的语法特点,和如何使用python。好在编程语言是相同的,理解起来不算太困难
- 然后搜索 python爬虫原理,了解到所谓爬虫就是程序模拟浏览器发请求给服务器
- 我又在思考,网站发送请求是怎样的一个过程,以前学网页的时候有学过,好久没接触这方面都忘得精光,查完资料明白了最主要的是建立TCP连接,通过http协议发送请求
4. 实现思路
- 明白了基本的原理后,我的思路是代码编写一个虚拟的浏览器请求,fiddler收到请求后给服务器发送,接收到的信息传回程序中的变量,然后对该变量进行数据筛选处理,输出想要的内容
到这里,对于具体该如何实现代码内容,还是一头雾水,只能去网上看看别人是怎么写的,去理解
参考:
Python爬虫原理 - 安暖如初 - 博客园 (cnblogs.com)
一次访问网页请求的全过程详解 - 往事如云烟都付笑谈中 - 博客园 (cnblogs.com)
二、实现过程(python+fiddler)
fiddler部分
1. 获取头部信息,也就是我们客户端的信息,用来模拟客户端发送信息
2.所需要请求的url地址
以上信息可以在fiddler中Inspectors获取
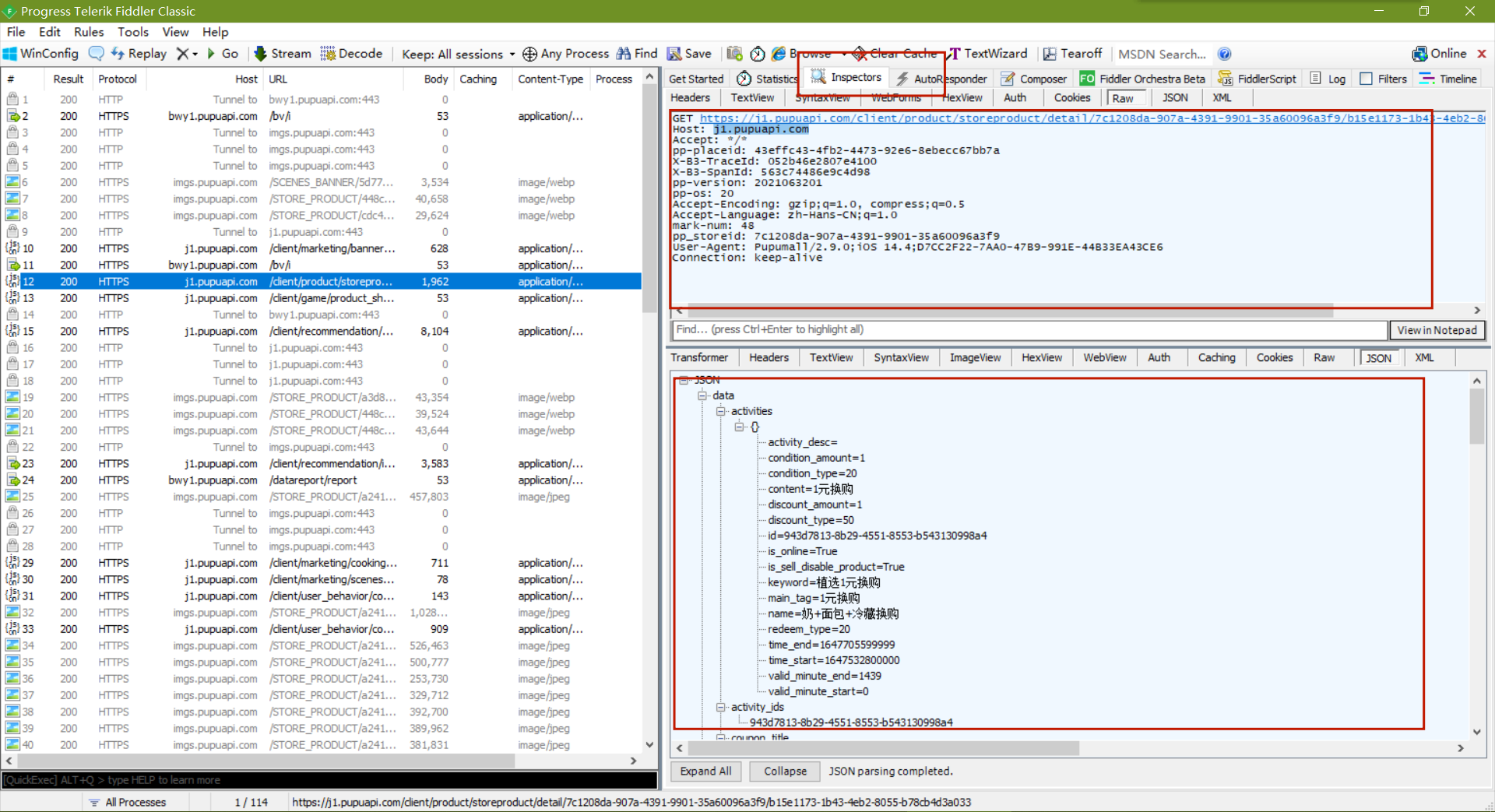
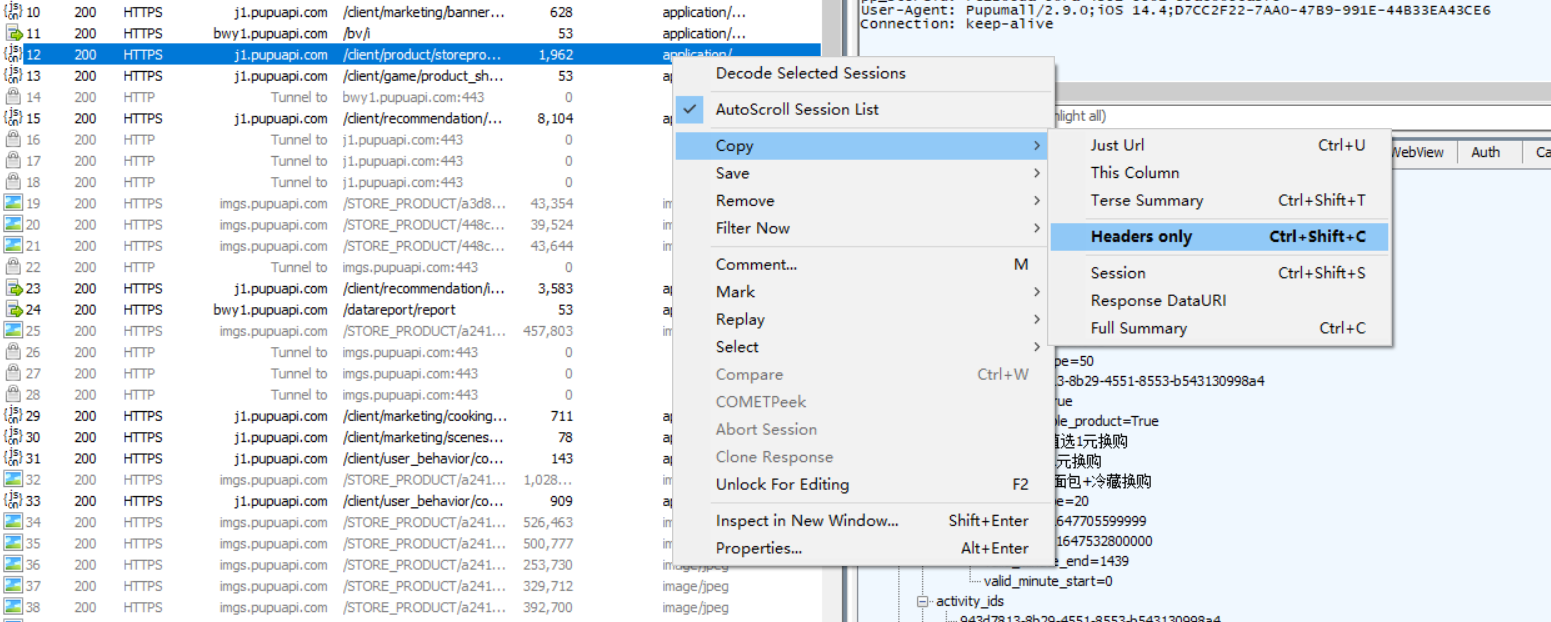
获取到信息
GET https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/b15e1173-1b43-4eb2-8055-b78cb4d3a033 HTTP/1.1
Host: j1.pupuapi.com
Accept: */*
pp-placeid: 43effc43-4fb2-4473-92e6-8ebecc67bb7a
X-B3-TraceId: 052b46e2807e4100
X-B3-SpanId: 563c74486e9c4d98
pp-version: 2021063201
pp-os: 20
Accept-Encoding: gzip;q=1.0, compress;q=0.5
Accept-Language: zh-Hans-CN;q=1.0
mark-num: 48
pp_storeid: 7c1208da-907a-4391-9901-35a60096a3f9
User-Agent: Pupumall/2.9.0;iOS 14.4;D7CC2F22-7AA0-47B9-991E-44B33EA43CE6
Connection: keep-alive
这些数据就是后续会用到的url和头部信息,观察Inspectors中json内容方便后续筛选需要的数据
python部分
1. 安装好pycharm
2. 新建demo.py文件,先写了一个静态输出数据的内容
import requests
def Get_json(url, headers):
req = requests.get(url=url, headers=headers).json()
return req
def screen(req):
str1=float(req['data']['price'])/100
data = {'name': req['data']['name'], # 商品名称
'spec': req['data']['spec'], # 商品含量
'price': str(str1), # 价格
'content': req['data']['share_content'] # 详细信息
}
return data
if __name__ == '__main__':
# 头部信息,用来模拟浏览器发送请求
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip;q=1.0, compress;q=0.5',
'Accept-Language': 'zh-Hans-CN;q=1.0',
'User-Agent': 'Pupumall/2.9.0;iOS 14.4;D7CC2F22-7AA0-47B9-991E-44B33EA43CE6',
'Connection': 'Keep-Alive',
'Host': 'j1.pupuapi.com'
}
# json文件路径
url = "https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/b15e1173-1b43-4eb2-8055-b78cb4d3a033"
# 存储json内容输出
data = screen(Get_json(url, headers))
print("------------------商品:" + data['name'] + "------------------")
print("规格:" + data['spec'])
print("价格:"+data['price'])
print("详细内容:"+data['content'])
静态输出数据的运行结果

requests包我的python中没有,需要导入,到文件目录中输入命令行pip install requests
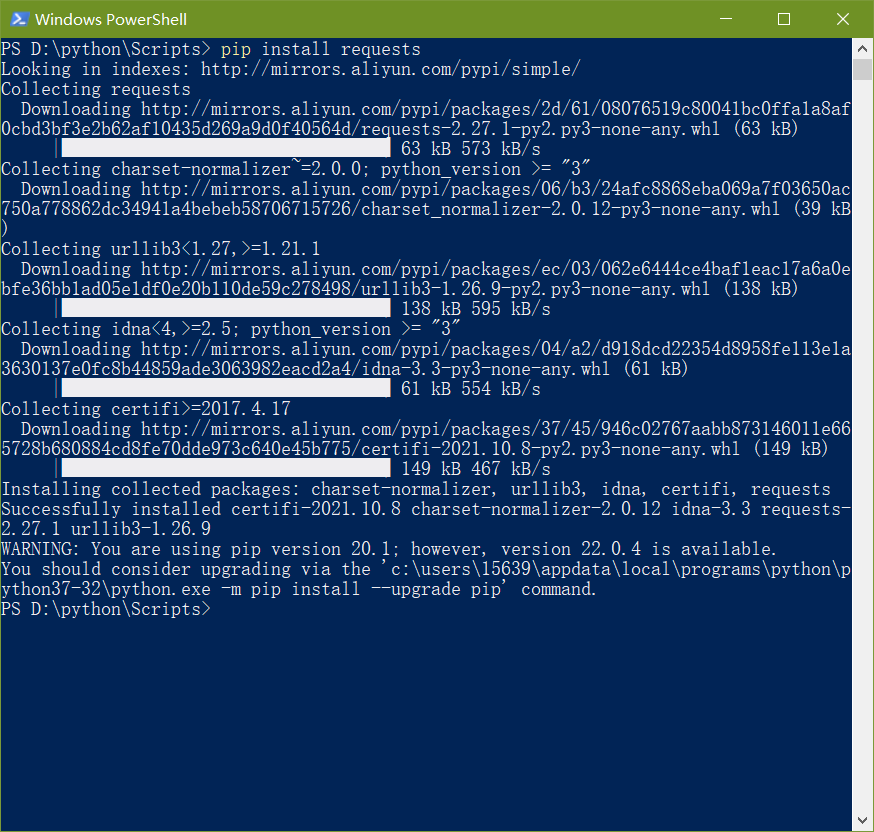
发现还是没办法使用,查了一下原因是下载到c盘了C:\Users\15639\AppData\Local\Programs\Python\Python37-32\Lib\site-packages
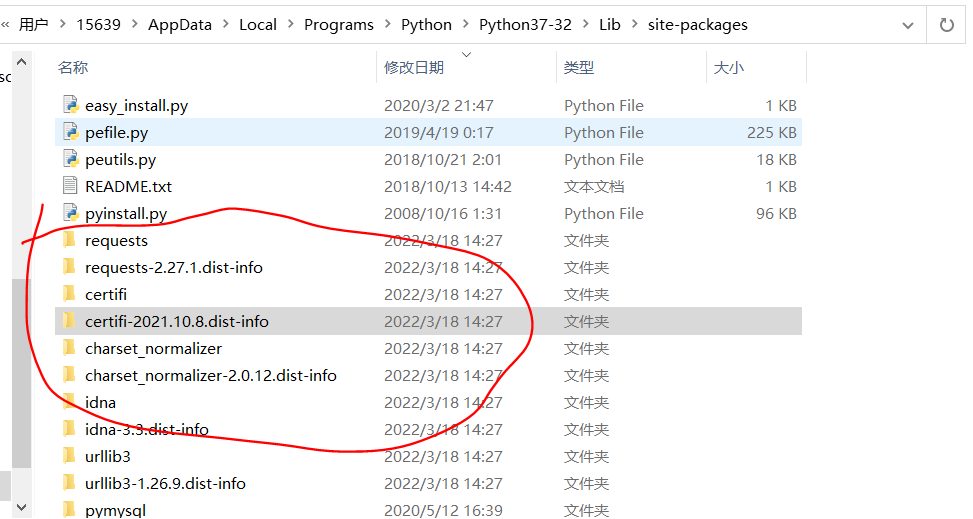
但是我python执行程序是D盘中的,所以将需要的包直接复制到对应目录就可以正常使用
3. 实时监控产品价格实现
实时也就是动态,我第一反应是使用延时处理,设置程序没隔一段时间去调用访问得到价格数据
def time_lapse(url, headers):
var = 1
while var == 1:
req=Get_json(url, headers)
time.sleep(2)
results ="当前时间为:"+time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) +",价格为" + str(float(req['data']['price'])/100)
print(results)
实时监控结果如下图

做到这里的时候感觉基本上满足作业需求,但是感觉自己代码还是有点“硬代码”,就为了完成功能很生硬的写出来,不是很规范,于是尝试优化,结果看来好像没什么变化,一时之间我也没什么头绪
优化:最终代码
import requests
import time
import random
# 获取数据
def Get_json(url, headers):
req = requests.get(url=url, headers=headers).json().get('data')
return req
# 处理数据
def screen(req):
price = float(req.get('price')) / 100
data = {'name': req.get('name'), # 商品名称
'spec': req.get('spec'), # 商品含量
'price': str(price), # 价格
'content': req.get('share_content') # 详细信息
}
return data
# 实时监控商品价格
def time_lapse(url, headers):
var = 1
while var == 1: # 无限循环实现动态
r = random.randint(1, 10) # 设置随机1~10秒
price = Get_json(url, headers).get('price') # 获取数据
time.sleep(r) # 延时
results = "当前时间为:" + time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) + ",价格为" + str(
float(price) / 100) # 显示结果
print(results)
if __name__ == '__main__':
# 头部信息,用来模拟浏览器发送请求
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip;q=1.0, compress;q=0.5',
'Accept-Language': 'zh-Hans-CN;q=1.0',
'User-Agent': 'Pupumall/2.9.0;iOS 14.4;D7CC2F22-7AA0-47B9-991E-44B33EA43CE6',
'Connection': 'Keep-Alive',
'Host': 'j1.pupuapi.com'
}
# json文件路径
url = "https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/b15e1173-1b43-4eb2-8055-b78cb4d3a033"
# 存储json内容输出
data = screen(Get_json(url, headers))
print("------------------商品:" + data['name'] + "------------------")
print("规格:" + data['spec'])
print("价格:" + data['price'])
print("详细内容:" + data['content'])
# 实时监控商品价格
print("------------------\"" + data['name'] + "\"的价格波动" "------------------")
time_lapse(url, headers)
三、git截图和github5次commit截图
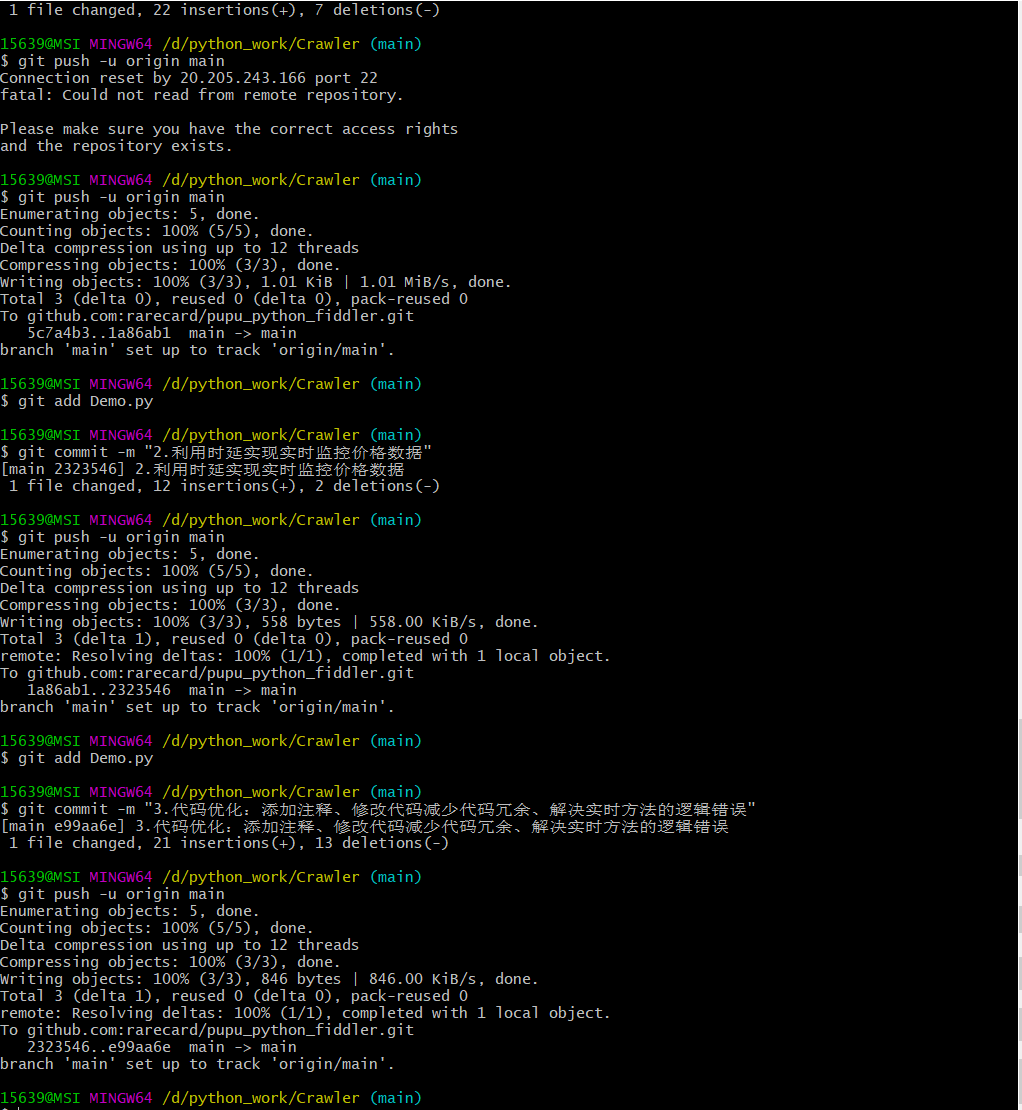
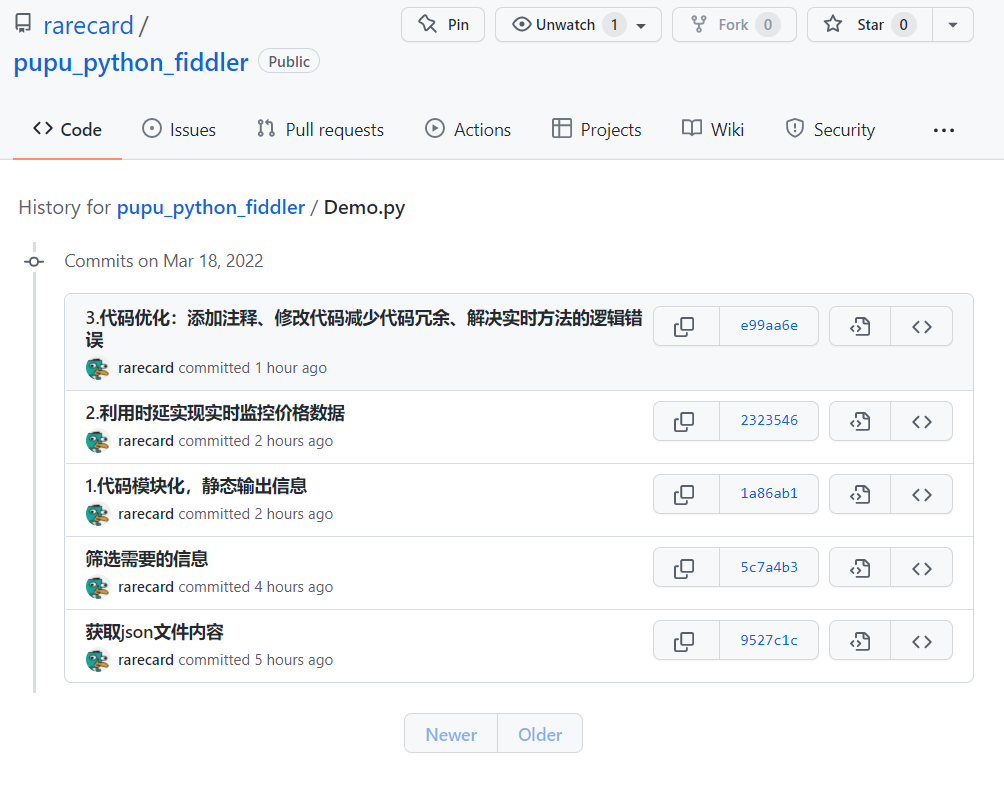
任务【选做】进阶:爬取自己的知乎收藏夹,以每个收藏夹的名称为大类,其下展示各个具体收藏文章的名称及其链接。
思路和抓取朴朴商品差不多,不一样的地方是在于对接收到的知乎收藏夹相关json数据的处理
先是建立收藏夹作为测试用例

然后使用fiddler获取该页面对应的json文件
编写代码,主要的处理方法,收藏夹分类
def screen_url(req):
list = []
for index in range(5):
urlDict = {}
urlDict['title'] = (req[index]['title'])#存储收藏夹名称
#存储收藏夹对应内容连接,为了下一次使用该链接进行抓包,修改关键字
urlDict['url'] = req[index]['url'].replace("api.zhihu.com/collections",
"www.zhihu.com/api/v4/collections") + "/items?offset=0&limit=20"
list.append(urlDict)
return list
第一次处理收藏夹数据结果图

第二次处理数据显示文章名字和链接
def screen_content(list):
list1 = []
for index in range(5):
list_url = []
str1 = list[index]['url'] # 前面抓取的收藏夹对应链接
list_all = Get_json(str1, headers) # 使用收藏夹链接
# 循环查找收藏夹内对应的标题
for url in range(6):
conDict = {}
# 因为有些内容的标题在question中,所以要简单判断一下
if 'question' in list_all[url]['content']:
conDict['title'] = list_all[url]['content']['question']['title']
else:
conDict['title'] = list_all[url]['content']['title']
conDict['url'] = list_all[url]['content']['url']
list_url.append(conDict)
list1.append(list_url)
return list1
知乎收藏夹抓取完成效果图

知乎收藏夹完整代码
import requests
import json
# 获取数据
def Get_json(url, headers):
req = requests.get(url=url, headers=headers).json()
return req
# 处理数据
def screen_url(req):
data = json.dumps(req, indent=1,ensure_ascii=False) # 输出到json文件
f = open('favorite.json', 'w+',encoding="utf-8",newline='\n')
f.write(data)
req = req.get('data')
list = []
for index in range(5):
urlDict = {}
urlDict['title'] = (req[index]['title']) # 存储收藏夹名称
# 存储收藏夹对应内容连接,为了下一次使用该链接进行抓包,修改关键字
urlDict['url'] = req[index]['url'].replace("api.zhihu.com/collections",
"www.zhihu.com/api/v4/collections") + "/items?offset=0&limit=20"
list.append(urlDict)
return list
def screen_content(list):
list1 = []
for index in range(5):
list_url = []
str1 = list[index]['url'] # 前面抓取的收藏夹对应链接
list_all = Get_json(str1, headers).get('data') # 使用收藏夹链接
data = json.dumps(list_all, indent=1,ensure_ascii=False) # 循环输出到json文件
f = open(list[index]['title'] + '.json', 'w+',encoding="utf-8", newline='\n')
f.write(data)
# 循环查找收藏夹内对应的标题和链接
for url in range(6):
conDict = {}
# 因为有些内容的标题在question中,所以要简单判断一下
if 'question' in list_all[url]['content']:
conDict['title'] = list_all[url]['content']['question']['title']
else:
conDict['title'] = list_all[url]['content']['title']
conDict['url'] = list_all[url]['content']['url']
list_url.append(conDict)
list1.append(list_url)
return list1
if __name__ == '__main__':
headers = {
'Accept': '* / *',
'Accept - Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'x-requested-with': 'x-requested-with',
'Connection': 'keep-alive',
'Host': 'www.zhihu.com'
}
url = "https://www.zhihu.com/api/v4/people/fei-chai-xi-xie-gui-29/collections?include=data%5B*%5D.updated_time%2Canswer_count%2Cfollower_count%2Ccreator%2Cdescription%2Cis_following%2Ccomment_count%2Ccreated_time%3Bdata%5B*%5D.creator.vip_info&offset=0&limit=20"
list = screen_url(Get_json(url, headers))
list1 = screen_content(list)
# 循环输出需要的内容
for i in range(5):
print(list[i]['title'])
for j in range(6):
print(list1[i][j]['title'])
print(list1[i][j]['url'])
导出的json文件内容
因为想着方便测试抓取,所以文件夹和内容都是固定值,理论上来说应该是要做一个内容数量的判断,也是我短时间想到的优化点,有时间的话再进行修改
四、总结
- 这次的作业我虽然花费了很多时间研究和查资料,但是完成程度和我心中的目标还是有些差距,我对自己还是很不满意的,其中主要的问题是在于查找问题解决,也就是调试能力,我在专科的时候其实已经体验过这种感受了,对这种感受最大的感想其实是需要理论体系的支撑,很多时候解决问题的能力无非就是比别人想的多、想的广、有耐心、有经验,排除了所有不正确的答案,剩下的那个唯一便是触手可得,在我的理解里如何有更广阔的思考,那就是学习,学什么呢,学工具的使用虽然很重要,可以帮助我积累错误经验,可是我认为更重要的是理论基础,只有在理解的层面上才能举一反三,一通百通。而我在这方面,也就是理论基础支撑方面还是太薄弱了,也正是我为什么会花费这么多时间的原因。代码方面也是,深刻的意识到自己和别人的差距有多大,不过学无止境,以后再接再厉吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号