BUAA OO 第一单元总结
(1)第一次作业
基本度量:

总体上规模较好。
内聚和耦合:

可以看出Polynomial的耦合度较高。
类图:
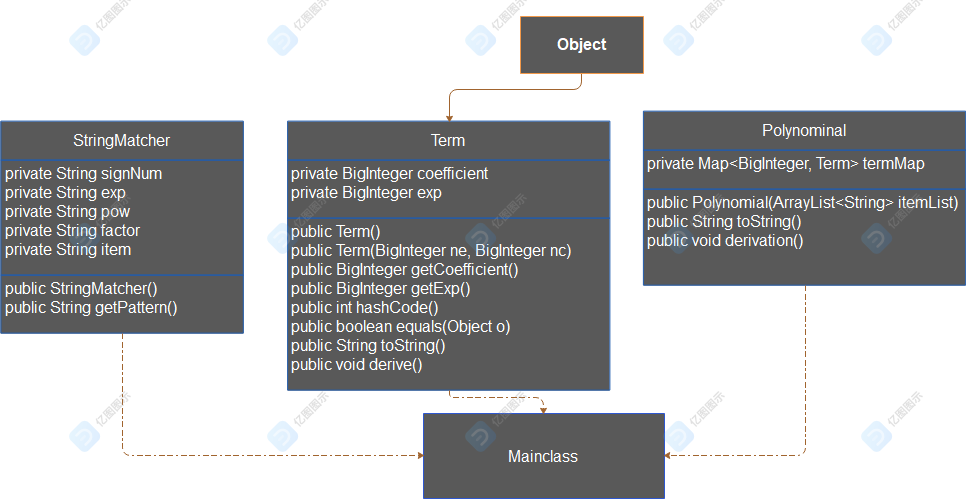
StringMatcher类用于生成用于匹配的正则表达式
Object类为抽象类
Term类为项类
Polynomial类为多项式类,其中定义了一个私有的hashmap用于存放项
类中方法作用显而易见,故此处不做赘述
程序通过StringMatcher生成正则表达式匹配输入然后传入Polynomial进行解析,调用toString获得输出。
优点:对输出进行了化简,代码简单易懂。
缺点:移植性极差。
· 分析bug
中测,强测以及互测均未发现错误。
· 分析如何发现他人bug
策略:利用Python通过正则表达式随机生成输入然后对每一个同学进行自动化测试,并通过Python自带的求导进行验证。
Hack结果:0次。
并未结合被测程序代码设计结构。
(2)第二次作业
· 基于度量的分析
基本度量:
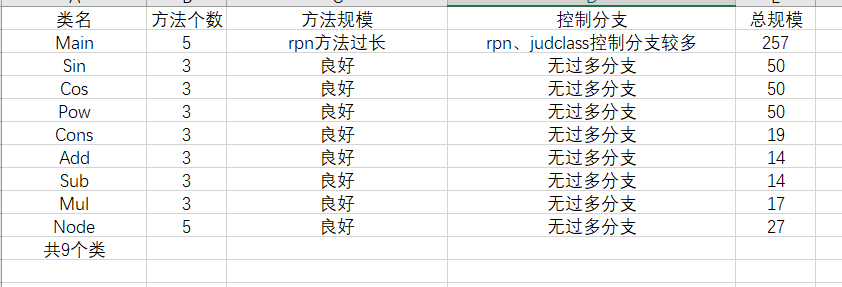
Main中生成后缀表达式的相关方法过长,且控制分支很多。
内聚和耦合:
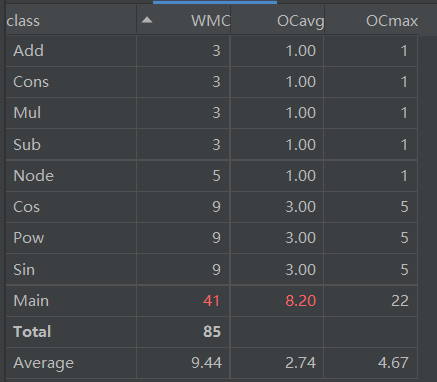
由于大部分代码都在Main中实现,故main函数调用了除自身外的所有类,耦合度很高
类图:
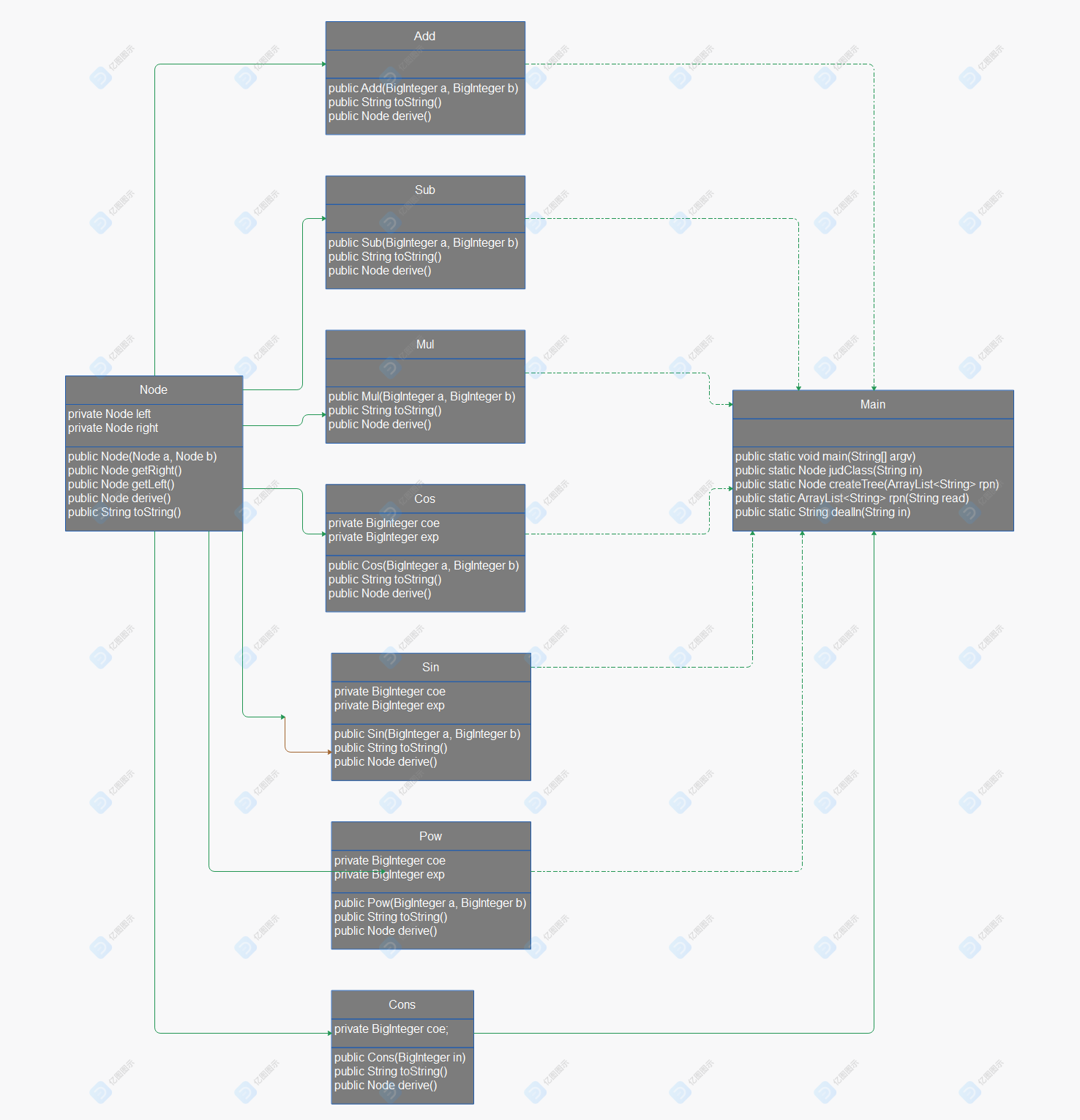
Node为树的结点类,且是所有因子类和运算类的父类,实现了用于求导的derive和用于输出的toString
Add,Sub,Mul类是运算类
Cons,Pow,Sin,Cos类是因子类
Main是主类
其中JudClass是将String对象转换为因子对象的方法,其余方法作用显而易见。
程序通过Main中的dealIn的方法处理输入,利用rpn方法生成后缀表达式(此时返回为String的可变数组)。通过rpn的返回值调用createTree方法建树,在过程中,利用judClass对每一个String进行分析,并建立相应的因子、运算对象。生成的表达式树递归调用继承自父类的derive方法,最后返回导数表达式树的根节点,再通过调用toString方法生成最后的表达式。
优点:便于移植。
缺点:代码过于面向过程,且部分代码过于冗长没有封装导致debug十分困难。
· 分析bug
在强测和互测中发现了后缀表达式生成时的错误:当遇到运算符时,没有将与之优先级相同的运算符弹出,问题存在于Main中rpn方法。
由于仅是>和≥的区别,代码行和圈复杂度上差异不明显。
· 分析如何发现他人bug
策略:通过阅读他人代码查找bug(这次的嵌套不太会写正则表达式)。
Hack结果:16次/63次。
并未结合被测程序代码设计结构。
(3)第三次作业
· 基于度量的分析
基本度量:

在Parser类中为了识别格式错误写入了大量的控制分支,此外,judClass和Rpn方法也由于控制分支过多导致规模较大。
内聚和耦合:
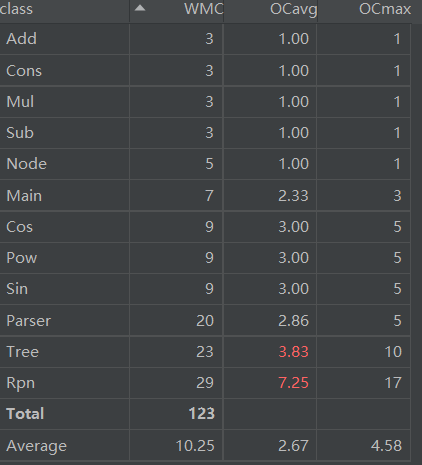
耦合度总体上较第二次作业略有下降,主要原因是将Main中的一些方法单独封装成了类。
类图:
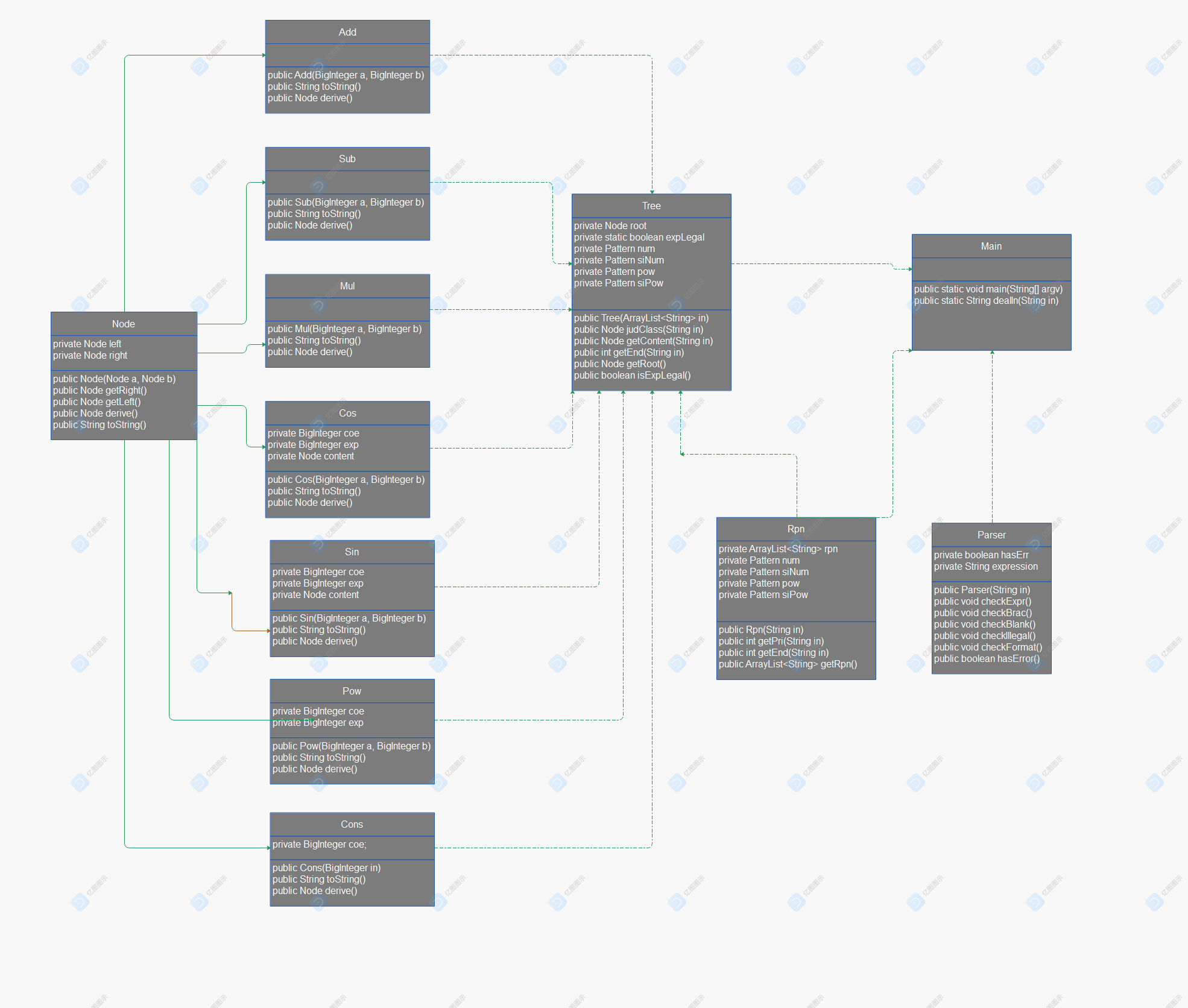
Node为树的结点类,且是所有因子类和运算类的父类,实现了用于求导的derive和用于输出的toString
Add,Sub,Mul类是运算类
Cons,Pow,Sin,Cos类是因子类,其中Sin和Cos类中定义了一个Node用于存放可能存在的嵌套内容(该部分内容一样建成表达式树)
Parser类实现格式检查
Rpn类实现后缀表达式的生成,其中getPri用于获取操作符优先级,getEnd用于获取三角函数最外层括号结束的位置,getRpn返回我们生成的后缀表达式
Tree类实现后缀表达式树的建立,judClass实现String变因子的功能,getContent用于获取三角函数的Node,isExplegal用于判断是否所有指数绝对值都小于等于50(作为格式审查的一部分)
Main是主类
读入字符串后首先调用Parser类进行格式检查的第一阶段。若检查无误,则利用Rpn生成后缀表达式(此时返回为String的可变数组),然后利用Tree建立表达式树。在建树过程中,可以实现对于指数的格式检查。若格式检查无误,则使生成的表达式树递归调用继承自父类的derive方法,最后返回导数表达式树的根节点,再通过调用toString方法生成最后的表达式。
优点:便于理解
缺点:格式审查和求导严重割裂,面向过程的思想仍很严重。
· 分析bug
通过强测和互测查出了若干bug:三角函数的紧前符号只处理了‘-’,指数格式审查时未加绝对值,由于格式错误导致不能建树出现的RE,三角函数的toString缺少一对括号,格式审查部分情况没有考虑。
修改后代码行数增加了不到10行,但圈复杂度减少了。
· 分析如何发现他人bug
策略:通过利用Python随机构造数据,把同Room的人打包成jar包一起对拍。
Hack结果:4次/7次
并未结合被测程序代码设计结构。
(4)重构经历总结
笔者是在第二次作业中进行了重构。由于第一次作业相对而言易于实现,故采用了极为面向过程的写法。而第二次作业加入了表达式因子和三角函数因子,不仅求导法则改变了,还出现了嵌套这个大麻烦,别无他法,只能重构。在重构时,出于题目需求和可移植性的考量,笔者选择建立表达式树来处理输入,故我们需要建立树的结点类。对于每种基本因子建立各自的类构成表达式树的叶子结点,对于每种操作建立相应的类构成表达式树的非叶子节点。这样一来,只需要实现结点的求导就可以实现表达式的求导,求导的返回值仍是结点,可拓展性较好,最后求导返回的结点通过调用toString方法得到最后的输出。
由于第二次作业良好的可拓展性,在处理三角函数的新增需求时十分轻松,只需要把sin和cos类看成是一种操作即可(此时,sin和cos类不再能作为叶子结点)。与笔者而言,第三次作业的主要难点在于格式审查,本人采用分而治之的方法对于可能出现的错误进行分类,然后利用面向过程的思想实现了格式审查。
(5)心得体会
第一单元的作业对笔者来说是个很大的挑战,但通过作业,我能在代码的重构中实现自我能力的不断迭代,也算是收获颇丰。我本单元的成绩不太理想,除了第一次作业都是在50分左右,这反映出了我能力的不足。虽然成绩不尽人意,但是我仍从本单元任务的实现过程中感受到了成就感,从周三周四的毫无头绪,到周五周六的交流和爆肝,第二次作业确实让我感受到了解决问题的快乐。本次作业给我带来的最大的收获,可能就是需求分析,设计架构等一系列意识的初步形成。我开始有意识的去分析解构,而不是一拿到需求就去开始乱写,个人认为算是自己的提升吧。此外,为了准备互测,我也初步掌握了python自动评测机的写法,学会了怎么对拍(虽然我的数据总是很弱)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号