⽇志收集介绍
⽇志收集
项⽬背景
每个业务系统都有⽇志,当系统出现问题时,需要通过⽇志信息定位和解决问题。 当系统机器⽐较少 时,登陆到服务器上查看即可满⾜ 当系统机器规模巨⼤,登陆到机器上查看⼏乎不现实(分布式的系 统,⼀个系统部署在⼗⼏台机器上)
解决⽅案 把机器上的⽇志实时收集,统⼀的存储到中⼼系统。 在对这些⽇志建⽴索引,通过搜索即可快速找到对 应的⽇志记录 通过提供⼀个界⾯友好的web⻚⾯实现⽇志检索与展示。 ⾯临的问题 实时⽇质量⾮常⼤,每天处理⼏⼗亿条。 ⽇志准实时收集,延迟控制在分钟级别。 能够⽀持⽔平扩 展。
业界⽅案
ELK
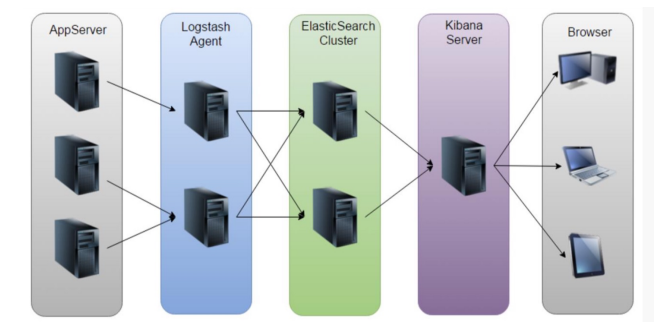
ELK⽅案的问题:
-
运维成本⾼,每增加⼀个⽇志收集项,都需要⼿动修改配置。
-
监控缺失,⽆法准确获取logstash的状态。
-
⽆法做到定制化开发与维护。
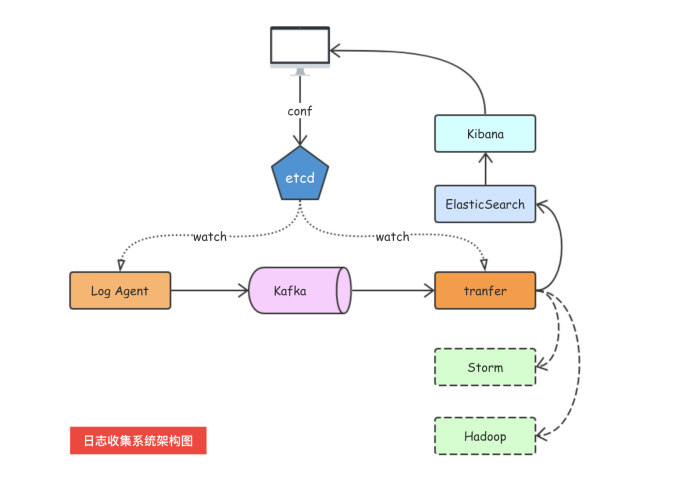
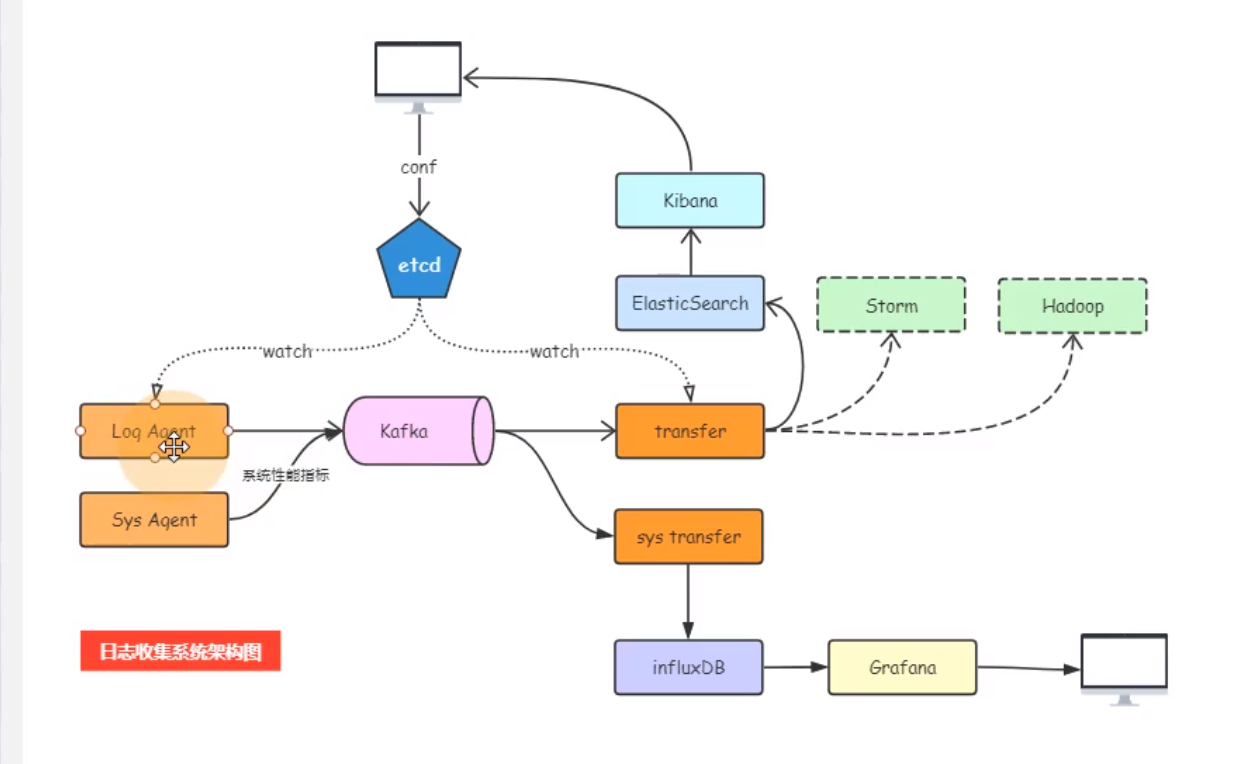
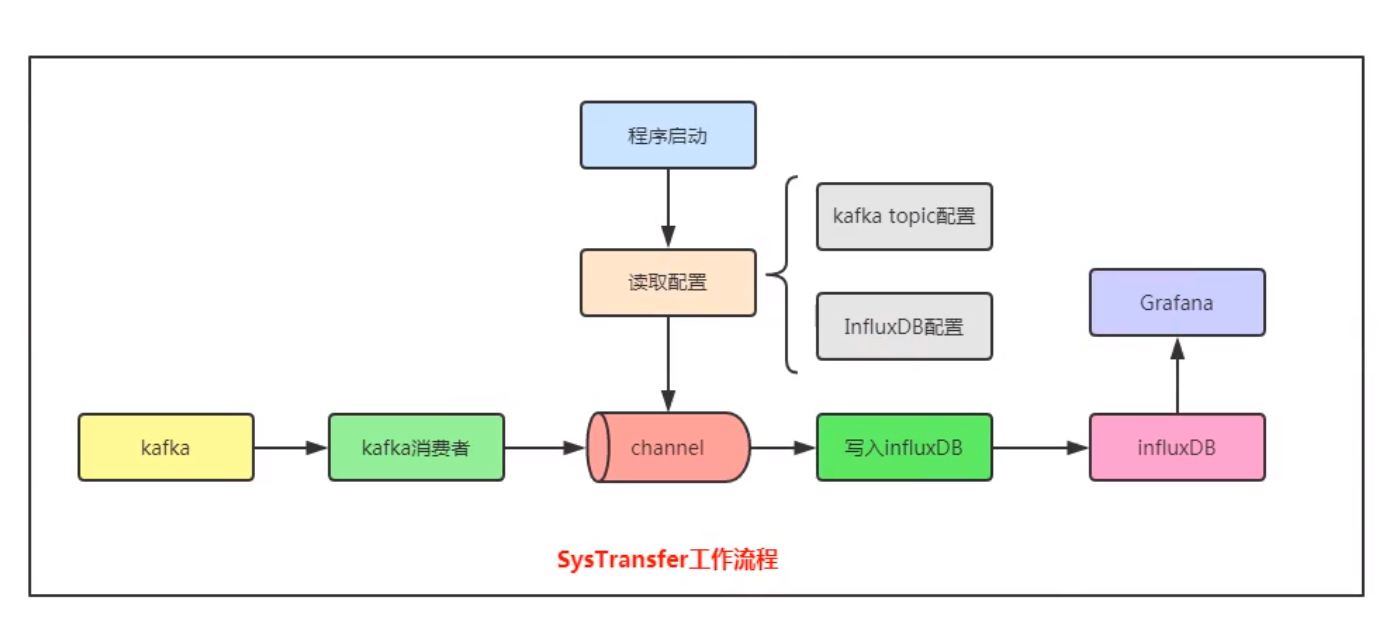
⽇志收集系统架构设计
架构设计
组件介绍
LogAgent:⽇志收集客户端,⽤来收集服务器上的⽇志。 Kafka:⾼吞吐量的分布式队列(Linkin开 发,apache顶级开源项⽬) ElasticSearch:开源的搜索引擎,提供基于HTTP RESTful的web接⼝。 Kibaba:开源的ES数据分析和可视化⼯具。 Hadoop:分布式计算框架,能够对⼤量数据进⾏分布式处 理的平台。 Storm:⼀个免费并开源的分布式实时计算系统。
将学到的技能
- 服务端agent开发
- 后端服务组件开发
- Kafka和zookeeper的使⽤ E
- S和Kibana的使⽤
- etcd的使⽤
消息队列的通信模型
点对点模式(queue)
消息⽣产者⽣产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。 ⼀条消息被消费 以后,queue中就没有了,不存在重复消费。
发布/订阅(topic)
消息⽣产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点⽅式 不同,发布到topic的消息会被所有订阅者消费(类似于关注了微信公众号的⼈都能收到推送的⽂章)。
补充:发布订阅模式下,当发布者消息量很⼤时,显然单个订阅者的处理能⼒是不⾜的。实际上现实场 景中是多个订阅者节点组成⼀个订阅组负载均衡消费topic消息即分组订阅,这样订阅者很容易实现消费 能⼒线性扩展。可以看成是⼀个topic下有多个Queue,每个Queue是点对点的⽅式,Queue之间是发 布订阅⽅式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号