



深度学习(一)
深度学习(一)
学习内容:
1.观看了神经网络的教学视频、pytorch的使用视频、使用keras框架训练mnist视频,初步了解神经网络以及经典训练模型
2.阅读群文件入门资料pdf,加深对于神经网络以及卷积神经网络的理解
3.根据博客以及视频内容安装anaconda、pytorch、以及所需要的库(numpy、tensorflow、keras.....)初步配置所需要的运行环境
4.阅读代码并且参考LetNet-5模型使用keras框架和torch框架训练mnist
5.学习阅读pytorch官方文档查看函数参数以及相关信息
代码:
- keras框架:
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import RMSprop
from keras import models,layers,regularizers
from keras.datasets import mnist
import matplotlib.pyplot as plt
# 加载数据集
(train_images, train_labels),(test_images,test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28,28,1)).astype('float')/255
test_images = test_images.reshape((10000, 28,28,1)).astype('float')/255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
def LeNet5():
network = models.Sequential()
network.add(layers.Conv2D(filters=6,kernel_size=(3,3),activation='relu',input_shape=(28, 28, 1),kernel_regularizer=regularizers.l1(0.0001)))
network.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
network.add(layers.Dropout(0.01))
network.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu'))
network.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
network.add(layers.Dropout(0.01))
network.add(layers.Conv2D(filters=120, kernel_size=(3, 3), activation='relu'))
network.add(layers.Flatten())
network.add(layers.Dense(84,activation='relu'))
network.add(layers.Dropout(0.01))
network.add(layers.Dense(10, activation='softmax'))
return network
network = LeNet5()
#编译步骤
network.compile(optimizer=RMSprop(lr=0.001),loss='categorical_crossentropy',metrics=['accuracy'])
#训练网络,用fit函数,epochs表示训练多少个回合, batch_size表示每次训练给多大的数据包
network.fit(train_images, train_labels, epochs=20, batch_size=120, verbose=2)
# print(network.summary())
test_loss, test_accuracy = network.evaluate(test_images, test_labels)
print("test_loss:",test_loss," test_accuracy:",test_accuracy)
-
结果:
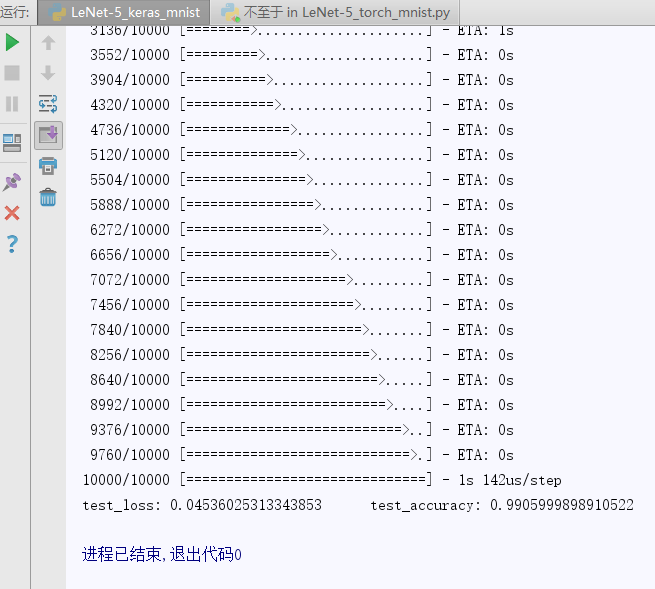
-
torch框架:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
#参数设置
batch_size = 4 # 批次大小
EPOCHS=20 # 总共训练批次
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 让torch判断是否使用GPU,建议使用GPU环境,因为会快很多
total_train_step = 0
total_test_step=0
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.5,), (0.5,)), # 归一化
])
train_dataset = torchvision.datasets.MNIST(root='./MNIST_data', train=True, transform=transform, download=True)
test_dataset = torchvision.datasets.MNIST(root='./MNIST_data', train=False, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
#搭建神经网络
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self,x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1) # 展开成一维的
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
#创建网络模型
model = ConvNet().to(DEVICE)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # 优化器
#添加tensorboard
writer = SummaryWriter("logs")
def train(model, device, train_loader, optimizer, epoch, total_train_step):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
#输入数据
data, target = data.to(device), target.to(device)
#梯度清零
optimizer.zero_grad()
output = model(data)
#损失函数
loss = criterion(output, target)
loss.backward()
#更新参数
optimizer.step()
#输出训练结果
total_train_step = total_train_step + 1
if (batch_idx + 1) % 1000 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
writer.add_scalar("train_loss",loss.item(),)
def test(model, device, test_loader, total_test_step):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # 将一批的损失相加
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
writer.add_scalar("test_loss", test_loss, total_test_step)
writer.add_scalar("test_loss", correct / len(test_loader.dataset), total_test_step)
total_test_step = total_test_step + 1
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch, total_train_step)
test(model, DEVICE, test_loader,total_test_step)
writer.close()
- 结果:
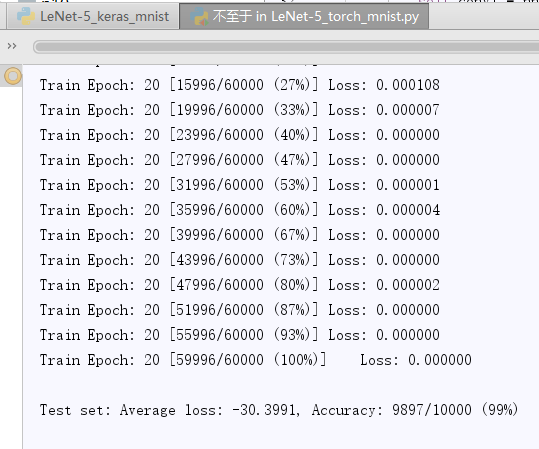
遇到的问题(开始翻看浏览记录):
配置安装方面:
(1)第一次尝试通过anaconda利用官网的conda指令安装pytorch,安装过程中有几个下的非常慢甚至下载失败,后来根据博客找到清华的镜像源下载,成功下载,但是下载的版本不配(当时没有找到匹配的版本,但刚好发现了pip的下载方式
(2)第二次尝试通过pip方式下载,速度非常快,但发现win里的python是3.8版本的(太高了)于是重新安装python3.6.0
(3)在使用keras时,发现python要在3.6.2以上,于是又重新装了3.6.4版本(还错装过win32版本的,发现什么库都下不了,[Error 193] %1 is not a valid Win32 application in Python)
(4)tensorflow中没有examples,tensorflow2.0没有examples
(5)发现keras和tensorflow也存在版本匹配问题,于是就重装重装....
(6)可以运行了,但还是存在不匹配问题
代码方面:
(1)先是使用keras框架,然后是torch,发现keras训练的很快,代码也很简单,yeah
(2)maxpooling和avgpooling的区别:
average-pooling能减小邻域大小受限造成的估计值方差增大,更多的保留图像的背景信息
max-pooling能减小卷积层参数误差造成估计均值的偏移更多的保留纹理信息
一开始使用的是average-pooling,后面发现max-pooling可以让准确率更高点
(3)transforms.ToTensor():在载入数据的时候要统一将PIL.Image或者numpy.narray数据类型转变为torch.FloatTensor类型
(4)batch_size不应设置过大,否则可能报错RuntimeError: CUDA error
(5)结果中存在过拟合问题(训练集的准确率(99.8)比测试集的准确率高(99.0))
解决策略:1.数据集扩增 2.正则化方法(l1、l2都有使用过,感觉对于mnist差别不大)3.Dropout(有使用到,推荐设置参数为0.5,随机生成的网络最多)
(6)报错:IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 10)
构建网络出错,维度上错了
相似错误:
mat1 and mat2 shapes cannot be multiplied ( )
(7)使用tensorboard可视化时,保存的log不会更新,要将原先的log删除
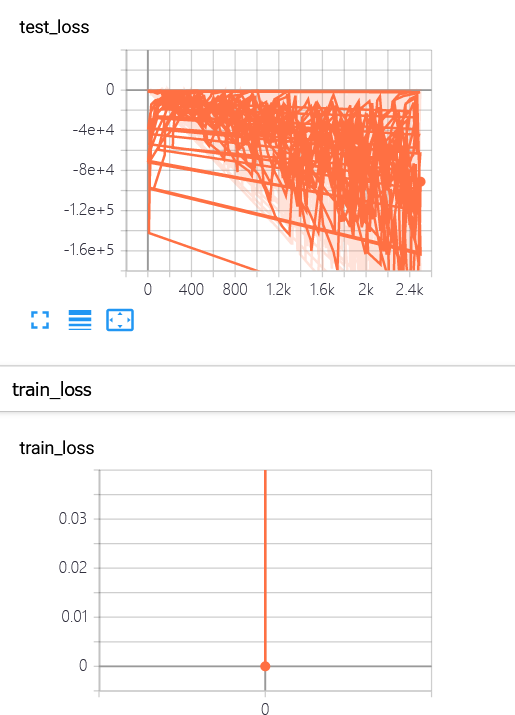
以及语句插入的位置不太对,应该放在外层循环中
(8) model.train()和model.eval()的区别主要在于Batch Normalization和Dropout两层。如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
(9) loss为什么出现负数,连续型的交叉熵是-\int p(x)log q(x) dx,它是可以为负的,或者是它太小了?
(10) pytorch.nn.Conv2d如何计算输出特征图尺寸

总结:
通过修改神经网络结构,可以达到最高正确率在99.2%(好像有99.3%的,但没有截图)

总的来说在配置环境上花费了很多的时间,这玩意真的难装,然后就是学习完理论知识后和实际操作比起来会有点区别,还是通过查看他人代码解析来一步步理清楚训练的过程的,对于层于层之间的输入输出的计算还要继续学习以及过拟合问题的解决,对于优化器和损失函数没有深入的研究,tensorboard可视化的部分运用的也不太熟练,对于torch的使用还有很大的欠缺,希望能进一步学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号