
1.Spark SQL出现的原因是什么?
Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来。这个方法使得Shark的用户可以加速Hive的查询,但是Shark继承了Hive的大且复杂的代码使得Shark很难优化和维护,同时Shark依赖于Spark的版本。随着我们遇到了性能优化的上限,以及集成SQL的一些复杂的分析功能,我们发现Hive的MapReduce设计的框架限制了Shark的发展。在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。
1.内存列存储–可以大大优化内存的使用率,减少内存消耗,避免GC对大量数据性能的开销
2.字节码生成技术–可以使用动态 的字节码技术优化性能
3.Scala代码的优化
2.用spark.read创建DataFrame
从TXT文件创建:spark.read.txt(url)
从JSON文件创建:spark.read.json(url)
从CSV文件创建:spark.read.format("com.databricks.spark.csv.DefaultSource15").option"delimiter", ",").load(url)
从MySQL数据表创建:spark.read .format("jdbc") .option("url", "xxx") .option("dbtable", "xxx") .option("user", "xxx") .option("password", "xxx") .load()
3.观察从不同类型文件创建DataFrame有什么异同?
- 共同点:在创建 Data Frame 时,都可以使用spark.read 操作,实现从不同类型的文件中加载数据创建DataFrame。
- 不同点:
- spark.read.text("people.txt"):读取文本文件 people.txt
- spark.read.json("people.json"):读取 JSON 文件
- spark.read.parquet("people.parquet"):读取 Parquet 文件
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
Spark的DataFrame是基于RDD实现的,一个以命名列方式组织的分布式数据集。实际存储与RDD一致,基于行存储。Spark框架本身不了解RDD数据的内部结构,而DataFrame提供了详细的结构信息,Spark DataFrame将数据以单独表结构,分散在分布式集群的各台机器上,所以Spark Dataframe是天然的分布式表结构。
Python Pandas的DataFrame是一种表格型数据结构,按照列结构存储,它含有一组有序的列,每列可以是不同的值,但每一列只能有一种数据类型,DataFrame 既有行索引,也有列索引。
Spark SQL DataFrame的基本操作
创建:
spark.read.text()

spark.read.json()

打印数据
df.show()默认打印前20条数据,df.show(n)
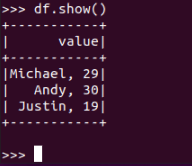
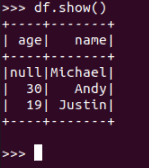
打印概要
df.printSchema()
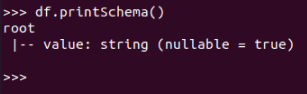
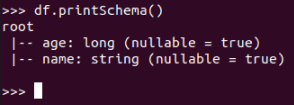
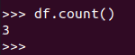
查询总行数
df.count()
df.head(3) #list类型,list中每个元素是Row类


输出全部行
df.collect() #list类型,list中每个元素是Row类


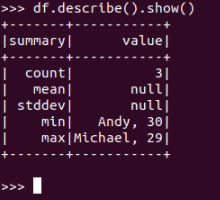
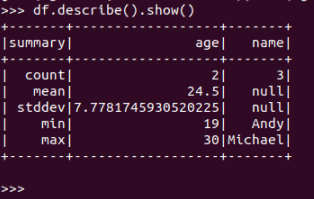
查询概况
df.describe().show()
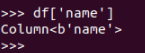
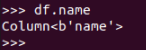
取列
df[‘name’]
df.name
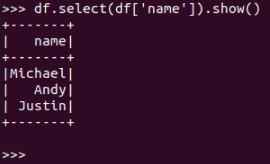
df.select()
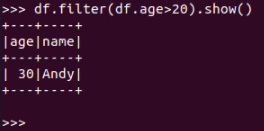
df.filter()
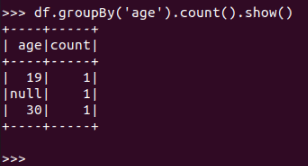
df.groupBy()
df.sort()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号