Collection土办法丶
集合框架
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。
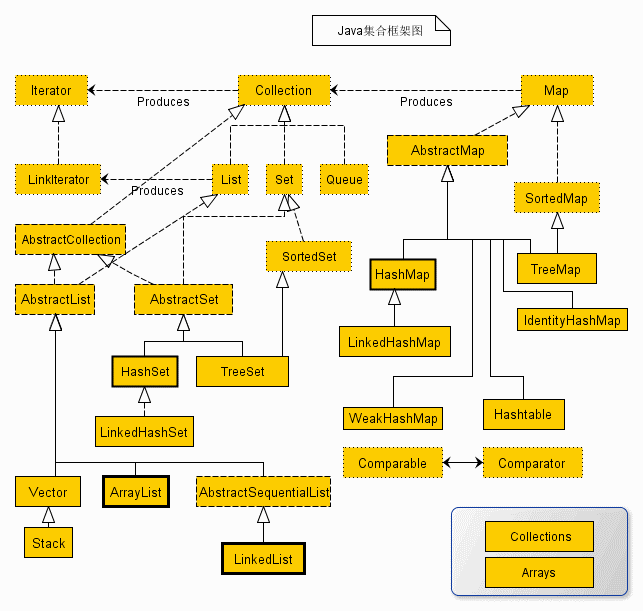
大概情况就是:各种集合类继承各种抽象类,实现各种接口;各种数据结构进行存储;各种算法进行排序和搜索。
集合接口
| 接口 | 关键词丶印象 |
|---|---|
| List | 允许有相同的元素。List 接口存储一组不唯一,有序(插入顺序)的对象。List和数组类似,可以动态增长。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector> 。 |
| Set | Set 不保存重复的元素。Set 接口存储一组唯一,无序的对象。Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet> |
| SortedSet | 继承于Set保存有序的集合。 |
| Map | Map 接口存储一组键值对象,提供key(键)到value(值)的映射。 |
| Map.Entry | 描述在一个Map中的一个元素(键/值对)。是一个Map的内部类。 |
| SortedMap | 继承于 Map,使 Key 保持在升序排列。 |
集合实现类
一些是抽象类,提供了接口的部分实现。
- AbstractCollection 实现了大部分的集合接口。
- AbstractList 继承于AbstractCollection 并且实现了大部分List接口。
- AbstractSequentialList 继承于 AbstractList ,提供了对数据元素的链式访问而不是随机访问。
- LinkedList 该类实现了List接口,允许有null(空)元素。主要用于创建链表数据结构,该类没有同步方法,如果多个线程同时访问一个List,则必须自己实现访问同步,解决方法就是在创建List时候构造一个同步的List。例如:
List list=Collections.synchronizedList(newLinkedList(...));LinkedList 查找效率低。 - ArrayList 该类也是实现了List的接口,实现了可变大小的数组,随机访问和遍历元素时,提供更好的性能。该类也是非同步的,在多线程的情况下不要使用。ArrayList 增长当前长度的50%,插入删除效率低。
- AbstractSet 继承于AbstractCollection 并且实现了大部分Set接口。
- HashSet该类实现了Set接口,不允许出现重复元素,不保证集合中元素的顺序,允许包含值为null的元素,但最多只能一个。
- LinkedHashSet 具有可预知迭代顺序的
Set接口的哈希表和链接列表实现。 - TreeSet 该类实现了Set接口,可以实现排序等功能。
- AbstractMap 实现了大部分的Map接口。
- HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。 该类实现了Map接口,根据键的HashCode值存储数据,具有很快的访问速度,最多允许一条记录的键为null,不支持线程同步。
- TreeMap 继承了AbstractMap,并且使用一颗树。
- WeakHashMap 继承AbstractMap类,使用弱密钥的哈希表。
- LinkedHashMap 继承于HashMap,使用元素的自然顺序对元素进行排序.
- IdentityHashMap 继承AbstractMap类,比较文档时使用引用相等。
java.util包中
| 类名 | 类描述 |
|---|---|
| Vector | Vector 该类和ArrayList非常相似,但是该类是同步的,可以用在多线程的情况,该类允许设置默认的增长长度,默认扩容方式为原来的2倍。 |
| Stack | Stack 栈是Vector的一个子类,它实现了一个标准的后进先出的栈。 |
| Dictionary | Dictionary 类是一个抽象类,用来存储键/值对,作用和Map类相似。 |
| Hashtable | Hashtable 是 Dictionary(字典) 类的子类,位于 java.util 包中。不允许存null |
| Properties | Properties 继承于 Hashtable,表示一个持久的属性集,属性列表中每个键及其对应值都是一个字符串。 |
| BitSet | 一个Bitset类创建一种特殊类型的数组来保存位值。BitSet中数组大小会随需要增加。 |
迭代器
一般遍历数组都是采用for循环或者增强for,这两个方法也可以用在集合框架,但是还有一种方法是采用迭代器遍历集合框架,它是一个对象,实现了 Iterator 接口或 ListIterator(以允许双向遍历列表和修改元素)接口。
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("World");
list.add("HAHAHAHA");
//第一种遍历方法使用 For-Each 遍历 List
for (String str : list) { //也可以改写 for(int i=0;i<list.size();i++) 这种形式
System.out.println(str);
}
//第二种遍历,把链表变为数组相关的内容进行遍历
String[] strArray = new String[list.size()];
list.toArray(strArray);
for (int i = 0; i < strArray.length; i++) //这里也可以改写为 for(String str:strArray) 这种形式
{
System.out.println(strArray[i]);
}
//第三种遍历 使用迭代器进行相关遍历(长度变了也不担心)
Iterator<String> ite = list.iterator();
while (ite.hasNext())//判断下一个元素之后有值
{
System.out.println(ite.next());
}
}
}
遍历Map
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= " + key + " and value= " + map.get(key));
}
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
//第五种
System.out.println("lambda表达式");
map.forEach((key, value) -> System.out.println("key= " + key + " and value= " + value));
}
}
ArrayList 和 LinkedList
| List | 基于 | 快 | 慢 | 内存 |
|---|---|---|---|---|
| ArrayList | 使用数组来实现 | 遍历和查找元素比较快 | 遍历和查找元素比较慢 | 浪费内存空间(扩容、删除时) |
| LinkedList | 使用链表来实现 | LinkedList 添加、删除元素比较快 | 添加、删除元素比较慢 | 专门弥补ArrayList的缺陷!! |
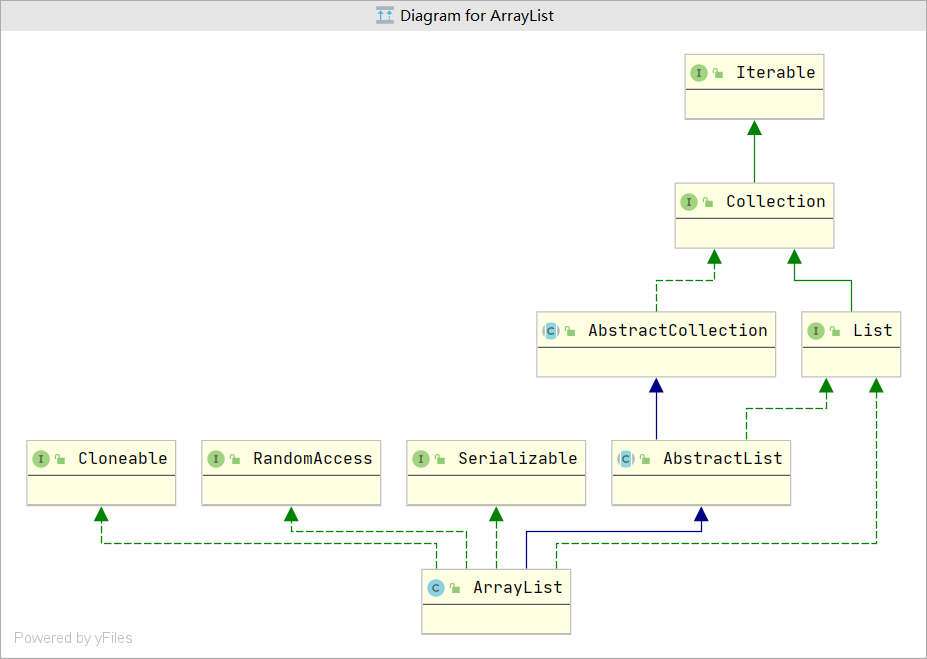
//ArrayList 动态数组集合
public class MyArrayList {
//数组保存数据
private Object[] elementData;
//定义数组长度
private int size;
//初始容量为10
public MyArrayList() {
elementData = new Object[10];
}
public void add(Object obj) {
if (size >= elementData.length) {
Object[] temp = new Object[elementData.length * 2];
System.arraycopy(elementData, 0, temp, 0, size);
elementData = temp;
}
elementData[size++] = obj;
System.out.println("============================================");
System.out.println("size:"+size);
System.out.println("elementData.length:"+elementData.length);
}
public static void main(String[] args) {
MyArrayList myArrayList = new MyArrayList();
for (int i = 0; i < 11; i++) {
myArrayList.add(i);
}
}
}
LinkedList(单链表,双链表,循环链表)
- new LinkedList<>();//此对象保存了size和第一个Node的地址
- 每次add对应着新开辟了一个Node节点,每个Node节点还保存着下一个节点的引用信息
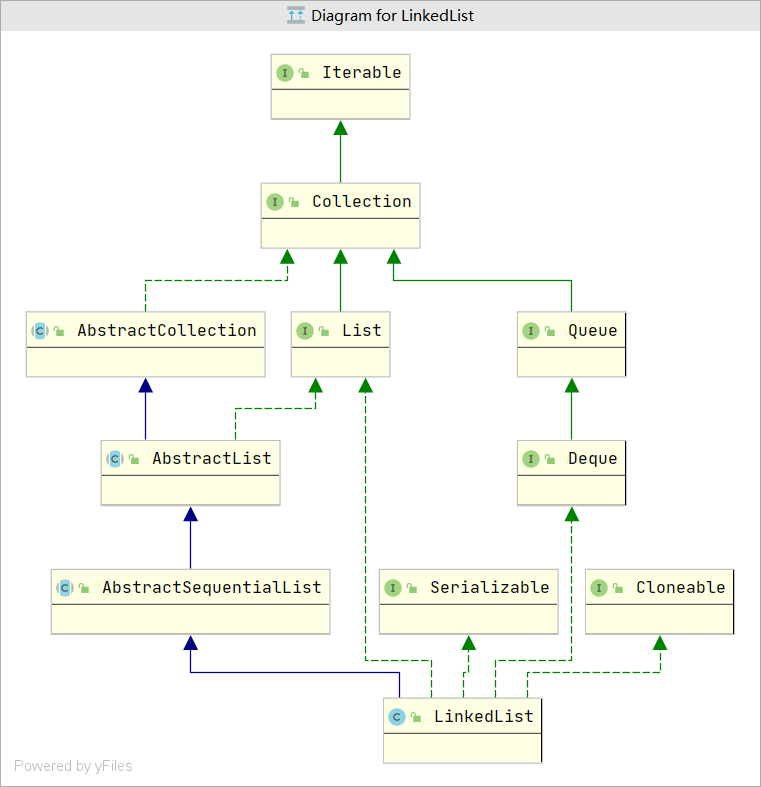
//LinkedList 链表结构
public class MyLinkedList<E> {
private Node First;//头指针
private Node Last;//尾指针
private int size;
class Node {
//最核心的变量,用以保存当前节点的数据
Object element;
//保存前一个节点
Node Previous;
//保存后一个节点
Node Next;
public Node(Object element, Node Previous, Node Next) {
this.element = element;
this.Previous = Previous;
this.Next = Next;
}
public Node(Object element) {
this.element = element;
}
public Node() {
}
}
//添加节点
public void add(E element) {
Node node = new Node(element);//创建一个新的链表节点
if (First == null) {//如果是第一个节点
First = node;//头指针指向这个节点
Last = node;//尾指针指向这个新添加的节点
} else {//如果不是第一个节点
node.Previous = Last;//新添加的节点的头指向上一个节点
// node.Next = null;
Last.Next = node;//此处有疑问!!!
Last = node;//尾指针指向这个新添加的节点
First.Previous = Last;//头尾相连
}
size++;
}
//校验传入的索引是否合法
private void checkIndex(int index) {
if (index < 0 || index > size - 1) {
throw new RuntimeException("索引不合法" + index);
}
}
//获取指定索引的节点
private Node getNode(int index) {
checkIndex(index);
Node temp = null;
if (index <= (size >> 1)) {
temp = First;
for (int i = 0; i < index; i++) {
temp = temp.Next;
}
} else {
temp = Last;
for (int i = size - 1; i > index; i++) {
temp = temp.Previous;
}
}
return temp;
}
public E getValue(int index) {
Node temp = getNode(index);
return (E) temp.element;
}
//移除特定索引节点
public void remove(int index) {
checkIndex(index);
Node temp = null;
if (index != (size - 1) && (index != 0)) {//不是最后一个节点和第一个节点
temp = getNode(index);//获取指定位置的节点
Node nodeNext = temp.Next;
Node nodePrevious = temp.Previous;//借助两个中间节点指针
nodePrevious.Next = nodeNext;
nodeNext.Previous = nodePrevious.Next;
} else if (index == (size - 1)) {//是最后一个节点
temp = Last.Previous;
temp.Next = null;
First.Previous = temp;
} else {
temp = First.Next;
temp.Previous = Last;
First = temp;
}
size--;
}
//在指定位置插入节点
public void insert(int index, E element) {
checkIndex(index);
Node nodeInsert = new Node(element);
if ((index != 0)) {//不是最后一个节点和第一个节点
Node nodeRight = getNode(index);
Node nodeLeft = nodeRight.Previous;
nodeLeft.Next = nodeInsert;
nodeInsert.Previous = nodeLeft;
nodeRight.Previous = nodeInsert;
nodeInsert.Next = nodeRight;//连接新节点
} else {//是第一个节点
nodeInsert.Next = First;
First.Previous = nodeInsert;
nodeInsert.Previous = Last;
First = nodeInsert;
}
size++;
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder("[");
Node temp = First;
while (temp != null) {
stringBuilder.append(temp.element + ",");
temp = temp.Next;
}
stringBuilder.setCharAt(stringBuilder.length() - 1, ']');
return stringBuilder.toString();
}
public static void main(String[] args) {
MyLinkedList<String> testLinkedList01 = new MyLinkedList<>();
for (int i = 0; i < 5; i++) {
testLinkedList01.add("a" + i);
}
System.out.println(testLinkedList01.getValue(2));
System.out.println(testLinkedList01);//此处有疑问
testLinkedList01.remove(0);
System.out.println(testLinkedList01);
testLinkedList01.insert(0, "fada");
System.out.println(testLinkedList01);
testLinkedList01.insert(4, "fada");
System.out.println(testLinkedList01);
}
}
HashMap
存数据的过程:
- 遍历数组,若存在值,则比较key的hash值;
- 若相同(hash碰撞)则进一步equals比较内容,相同则进行覆盖,无相同则添加到数组末端;(若存在hash碰撞情况(重地、通话)则采用链表解决)
- 链表长度大于阈值8并且数组长度大于64则将链表变为红黑树
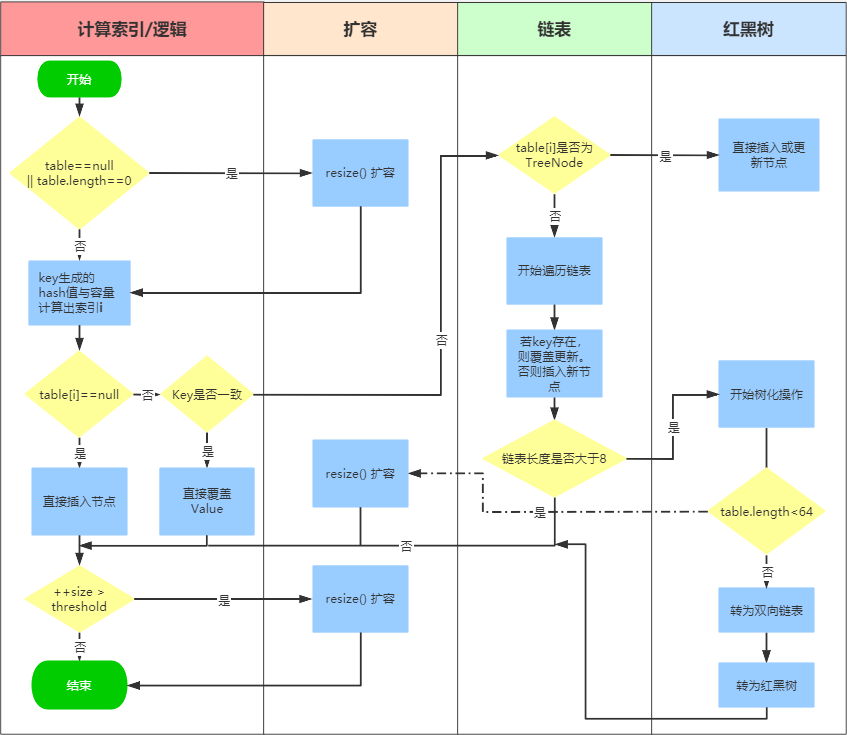
HashMap继承关系
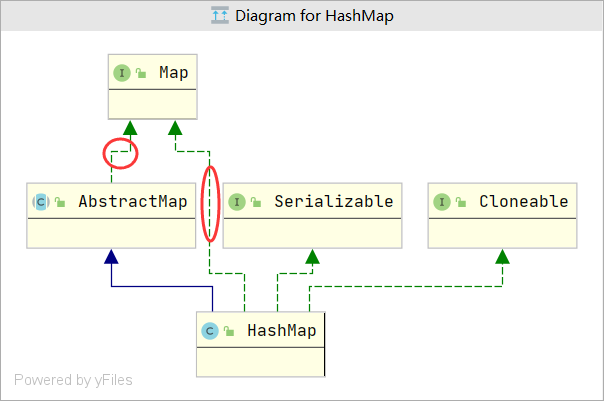
(图中子类和父类继承同一个接口是一个历史原因,是一个失误,jdk维护人员认为不值当为其修改)
成员变量
//初始容量必须是2的次方:减少索引相同的情况,使数组均匀分布;如果构造函数传入10则设为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//负载因子(加载因子)默认是0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//链表长度为8时转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
//红黑树节点为6时转换为链表
static final int UNTREEIFY_THRESHOLD = 6;
//数组长度大于64(转红黑树的另一个条件)
static final int MIN_TREEIFY_CAPACITY = 64;
//存放键值对的
transient Node<K,V>[] table;
//存放缓存
transient Set<Map.Entry<K,V>> entrySet;
//存放元素的个数(注意不等于数组长度)
transient int size;
//每次扩容和更改结构的计数器
transient int modCount;
//边界值默认16,超过这个值就扩容
int threshold;
//哈希表的加载因子!!默认0.75。反映数组存储的满的程度。16*0.75=12
final float loadFactor;
put方法源码(各种计算索引避免hash碰撞存储扩容)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//转换为红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
扩容方法源码
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
如果预先知道了要使用的容量的大小,最好在构造的时候指定(阿里开发手册)

击石乃有火,不击元无烟!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号