
集合学习总结(1)
集合学习总结(1)
1.1 集合使用中的选取规则
在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现类特性进行选择,分析如下:
- 先判断存储的类型(- -组对象[单列]或一 组键值对[双列])
- 一组对象[单列]: Collection接口
- 允许重复: List
增删多: LinkedList [底层维护了一个双向链表]
改查多: ArrayList [底层维护Object类型的可变数组] - 不允许重复: Set
无序: HashSet [底层是HashMap ,维护了一个哈希表即(数组+ 链表+红黑树)]
排序: TreeSet
插入和取出顺序一致: LinkedHashSet , 维护数组+双向链表
- 一-组键值对[双列]: Map
- 键无序: HashMap [底层是:哈希表jdk7: 数组+链表,jdk8: 数组+链表+红黑树]
- 键排序: TreeMap
- 键插入和取出顺序一致: LinkedHashMap
- 读取文件Properties
1.2 各个集合类型的学习总结
1.2.1 集合的框架体系图
Collection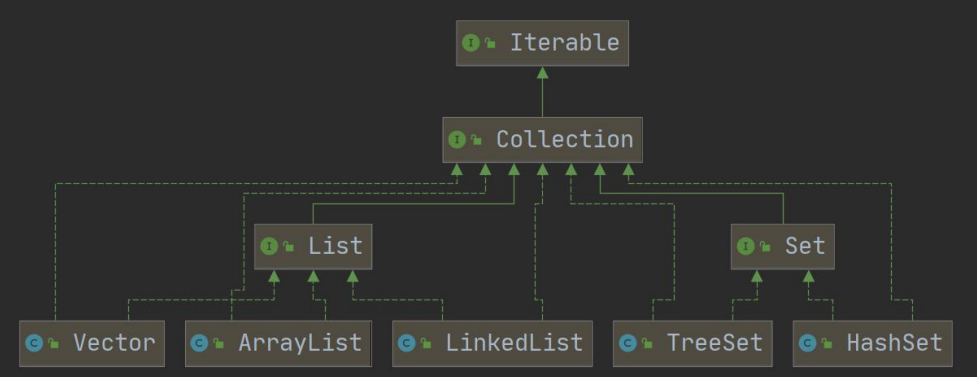
Map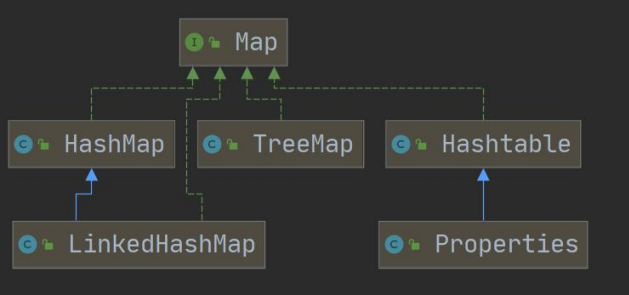
1.2.2 Collection
- Collection接口实现类的特点
- collection实现于类可以存放多个元素,每个元素可以是Object
- 有些Collection的实现类,可以存放重复的元素,有些不可以
- 有些Collection的实现类,有些是有序的(List),有些不是有序(Set)
- Collection接口没有直接的实现子类,是通过它的子接口Set和List来实现的
- Collection接口对象的遍历方式
- Iterator(迭代器)
迭代器的执行原理
- 增强for循环
增强for循环可以替代iterator迭代器,特点:增强for就是简化版的迭代器,只能用于遍历集合和数组
- 基本语法
for(元素类型 元素名:集合或者数组名){
访问元素
}
1.2.3 List接口和常用方法
List接口是Collection接口的子接口
- List集合类中元素有序(即添加顺序和取出顺序一致)、 且可重复
- List集合中的每个元素都有其对应的顺序索引,即支持索引
- List容器中的元素都对应一 个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素
- 实现List接口的类有很多,其中常用的有ArrayList,LinkedList和Vector
List常用方法总结
- list.add 添加元素
- void add(int index, Object ele) 在index位置插入ele元素
- Object get(int index) 获取指定index位置的元素
- Object remove(int index) 删除指定位置元素,并返回此元素
- Object set(int index,Object ele) 设定指定index位置元素为ele
- LIst subList(int fromIndex,int toIndex) 返回从fromIndex到toIndex的子集合
1.2.4 ArrayList
- ArrayList注意事项
- ArrayList可以加入null,并且多个
- ArrayList是由数组来实现数据存储的
- ArrayList基本等同于Vector ,除了ArrayList是线程不安全(执行效率高),在多线程情况下,不建议使用ArrayList
- ArrayList底层分析
- ArrayList中维护了一个Object类型的数组elementData.
transient Object[] elementData; //transient表示瞬间,短暂的,表示该属性不会被序列号 - 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍
- 如果使用的是指定大小的构造器,则初始elementData容量为指定大小, 如果需要扩容,则直接扩容elementData为1.5倍
1.2.5 Vector
- Vector底层也是一 个对象数组,protected Object[] elementData;
- Vector是线程同步的,即线程安全,Vector类的操作方法带有synchronized
public synchronized E get(int index) {
if (index > = elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
- 在开发中,需要线程同步安全时,考虑使用Vector
ArrayList与Vector比较
| 底层结构 | 线程安全(同步)效率 | 扩容倍数 | |
|---|---|---|---|
| ArrayList | 可变数组 | 不安全,效率高 | 如果是有参构造1.5倍 如果是无参 第一次10,之后按照1.5倍扩容 |
| Vector | 可变数组 | 安全,效率不高 | 如果是无参,按照默认10,满后按照2倍数扩容 如果指定大小,则每次都按照两倍扩容 |
1.2.6 LinkedList
LinkedList介绍
- LinkedList底层实现了双向链表和双端队列特点
- 可以添加任意元素(元素可以重复),包括null
- 线程不安全,没有实现同步
LinkedList底层操作机制
- LinkedList底层维护了一个双向链表.
- LinkedList中维护了两个属性first和last分别指向首节点和尾节点
- 每个节点(Node对象) ,里面又维护了prev、 next、 item三个属性,其中通过prev指向前一一个,通过next指向后一个节点,最终实现双向链表
- 所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率较高
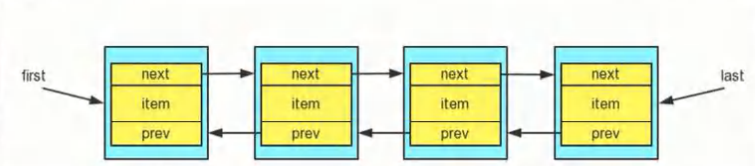
遍历方式
//因为 LinkedList 是 实现了 List 接口, 遍历方式
System.out.println("===LinkeList 遍历迭代器====");
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("next=" + next);
}
System.out.println("===LinkeList 遍历增强 for====");
for (Object o1 : linkedList) {
System.out.println("o1=" + o1);
}
System.out.println("===LinkeList 遍历普通 for====");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
- ArrayList和LinkedList比较
| 底层结构 | 增删效率 | 改查效率 | |
|---|---|---|---|
| ArrayList | 可变数组 | 较低,数组扩容原因 | 较高 |
| LinkedList | 双向链表 | 较高,通过链表追加 | 较低 |
1.2.7 Set接口和常用方法
**Set介绍 **
- 无序(添加和取出顺序不一致),没有索引
- 不允许重复元素,所以至多一个Null
- 常用的接口实现类有HashSet,TreeSet
因为Set和List都是Collection的子接口,所以常用的方法和Collection一样
- Set接口的遍历方式
和Collection遍历方式一样,可以使用迭代器和增强for循环,不过Set不能使用索引来获取
1.2.8 HashSet
- HashSet实现了Set接口
- HashSet实际上是HashMap
![]()
- 可以存放Null值,但是只能有一个
- HashSet不保证元素是有序的,取决于hash后,再确定索引的结果,即不保证存入顺序和取出顺序一致
- 不能有重复的元素/对象

HashSet底层机制说明
- 分析HashSet底层是HashMap, HashMap底层是(数组+链表+红黑树)
- HashSet 底层是HashMap
- 添加一个元素时,先得到hash值-会转成->索引值
- 找到存储数据表table ,看这个索引位置是否已经存放的有元素
- 如果没有,直接加入
- 如果有,调用equals比较,如果相同,就放弃添加,如果不相同,则添加到最后
- 在Java8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),并且table的大小>=MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树)
具体的底层源码分析在后面单独总结
- 分析HashSet的扩容和转成红黑树机制
- HashSet底层是HashMap,第一-次添加时,table 数组扩容到16,临界值(threshold)是1 6* 加载因子(loadFactor)是0.75 = 12
- 如果table数组使用到了临界值12,就会扩容到16* 2 = 32,新的临界值就是32* 0.75 = 24,依次类推
- 在Java8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8 ),并且table的大小>=MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号