基本数据类型
- 非常的重要
序列和索引
1、基础
- 就是根据这个索引可以取出一个元素
a1= "abcd"
# 正向的索引为 0 1 2 3
# 反向的索引为 -4 -3 -2 -1
2、切片操作
-
[start: end:步长]
-
默认不包含结束的索引
-
当步长为负数的时候,就是从右到左了
-
为正数的时候就是从左到右了
ll = "abcde"
print(ll[::1])
print(ll[1:4:])
print(ll[0:4])
print(ll[::-1]) # 逆序输出即可,因为步长是负数
print(ll[-1:-9:-1])
3、其他操作
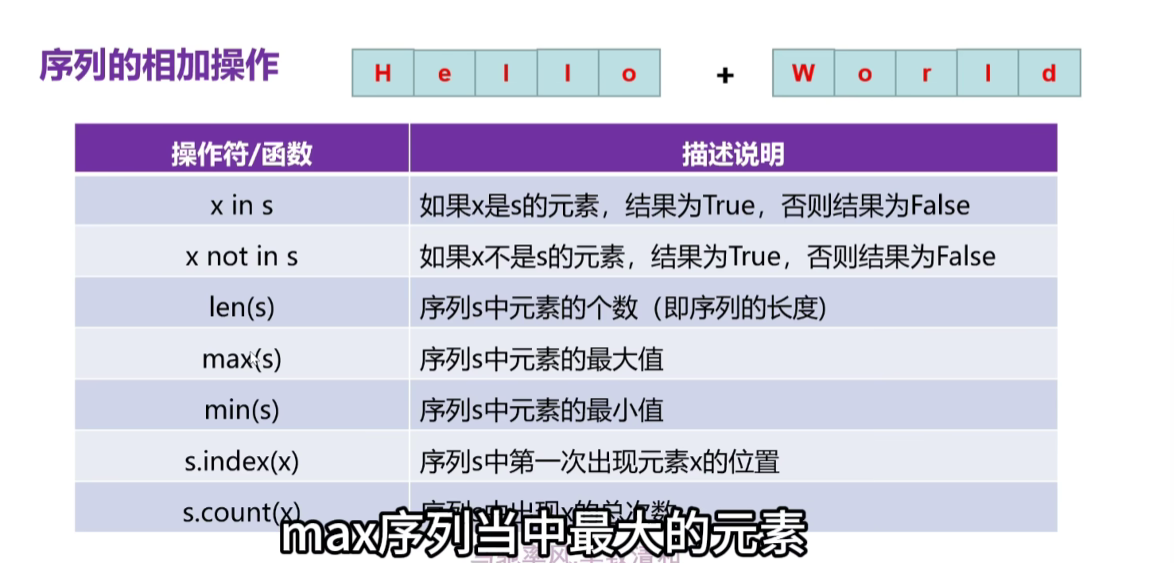
-
len(类型),求出这个长度
-
max(类型),求出最大值
-
min(类型),求出最小值
-
s.index(元素),求出这个元素第一次出现的索引的位置,不存在的话,就会报错,返回一个索引
print("*"*30)
一、列表
1、列表的定义和特性
-
可变序列,就是修改这个列表的话,这内容会改变,但是这个内存的地址还是一样的,内存的地址不会被改变
-
index,count都可以适用
# 直接定义
lista=["a","asd",12]
# 内置函数list创建
listb=list(序列)
la=["123",123,"abv"]
print(la)
print(la.count("abv"))
print(la.index(123))
# 输出结果为
['123', 123, 'abv']
1
1
2、列表的操作
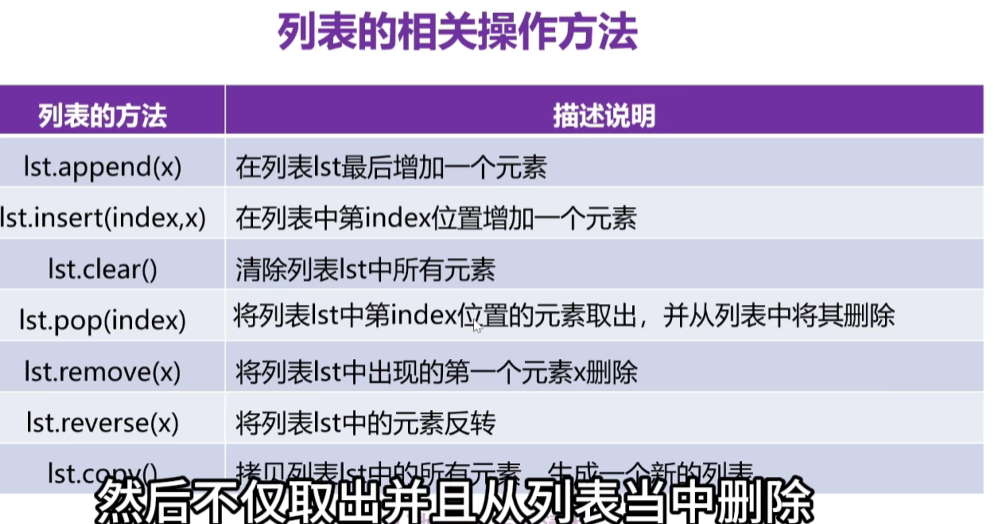
1、del删除操作
list1=[12,123,777]
# 这样就删除了这个列表,因此的话,输出这个列表就会报错
del list1
print(list1)
2、遍历列表
- for循环遍历
lista = ["abc","def","qwe","123",555]
for i in lista:
print(i)
- 使用range来遍历循环
lista = ["abc","def","qwe","123",555]
for i in range(0,len(lista)): # 列表长度
print(lista[i])
3、列表的增加(append)和extend
- 在列表的最后一个元素后插入地址
lista = ["abc","def","qwe","123",555]
lista.append(["asd",123]) # 将一个整体添加到列表中去
lista.append("mmm")
print(lista)
# 输出结果为
['abc', 'def', 'qwe', '123', 555, ['asd', 123], 'mmm']
- extend,将添加的数据类型分解后再添加
lista = ["abc","def","qwe","123",555]
lista.extend("kjh")
print(lista)
# 输出结果为
['abc', 'def', 'qwe', '123', 555, 'k', 'j', 'h']
lista.extend(["aaa","bbb"]) # 将这个列表分解为字符串,依次添加
print(lista)
# 输出结果为
['abc', 'def', 'qwe', '123', 555, 'aaa', 'bbb']
lista.extend({"k":"123"}) # 添加字典的话,添加的就是k
print(lista)
# 输出结果为
['abc', 'def', 'qwe', '123', 555, 'k']
4、列表的插入(insert)
-
insert(索引,插入的内容)
-
在索引的前面插入内容
lista.insert(1,"123")
print(lista)
# 输出结果为
['abc', '123', 'def', 'qwe', '123', 555]
5、列表的删除
1、remove
- remove(元素)
lista.remove("abc")
print(lista)
# 输出结果为
['def', 'qwe', '123', 555]
2、pop
- pop(索引),有一个返回值为要删除的元素
count=lista.pop(1)
print(count)
print(lista)
# 输出结果为
def
['abc', 'qwe', '123', 555]
6、clear
-
清空所有的元素
-
list1.clear()
lista.clear()
print(lista)
# 输出结果为
[]
7、列表反向输出
- reverse()
lista.reverse()
print(lista)
# 输出结果为
[555, '123', 'qwe', 'def', 'abc']
8、列表的复制
- copy
listb=lista.copy() # 会创建一个新的列表出来
print(listb)
# 输出结果为
['abc', 'def', 'qwe', '123', 555]
3、列表的修改
- 通过这个索引来进行修改的
lista[1]="kkk"
print(lista)
# 输出结果为
['abc', 'kkk', 'qwe', '123', 555]
4、列表的排序
sort
-
默认是升序的操作
-
sort(reverse=true) 这个为降序
listb=["asd","nnn","KKK","QWQW"]
listb.sort()
print(listb)
# 输出结果为
['KKK', 'QWQW', 'asd', 'nnn']
listb.sort(reverse=True) # 设置为降序
print(listb)
# 输出结果为
['nnn', 'asd', 'QWQW', 'KKK']
- sort(key=str.lower) 全部转换为小写来进行排序
listb.sort(key=str.lower) # 默认全部转换为小写,从而进行排序
print(listb)
# 输出结果为
['asd', 'KKK', 'nnn', 'QWQW']
sorted
-
内置函数排序
-
返回一个新的列表
-
sorted(列表,reverse=)
-
默认也是升序排序
listc=sorted(listb,reverse=True)
print(listc)
# 输出结果为
['nnn', 'asd', 'QWQW', 'KKK']
5、二维列表
-
上面都是一维列表
-
还有一个二维列表,就是一个表格数据,一个列表中嵌套了多个列表
# 这个就是一个二维列表
listc=[["asd",123],["mm",43],["ll",55]]
for i in listc: # i 就是列表
for j in i: # 对里面的列表再次进行遍历
print(j,end=" ")
print()
# 输出结果为
asd 123
mm 43
ll 55
二、元组

1、元组的定义和创建
-
不可变类型的数据,就不支持删除,增加,修改等操作
-
可以存储多个类型的数据,里面是有序的数据,因此的话可以使用索引
-
del可以删除这个元组
t=("hello",[10,20,30],123)
# 输出结果为
# 如果只有一个元素的话
t=(10,) # 必须要带上这个逗号才行,否则不是元组
t1=(10,)
print(type(t1)) # 类型为元组
t2=(10)
print(type(t2)) # 类型为int
-
判断元素是否存在,in, not in
-
index,count都能使用
t3=(123,"aaa","bbb")
if "123" not in t3:
print("不存在")
2、元组的访问
1、元组也支持切片操作
t3=(123,"aaa","bbb")
print(t3[0:2])
2、遍历元组
- for循环遍历
t1 = ("abc","bbb","kkk","ppp")
for i in t1:
print(i)
# 输出结果为
abc
bbb
kkk
ppp
- 根据这个索引来进行遍历,range
for i in range(0,len(t1)):
print(t1[i])
三、字典
1、字典的定义和创建
-
可变的数据类型,支持增删改查操作,里面是无序的的对象集合
-
key和value对应,这个key是唯一的,值可以有重复的
-
key必须是不可变序列才行,可变的序列不能充当这个key
-
元组可以充当这个键,列表不能充当这个键
# 创建字典
d={"姓名":"qqq","年龄":123}
d=dict(key1=v1,key2=v2)
2、获取字典
-
d[key],来获取这个值
-
d.get(key,默认值) 如果不存在的话,就会输出这个默认值
# get使用
d1={"姓名":11,"年龄":155,"mm":999}
print(d1.get("mm"))
print(d1["姓名"]) # 可以直接获取到这个key对应的value值
3、遍历字典
-
for遍历
-
d.items方法,这个就是会遍历成一个元组的形式
-
for key,value in d.items
-
keys(),values() 遍历后,虽然不能使用索引(字典本来就不能使用索引),因此的话,可以使用for再次遍历,以后或者有什么满足条件的话
# 直接进行遍历的话,遍历的都是key值
for i in d1:
print(i)
# 输出结果为
姓名
年龄
mm
# d.keys() # 获取到是字典的中每一个键
for i in d1.keys():
print(i)
# 输出结果为
姓名
年龄
mm
# d.values() 获取到时每一个值
for i in d1.values():
print(i)
# 输出结果为
11
155
999
# d.items()
for i in d1.items():
print(i,type(i))
# 输出结果为
('姓名', 11) <class 'tuple'>
('年龄', 155) <class 'tuple'>
('mm', 999) <class 'tuple'>
# key和value值都取出来
for key, value in d1.items(): # 使用2个变量来代替即可
print(key, value)
# 输出结果为
姓名 11
年龄 155
mm 999
4、字典的操作
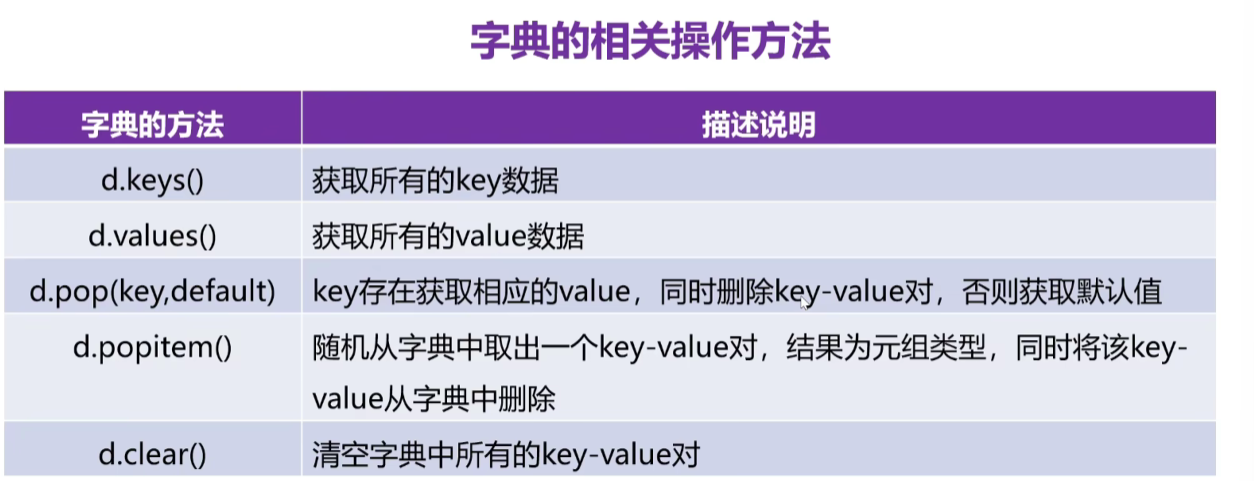
1、添加元素
-
d[新key]=值
-
如果这个key存在的话,则是修改,否则就是添加
d1["lll"]="ppp"
print(d1)
# 输出结果为
{'姓名': 11, '年龄': 155, 'mm': 999, 'lll': 'ppp'}
-
d.upadte(key=值)
-
d.update({key:值})
d1.update(mm="1231")
print(d1)
2、删除元素
- d.pop(key), 有一个返回值,会直接进行删除这个元素
d1.pop("mm") # 返回对应的值
print(d1)
# 输出结果为
{'姓名': 11, '年龄': 155}
3、随机删除元素
- d.popitem() 会随机删除这个元素
nn=d1.popitem() # 删除的值,为以元组的方式返回
print(d1)
print(nn)
# 输出结果为
{'姓名': 11, '年龄': 155}
('mm', 999)
4、del删除
- del d[key]
del d1["mm"]
print(d1)
5、清空字典
- d.clear()
d1.clear()
print(d1)
# 输出结果为
{}
四、集合(set)

1、集合的定义和创建
-
可变的数据类型
-
只能存储不可变的数据类,字符串,整数,浮点数,元组
-
里面的元素都是不重复的元素
-
无序的数据,每次运行的时候,顺序都是不一样的
-
因为无序的,所以的话不能使用索引
s={} # 创建的是字典
# 创建空集合
s=set() # 这个才能创建空集合
s1={12,0,"a"} # 里面存储的不可变数据类型
2、集合的内置
1、交集(&)
- 取出2个集合中公有的元素
set1 = {1, 2, 3}
set2 = {3, 4, 5}
jiao=set1 & set2
print(jiao)
# 输出结果为
{3}
2、并集(|)
- 将2个集合合并到一起,去掉了重复的元素
bing = set1 | set2
print(bing)
# 输出结果为
{1, 2, 3, 4, 5} # 会自动的去掉重复的元素
3、差集()
- 看谁在前面,就是谁的差集
cha = set1 - set2 # 求的是set2没有的元素
print(cha)
# 输出结果为
{1, 2}
3、集合的操作

1、add操作
s1={10,20,"asd"}
s1.add("kkk")
print(s1)
# 输出结果为
{'kkk', 10, 20, 'asd'}
2、删除元素remove()
s1.remove(10)
print(s1)
3、清空集合clear
s1.clear()
4、集合的遍历
- for循环遍历
for i in s1:
print(i)
- range遍历,不能使用这个遍历,因为这个不能使用索引,里面的数据是无序的,去重的
五、字符串
-
不可变的数据类型
-
里面的数据是有序的,可以使用索引
1、字符串的方法
1、字符串大小写
-
s1.lower() 全部转换为小写
-
s1.upper() 全部转换为大写
s1="helloworld"
print(s1.upper())
2、字符串的分割
-
按照字符进行分割,最后会得到一个列表
-
s1.split("@")
s2="123@qq.com"
# 会得到一个新的列表,原字符串的内容是没有变化的
print(s2.split("@"))
# 输出内容
['123', 'qq.com']
3、count和find和index
- s.find("字符"),找到了就输出索引,没有找到的话,输出-1
s2="123@qq.com"
print(s2.count("1"))
print(s2.find("1"))
# 输出结果为
1
0
4、endswith和startswitch
-
endswitch以什么结尾的吗
-
startswitch 以什么开头的吗
s1="qqqwwww"
print(s1.endswith("www"))
print(s1.startswith("q"))
# 输出结果为
True
True
5、replace替换
s1="HelloWorld"
new_s = s1.replace("o","你好",1) # 后面 1 代表着替换1次即可,默认是全部替换
print(new_s)
6、center
- 字符串居中,不足的左右补空格
s1="HelloWorld"
print(s1.center(20)) # 居中20,这个字符串的长度为10,所以话左右补齐5个即可
print(s1.center(20,"*")) # 补齐的用*来实现
# 输出结果为
HelloWorld
*****HelloWorld*****
7、strip和lstrip和rstrip
-
strip去掉2边的空格或者指定的字符
-
lstrip去掉左边的空格或者指定的字符
-
rstrip去掉右边的空格或者指定的字符
s1=" HelloWorld "
print(s1.strip())
print(s1.lstrip())
print(s1.rstrip())
# 输出结果为
HelloWorld # 去掉2边的空格
HelloWorld # 右边的空格还有
HelloWorld # 左边的空格还有
s2="lpkkkkllp"
print(s2.strip("lp")) # 去掉左右2边含有l或者p字符的 ,不是去掉lp这个字符的,是含有l或者p字符的
print(s2.lstrip("lp")) # 去掉左边含有l或者p字符的
print(s2.rstrip("lp")) # 去掉右边含有l或者p字符的
# 输出结果为
kkkk
kkkkllp
lpkkkk
2、字符的格式化输出
- 之前字符串连接其他数据类型,比如整型的话,就会报错,现在有了这个格式化输出的话,就不会报错了
1、占位符
-
%d占的是一个十进制的整数
-
%f 浮点数的格式
name="qq"
age=18
score=19.88
print("姓名:%s,年龄:%d,成绩:%.1f" %(name,age,score))
2、f-string
print(f"姓名:{name},年龄:{age},成绩:{score}")
3、str.format方法
# 这个{0} 里面的数字对应着后面的format里面的参数位置
print("姓名:{0},年龄:{1},成绩:{2}".format(name,age,score))
3、数据的验证
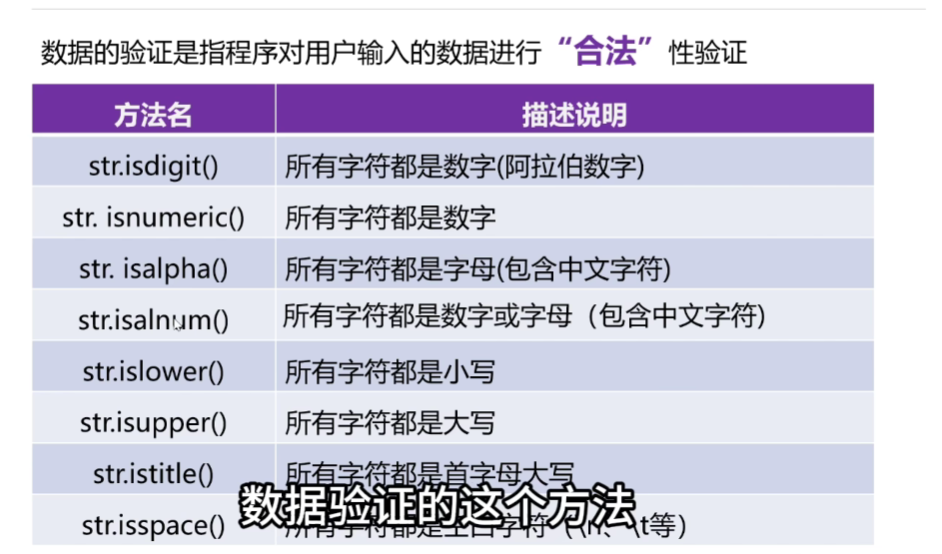
- 有一个返回值True或者False
1、isdigit()和isnumeric()
- 字符只能是数字,阿拉伯的数字,汉字的一二三或者其他的都不认识
print("123".isdigit())
print("一二三".isdigit())
print("一二三".isnumeric())
# 输出结果
True
False
True
2、isalnum和isalpha
-
isalnum 字符有数字或者字符,中文字符也可以
-
isalpha 所有字符都是字母
print("asd".isalpha())
print("asd12".isalpha())
print("asd12".isalnum())
# 输出结果为
True
False
True
3、istitle
- 单词的首字母是大写,其他字母为小写
print("Hello World".istitle()) # True(每个单词首字母大写,其余小写)
print("hello World".istitle()) # False(第一个单词首字母小写)
print("Hello world".istitle()) # False(第二个单词首字母小写)
print("HelloWorld".istitle()) # False(单词之间没有分隔,被视为一个单词但中间有大写字母)
print("Hello 2World".istitle()) # True(数字不影响,第二个单词首字母大写)
print("".istitle()) # False(空字符串)
4、拼接
-
+ 拼接
-
join将列表或者序列的内容进行拼接,元素必须是字符串类型
-
"拼接的字符".join(列表或者元组,
可迭代的对象)
s1="abc"
s2="ddd"
print(s1+s2)
# 输出结果为
abcddd
s3="".join([s1,s2]) # 将多个列表进行拼接
print(s3)
5、字符串的去重
- 一个字符串,另一个空的字符串
s1= "hhhoooddd"
s2=""
for i in s1:
if i not in s2:
s2+=i
print(s2)
总结
1. 列表(List)操作
-
可变的数据类型,里面可以存储多个类型的数据
-
有序的元素
| 操作类型 | 具体操作 | 示例 | 说明 |
|---|---|---|---|
| 创建 | 直接定义 | lst = [1, 2, 3] |
用方括号包裹元素 |
| 转换其他类型 | lst = list((1, 2, 3)) |
将元组转换为列表 | |
| 访问 | 索引访问 | lst[0] |
获取索引 0 的元素(从 0 开始) |
| 切片 | lst[1:3] |
获取索引 1 到 2 的元素(左闭右开) | |
| 反向索引 | lst[-1] |
获取最后一个元素 | |
| 修改 | 索引赋值 | lst[0] = 10 |
修改指定索引的元素 |
| 添加 | append(x) |
lst.append(4) |
在末尾添加元素 |
insert(i, x) |
lst.insert(1, 5) |
在索引 i 处插入元素 x | |
extend(iterable) |
lst.extend([6, 7]) |
合并另一个可迭代对象的元素 | |
| 删除 | remove(x) |
lst.remove(2) |
删除第一个值为 x 的元素 |
pop(i) |
lst.pop(1) |
删除索引 i 的元素并返回该元素(默认最后一个) | |
clear() |
lst.clear() |
清空列表 | |
| 其他 | len(lst) |
len(lst) |
获取列表长度 |
x in lst |
2 in lst |
判断元素是否在列表中 | |
sort() |
lst.sort() |
原地排序(默认升序) | |
reverse() |
lst.reverse() |
原地反转列表 |
2. 元组(Tuple)操作
-
不可变数据类型,但是里面可以存储多种数据类型,列表等等
-
里面的数据是有序的,可以使用索引
| 操作类型 | 具体操作 | 示例 | 说明 |
|---|---|---|---|
| 创建 | 直接定义 | tup = (1, 2, 3) |
用圆括号包裹元素(单元素需加逗号:(1,)) |
| 转换其他类型 | tup = tuple([1, 2, 3]) |
将列表转换为元组 | |
| 访问 | 索引访问 | tup[0] |
获取索引 0 的元素 |
| 切片 | tup[1:3] |
获取索引 1 到 2 的元素(左闭右开) | |
| 反向索引 | tup[-1] |
获取最后一个元素 | |
| 查询 | count(x) |
tup.count(2) |
统计元素 x 出现的次数 |
index(x) |
tup.index(2) |
返回元素 x 第一次出现的索引 | |
| 其他 | len(tup) |
len(tup) |
获取元组长度 |
x in tup |
2 in tup |
判断元素是否在元组中 |
3. 集合(Set)操作
-
可变数据类型,但是里面存储的是不可变的数据类型(不能是列表,字典)
-
并且里面自动去重
-
里面是无序的,每次输出的结果都是不一样的话,因此的话不能使用这个索引
| 操作类型 | 具体操作 | 示例 | 说明 |
|---|---|---|---|
| 创建 | 直接定义 | s = {1, 2, 3} |
用大括号包裹元素(空集合需用 set()) |
| 转换其他类型 | s = set([1, 2, 3]) |
将列表转换为集合(自动去重) | |
| 添加 | add(x) |
s.add(4) |
添加元素 x(已存在则忽略) |
update(iterable) |
s.update([5, 6]) |
合并另一个可迭代对象的元素 | |
| 删除 | remove(x) |
s.remove(2) |
删除元素 x(不存在则报错) |
discard(x) |
s.discard(2) |
删除元素 x(不存在则忽略) | |
pop() |
s.pop() |
随机删除并返回一个元素(空集合报错) | |
clear() |
s.clear() |
清空集合 | |
| 集合运算 | 交集(& 或 intersection()) |
s1 & s2 或 s1.intersection(s2) |
取两个集合的共同元素 |
| 并集(` | 或union()`) |
`s1 | |
差集(- 或 difference()) |
s1 - s2 或 s1.difference(s2) |
取 s1 中有而 s2 中没有的元素 | |
对称差集(^ 或 symmetric_difference()) |
s1 ^ s2 |
取两个集合中互不相同的元素 | |
| 其他 | len(s) |
len(s) |
获取集合大小 |
x in s |
2 in s |
判断元素是否在集合中 |
4. 字典(Dictionary)操作
-
可变的数据类型,但是这个key是不可变的数据类型,只能是字符串或者数据,不能是重复的
-
value的值是可变的,可以重复的
| 操作类型 | 具体操作 | 示例 | 说明 |
|---|---|---|---|
| 创建 | 直接定义 | d = {"name": "Alice", "age": 20} |
用键值对 key: value 定义 |
| 转换其他类型 | d = dict([("name", "Bob"), ("age", 21)]) |
将键值对列表转换为字典 | |
| 访问 | 键访问 | d["name"] |
通过键获取值(键不存在则报错) |
get(key, default) |
d.get("name", "Unknown") |
通过键获取值(键不存在返回 default) | |
| 修改/添加 | 键赋值 | d["age"] = 22 |
键存在则修改值,不存在则添加键值对 |
update(other) |
d.update({"gender": "female"}) |
合并另一个字典的键值对(覆盖重复键) | |
| 删除 | del d[key] |
del d["age"] |
删除指定键的键值对 |
pop(key) |
d.pop("name") |
删除指定键的键值对并返回值 | |
clear() |
d.clear() |
清空字典 | |
| 查询 | keys() |
d.keys() |
返回所有键的视图 |
values() |
d.values() |
返回所有值的视图 | |
items() |
d.items() |
返回所有键值对的视图((key, value)) |
|
| 其他 | len(d) |
len(d) |
获取字典中键值对的数量 |
key in d |
"name" in d |
判断键是否在字典中 |
5. 字符串(String)操作
| 操作类型 | 具体操作 | 示例 | 说明 |
|---|---|---|---|
| 创建 | 直接定义 | s = "hello" 或 s = 'world' |
用单引号、双引号或三引号包裹 |
| 访问 | 索引访问 | s[0] |
获取索引 0 的字符 |
| 切片 | s[1:4] |
获取索引 1 到 3 的子串(左闭右开) | |
| 反向索引 | s[-1] |
获取最后一个字符 | |
| 拼接/重复 | + 拼接 |
"hello" + " world" |
拼接两个字符串 |
* 重复 |
"a" * 3 |
重复字符串(结果:"aaa") |
|
| 常用方法 | split(sep) |
"a,b,c".split(",") |
按分隔符 sep 分割字符串(结果:["a", "b", "c"]) |
join(iterable) |
",".join(["a", "b"]) | 用字符串连接可迭代对象的元素(结果:"a,b") |
|
strip() |
" hello ".strip() |
去除首尾空白字符(结果:"hello") |
|
upper()/lower() |
"Hello".upper() |
转换为全大写/全小写(结果:"HELLO") |
|
replace(old, new) |
"hello".replace("l", "x") |
替换子串(结果:"hexxo") |
|
startswith(prefix) |
"hello".startswith("he") |
判断是否以 prefix 开头(返回 True) |
|
endswith(suffix) |
"hello".endswith("lo") |
判断是否以 suffix 结尾(返回 True) |
|
| 其他 | len(s) |
len("hello") |
获取字符串长度(结果:5) |
x in s |
"e" in "hello" |
判断字符/子串是否在字符串中(返回 True) |
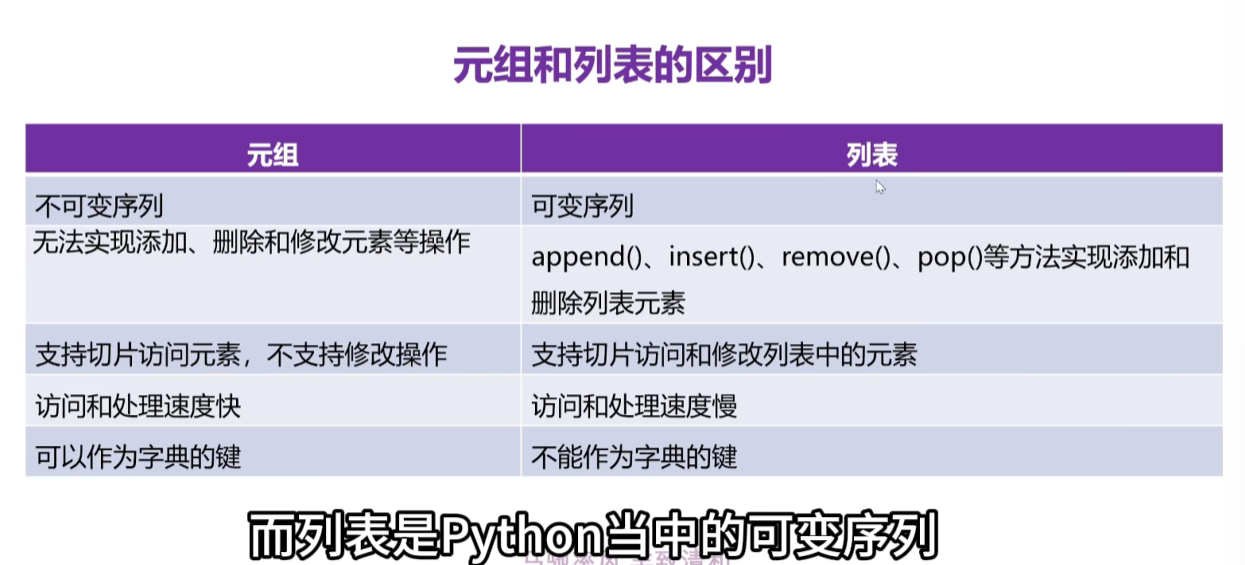
6、元组和列表的区别
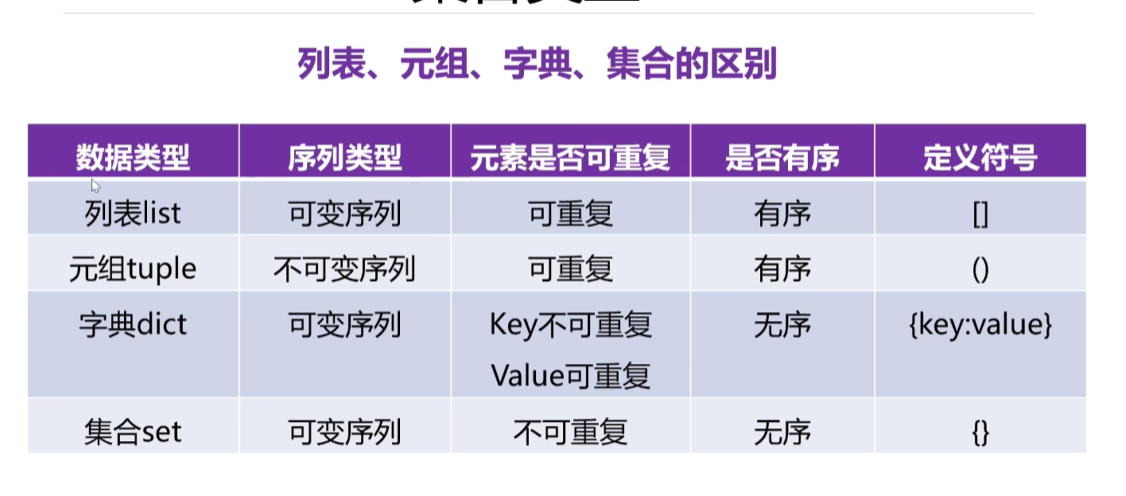
7、列表,元组,字典,集合的区别
| 数据类型 | 表示方式 | 有序性 | 可变性 | 是否允许重复元素 | 主要特点与常用操作 | 典型应用场景 |
|---|---|---|---|---|---|---|
| 列表 | [] 或 list() |
是(有索引) | 是 | 允许 | 支持索引、切片、append()、pop()、sort() 等方法,可动态增删改元素 |
存储动态数据集合,如待办事项列表 |
| 字符串 | ''/""/''' ''' |
是(有索引) | 否 | 允许 | 支持索引、切片、split()、join()、strip() 等方法,不可修改单个字符 |
存储文本信息,如名称、描述 |
| 元组 | () 或 tuple() |
是(有索引) | 否 | 允许 | 支持索引、切片,方法较少(count()、index()),整体不可修改 |
存储不可变数据,如坐标 (x,y) |
| 集合 | {} 或 set() |
否 | 是 | 不允许 | 支持 add()、remove(),以及交集 &、并集 ` |
` 等集合运算,自动去重 |
| 字典 | {k:v} 或 dict() |
是(3.7+) | 是 | 键不允许 | 通过键访问值,支持 get()、keys()、items(),可动态增删改键值对 |
存储键值关联数据,如用户信息 |
2、测试
1、千年虫
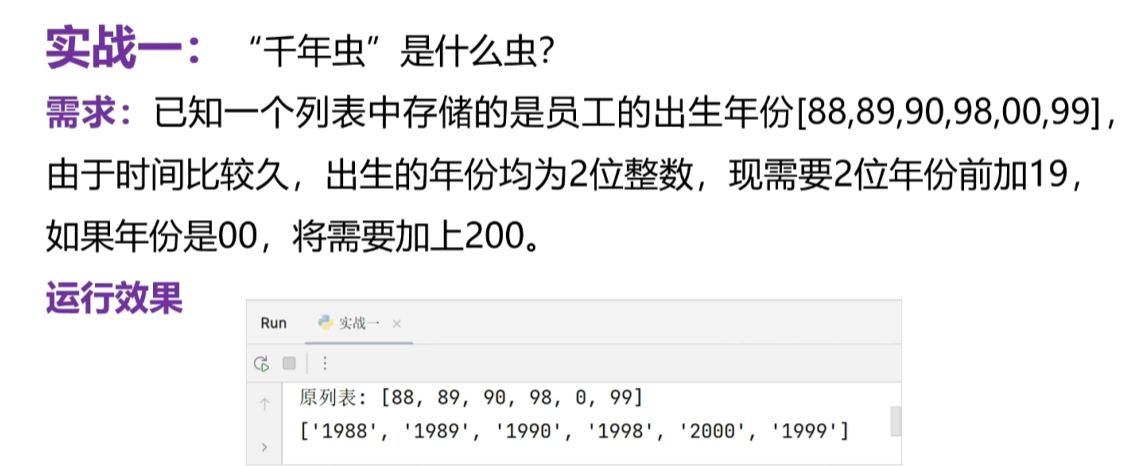
-
需求
-
补齐完整的出生年份
-
0的话前面加上200,除此之外的话,加上19即可
-
user_list = [88,89,90,00,99]
full_list = [] # 新列表
for i in user_list:
if str(i) != "0": # 不等于0的情况下执行
full_year = "19"+str(i)
else:
full_year = "200"+str(i) # 等于0的情况
full_list.append(full_year) # 将这些都添加到新列表中去
print(full_list)
# 输出结果为
['1988', '1989', '1990', '2000', '1999']
2、模拟京东的购物
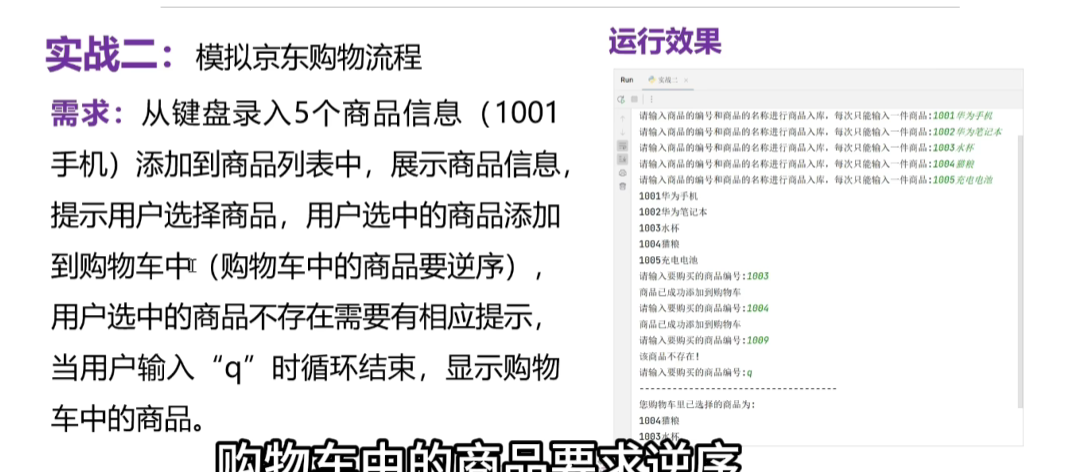
-
首先录入5个商品信息,然后展示5个商品
-
用户选择购买的商品,不存在要有提示
-
用户输入q退出循环
-
显示用户购买的商品,逆序显示
shopp_user = []
user_buy = []
for i in range(0, 5):
name_shop = input("请输入商品名称(1001 mm):")
shopp_user.append(name_shop)
for i in shopp_user:
print(i)
while True:
user_choose = input("请输入购买的商品编号:")
# 输入q的时候退出循环
if user_choose == "q":
break
# 遍历这个所有商品,判断购买的商品是否存在
flag = False # 这个用来做标记,找到商品就退出,没有找到就打印
for i in shopp_user:
if (user_choose in i) and (user_choose != "q"):
user_buy.append(i) # 将买的东西添加到新的列表中去
print("商品已经添加到购物车了")
flag = True
break # 找到了就直接退出这个for循环
if not flag: # 这个不能放在遍历商品里面,但输入的商品与遍历的商品比较后,再来执行是否存在该商品,找到的话,为True,就是不会执行,没有找到的话False执行
print("商品没有找到")
user_buy.sort(reverse=True)
print("购买的商品信息如下")
print("——" * 30)
for i in user_buy:
print(i)
3、模拟12306购物订票
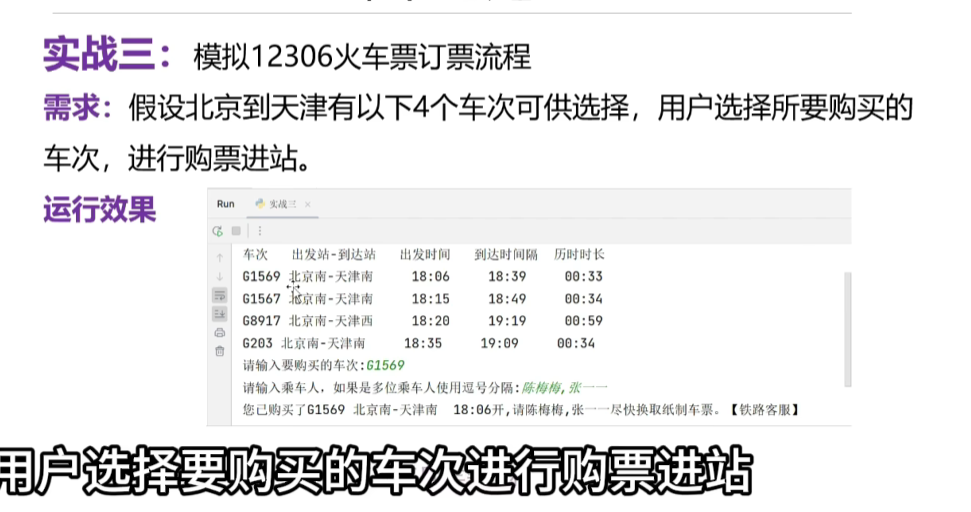
- 用户购票,没有票提示,有票显示时间,到哪的
subwey={
"G3333":["北京南-天津南","16:06","18:39","00:33"],
"G5555":["北京南-天津动","16:06","18:39","00:33"],
"G6666":["北京南-天津系","16:06","18:39","00:33"],
"G7777":["北京南-天津被","16:06","18:39","00:33"]
}
print("车次\t出发站-到达站\t出发时间\t达到时间\t历经时长")
for k,v in subwey.items():
print(k,end=" ")
for i in v: # i 里面存储的是列表
print(i,end=" ")
print()
use_choose=input("请输入购买的车次:")
flag=False # 用来标记是否存在这个车次
for i in subwey.keys(): # 这个i是一个键
if use_choose in i:
name=input("请输入乘车人,如果有多为乘车人的话,用逗号隔开:")
print("你已经购买了", use_choose,"乘车人信息",name,"尽快换取纸质车票",subwey.get(i)[0],subwey.get(i)[1])
flag=True
break
if not flag:
print("没有这个车次的信息")
- 使用字典的获取方法
subwey={
"G3333":["北京南-天津南","16:06","18:39","00:33"],
"G5555":["北京南-天津动","16:06","18:39","00:33"],
"G6666":["北京南-天津系","16:06","18:39","00:33"],
"G7777":["北京南-天津被","16:06","18:39","00:33"]
}
print("车次\t出发站-到达站\t出发时间\t达到时间\t历经时长")
use_choose = input("请输入购买的车次:")
info = subwey.get(use_choose,"车次不存在") # 这个info是一个列表,不存在的话,输出车次不存在
if info !="车次不存在":
name=input("请输入乘车人,如果有多为乘车人的话,用逗号隔开:")
print("已经购买了",use_choose,info[0],info[1],"开","姓名:",name)
else:
print("车次不存在")
4、模拟手机通讯录
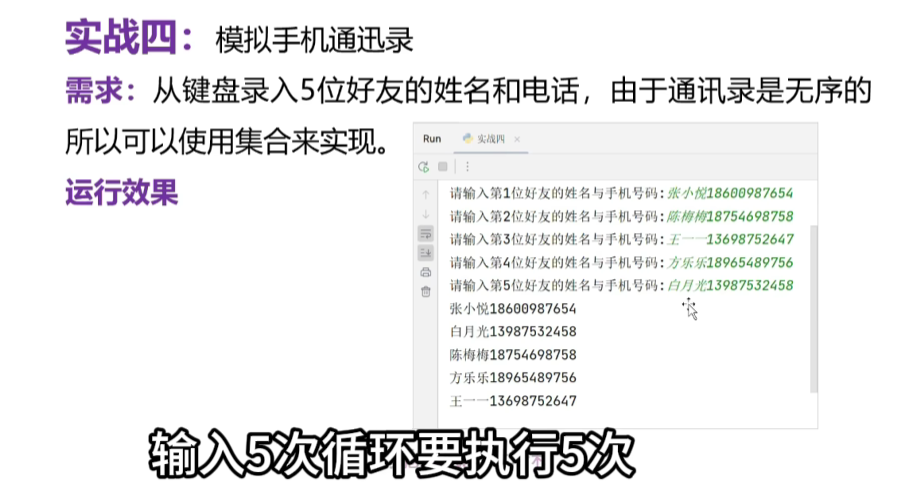
- 使用的是集合,因为通讯录是无序的
user_save=set()
for i in range(0,5):
name=input(f"请输入第{i+1}位姓名和电话号码:")
user_save.add(name)
for i in user_save:
print(i)
5、判断车牌归属地
6、统计字符串中出现指定字符的次数
- 不分区大小写
7、格式化输出商品的名称和单价
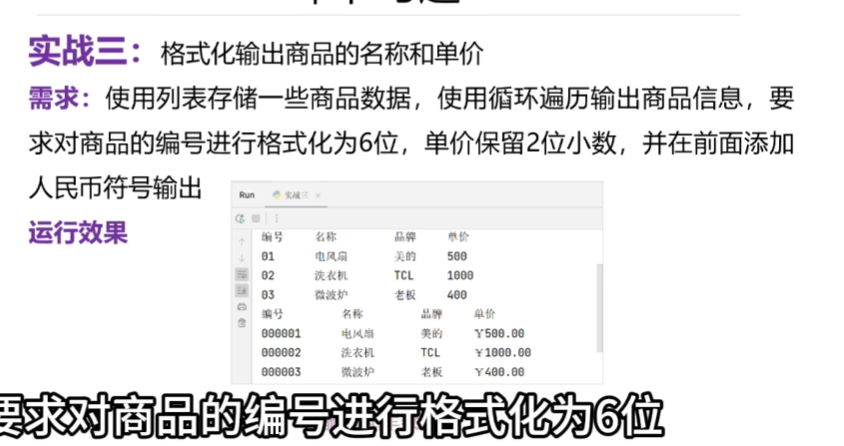

 浙公网安备 33010602011771号
浙公网安备 33010602011771号