pod详解
一、namespace
- 通过namespace命令空间将pod资源进行隔离
[root@k-master ~]# kubectl get ns
NAME STATUS AGE
calico-apiserver Active 18h
calico-system Active 18h
default Active 18h
kube-node-lease Active 18h
kube-public Active 18h
kube-system Active 18h
tigera-operator Active 18h
1、切换默认的命名空间
# 查看当前的命名空间
[root@k-master ~]# kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* kubernetes-admin@kubernetes kubernetes kubernetes-admin
# 切换默认的命名空间
[root@k-master ~]# kubectl config set-context --current --namespace kube-system
Context "kubernetes-admin@kubernetes" modified.
[root@k-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
coredns-5bbd96d687-rsnp6 1/1 Running 2 (56m ago) 18h
coredns-5bbd96d687-svq2d 1/1 Running 2 (56m ago) 18h
etcd-k-master 1/1 Running 2 (56m ago) 18h
kube-apiserver-k-master 1/1 Running 2 (56m ago) 18h
kube-controller-manager-k-master 1/1 Running 2 (56m ago) 18h
kube-proxy-fgct4 1/1 Running 3 (56m ago) 18h
kube-proxy-lfsvb 1/1 Running 2 (56m ago) 18h
kube-proxy-mk56p 1/1 Running 2 (56m ago) 18h
kube-scheduler-k-master 1/1 Running 2 (56m ago) 18h
metrics-server-7b8674ccdc-fdp29 1/1 Running 0 10m
# 写一个shell脚本,用户输入命令空间就能自动的进行切换
二、pod管理
1、pod怎么创建
1、命令行创建
kubectl run pod名字 --image 镜像 --镜像策略
[root@k-master ~]# kubectl run pod1 --image nginx
pod/pod1 created
[root@k-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod1 0/1 ContainerCreating 0 18s
# -o 输出 运行在node1上面,并且拉取了nginx镜像
[root@k-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 24s 10.244.82.140 k-node1 <none> <none>
2、yaml文件创建
[root@k-master yaml]# kubectl run p1 --image nginx --image-pull-policy IfNotPresent --dry-run=client -o yaml > p1.yaml
[root@k-master yaml]# cat p1.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: p1
name: p1
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: p1
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
[root@k-master yaml]# kubectl apply -f p1.yaml
pod/p1 created
[root@k-master yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
p1 1/1 Running 0 4s
[root@k-master yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
p1 1/1 Running 0 8s 10.244.82.150 k-node1 <none> <none>
[root@k-master yaml]#
2、镜像的下载策略
-
Always 每次都会联网,从网上下载最新的镜像,不管本地有没有镜像
-
Never 从来不联网,在本地寻找镜像
-
IfNotPresent 先从本地进行拉取,如果没有的话,就联网去网上寻找
3、pod重启策略
-
容器运行的是进程,这个进程是有镜像定义好的
-
restartPolicy
-
always 无论是正常退出还是非正常退出,都重启
-
OnFailure 遇到了错误重启
-
Never 从不重启
4、pod状态
-
pending pod被k8s接受了,但是镜像没有被下载
-
running 容器绑定到了某个节点,正常运行了
-
succeeded pod中所有容器都已成功终止,用于一次性任务
-
failed pod中容器都终止了,至少有一个是不正常退出
-
unknown 无法获取到pod状态,节点通信失败了
-
其他都是容器内部的状态了
5、初始化容器(init)
-
在pod创建之前,启动初始化容器提前做一些事情
-
有一个或者多个初始化容器,所有初始化容器加载之后,最后运行应用容器
-
案例,修改物理主机内核参数
-
容器是根据物理机的内核运行的,依靠的
-
容器默认与物理主机的内核是共享的,因此可以修改,但是需要权限
1、案例1
# 因为跑一个Pod,物理机有些参数不满足,因此需要使用init初始化容器修改物理主机的内核参数
[root@k-master yaml]# cat initpod.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: initpod
name: initpod
spec:
containers:
- image: nginx
name: initpod
resources: {}
initContainers:
- name: initpod2
image: alpine
imagePullPolicy: IfNotPresent
command: ["/sbin/sysctl","-w","vm.swappiness=35"]
securityContext:
privileged: true # 提权为root 就能修改主机上的内核参数了
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
# 如果不提权的话,就不能修改主机上的内核参数了
# 发现被修改了
[root@k-node2 ~]# sysctl -a | grep vm.swap
vm.swappiness = 35
2、案例2
-
提前挂载
-
宿主机上面的文件挂载到初始化容器上面,然后挂载到应用容器上面即可,这样创建的pod就会
-
使用一个临时目录创建一个文件夹,然后挂载到初始化容器中,写入了一个文件,因此临时目录也写入了这个文件
-
然后挂载到应用容器里面/test中,因此/test中也有写入的文件
[root@k-master yaml]# cat vpod.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: vpod
name: vpod
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: vpod
resources: {}
volumeMounts:
- name: testdir
mountPath: /test
initContainers:
- name: vinitpod
image: alpine
imagePullPolicy: IfNotPresent
command: ["sh","-c","echo 123 > /initest/test.txt"]
volumeMounts:
- name: testdir
mountPath: /initest
dnsPolicy: ClusterFirst
restartPolicy: Always
volumes:
- name: testdir # 起的挂载的名字,需要保持一致
emptyDir: {} # 宿主机随机创建一个临时目录
status: {}
6、静态pod
-
有一个问题,kube-system中有很多个pod,那么就是pod先起来,集群就创建好了还是集群创建好了,pod然后再创建,就是一个典型的先有鸡还是先有蛋的问题了
-
静态就是写好yaml就会自动的生成,删除了yaml就删除了pod
-
集群的核心pod都是静态的
[root@k-master ~]# cd /etc/kubernetes/
[root@k-master kubernetes]# ls
admin.conf kubelet.conf pki
controller-manager.conf manifests scheduler.conf
[root@k-master kubernetes]# cd manifests/
[root@k-master manifests]# ls
etcd.yaml kube-controller-manager.yaml
kube-apiserver.yaml kube-scheduler.yaml
- 在maifests里面创建一个yaml文件,会自动的生成pod,移走这个yaml或者删除这个yaml这个pod就会消失
[root@k-master manifests]# kubectl get pod
NAME READY STATUS RESTARTS AGE
centos8-demo 1/1 Running 5 (44m ago) 3d18h
[root@k-master manifests]# mv /root/p1.yaml .
[root@k-master manifests]# kubectl get pod
NAME READY STATUS RESTARTS AGE
centos8-demo 1/1 Running 5 (44m ago) 3d18h
p1-k-master 1/1 Running 1 (14s ago) 1s
7、pod调度策略和标签
1、scheduler机制
-
pod是怎么进行调度根据scheduler组件调整
-
scheduler工作流程
-
首先是过滤掉污点的主机
-
然后对剩余的主机进行打分,评测,然后把pod进行调度到主机上即可
-
2、设置标签(根据主机上的标签进行调度pod)
-
指定哪个节点上运行pod,是通过标签来实现的
-
标签格式为键值对
# 给k-node2打上一个标签,然后创建一个带有node2标签的pod,进行调度上去即可
[root@k-master yaml]# kubectl label nodes k-node2 hehe=666
node/k-node2 labeled
[root@k-master yaml]# cat p1.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: pod
spec:
nodeSelector: # 标签选择器
hehe: "666" # 选择主机标签为 hehe=666的主机
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: p1
status: {}
[root@k-master yaml]# kubectl get pod pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod 1/1 Running 0 2m47s 10.244.108.28 k-node2 <none> <none>
3、给主机标签的一些操作
- 修改标签
# 修改原有的标签的话,需要覆盖即可
[root@k-master yaml]# kubectl label nodes k-node2 hehe=qqq --overwrite
- 删除标签
# 格式为 键- 就能删除标签了
[root@k-master yaml]# kubectl label nodes k-node2 hehe-
node/k-node2 unlabeled
- 当然给pod打上标签也可以
4、特殊标签
[root@k-master ~]# kubectl get node --show-labels k-master
NAME STATUS ROLES AGE VERSION LABELS
k-master Ready control-plane 4d22h v1.26.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k-master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
# control-plane这个标签,可以修改的
# 主机加载的是node-role.kubernetes.io/control-plane= = 可以给值,也可以不给, 起作用的是 control-plane
[root@k-master ~]# kubectl label nodes k-master node-role.kubernetes.io/control-plane-
node/k-master unlabeled
[root@k-master ~]# kubectl label nodes k-master node-role.kubernetes.io/master=
node/k-master labeled
[root@k-master ~]# kubectl get node k-master
NAME STATUS ROLES AGE VERSION
k-master Ready master 4d22h v1.26.0
8、pod注释信息
[root@k-master ~]# kubectl annotate pod p2 aaa=kk
# 然后describe可以查看到
9、pod和控制器
-
之前创建的单个pod,都不是控制器控制的
-
因此删除pod就真的删除了,而不能再生了
-
控制器控制的pod,删除了这个pod的话,会自动的再次生成一个pod,这样就是一个高可用
-
控制器有很多种,deployment,daemoset,rs,job
三、污点
- pod调度是根据scheduler调度算法完成的,如果有多个节点,其中有一个节点需要进行维护或者检查,就设置一个污点,新创建的pod就不会被调度在这个节点上了
1、设置节点不可用(cordon)
- 新创建的pod不会被调度在这个上面
[root@k-master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k-master Ready master 4d23h v1.26.0
k-node1 Ready <none> 4d23h v1.26.0
k-node2 Ready <none> 4d23h v1.26.0
[root@k-master ~]# kubectl cordon k-node1
node/k-node1 cordoned
[root@k-master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k-master Ready master 4d23h v1.26.0
k-node1 Ready,SchedulingDisabled <none> 4d23h v1.26.0
k-node2 Ready <none> 4d23h v1.26.0
# SchedulingDisabled 调度被禁用了
# 取消cordon操作
[root@k-master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k-master Ready master 4d23h v1.26.0
k-node1 Ready,SchedulingDisabled <none> 4d23h v1.26.0
k-node2 Ready <none> 4d23h v1.26.0
[root@k-master ~]# kubectl uncordon k-node1
node/k-node1 uncordoned
[root@k-master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k-master Ready master 4d23h v1.26.0
k-node1 Ready <none> 4d23h v1.26.0
k-node2 Ready <none> 4d23h v1.26.0
2、drain操作
-
驱除所有pod
-
默认情况下,daemon-set的pod不会被删除
-
驱除所有pod然后节点不可用,不能被调度在上面
-
如果是单个pod就是删除
-
如果是deployment的话,那么就是不在这个节点上面创建,在其他允许的节点上面创建,因为是deployment是控制器
[root@k-master ~]# kubectl drain k-node1
node/k-node1 already cordoned
error: unable to drain node "k-node1" due to error:[cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): calico-system/calico-node-rtbfq, calico-system/csi-node-driver-qzcwr, kube-system/kube-proxy-mk56p, cannot delete Pods declare no controller (use --force to override): default/centos8-demo, default/p2], continuing command...
There are pending nodes to be drained:
k-node1
cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): calico-system/calico-node-rtbfq, calico-system/csi-node-driver-qzcwr, kube-system/kube-proxy-mk56p
cannot delete Pods declare no controller (use --force to override): default/centos8-demo, default/p2
# 取消的操作与之前的一样
[root@k-master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k-master Ready master 4d23h v1.26.0
k-node1 Ready,SchedulingDisabled <none> 4d23h v1.26.0
k-node2 Ready <none> 4d23h v1.26.0
[root@k-master ~]# kubectl uncordon k-node1
node/k-node1 uncordoned
[root@k-master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k-master Ready master 4d23h v1.26.0
k-node1 Ready <none> 4d23h v1.26.0
k-node2 Ready <none> 4d23h v1.26.0
- 上面的这些做法有点不合理,如果检查的时候,需要一个pod调度在这个节点上面,但是这个策略不允许调度在上面,就需要下面的污点了
2、设置节点或者pod污点
-
污点的等级
-
NoSchedule 新创建的pod不允许被调度在这个节点上面,已经存在的pod不会被删除
-
PreferNoSchedule 所有节点都不符合的话,最后调度在这个节点上面即可
-
NoExecute 新创建的pod不能调度在这个节点和已经存在的pod都被删除
-
1、查看节点污点
# 因为master上面有污点,所以默认情况下,不会调度在master上面
[root@k-master ~]# kubectl describe nodes k-master | grep -i taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule
2、给节点打上污点和删除污点
[root@k-master ~]# kubectl taint node k-node1 qqq:NoSchedule
node/k-node1 tainted
[root@k-master ~]# kubectl describe nodes k-node1|grep -i taint
Taints: qqq:NoSchedule
# 这样的话被调度的pod就不能调度在这个节点上面了
[root@k-master ~]# kubectl describe node k-node1 |grep -i taint
Taints: qqq:NoSchedule
# 删除污点
[root@k-master ~]# kubectl taint node k-node1 qqq-
node/k-node1 untainted
[root@k-master ~]# kubectl describe node k-node1 |grep -i taint
Taints: <none>
3、容忍度
- 就是这个节点上面即使有污点,也能被容忍,从而进行调度pod
[root@k-master ~]# kubectl describe node k-node1 | grep -i taint
Taints: qqq:NoSchedule
[root@k-master ~]# cat 1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod
labels:
aa: qq
spec:
tolerations: # 容忍度
- key: qqq # key
operator: Exists # 没有value的话,就使用Exists,而不是使用Equal
effect: NoSchedule # 污点的级别
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: p2
4、污点和cordon的区别
-
污点通过容忍这个污点的操作,可以调度pod
-
但是cordon的话,pod不能被调度
四、pod和命名空间
-
创建的pod默认是在default命名空间下创建的
-
如果一个pod里面有多个容器的话,这些容器都是共享这个网络空间的(ip地址,端口)
-
比如一个pod里面不能创建2个nginx,因为有一个监听到80端口了,除非改变另外一个监听的端口
-
创建多个pod的话,都是隔离的,不影响
-
创建了一个pod,里面的容器就共享一个名称空间1,这样的操作
[root@k-master yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod 2/2 Running 0 5m36s 10.244.82.156 k-node1 <none> <none>
# 这个pod的2个容器地址都是10.244.82.156
-
一个default空间下面的多个pod ,default/p1 default/p2 , p1和p2互不干扰,
-
当p1就相当于是一个虚拟主机,有多个nginx容器的话,就不能创建成功,因为都是监听的80端口,一个虚拟主机上面只有一个80端口
四、pod创建过程
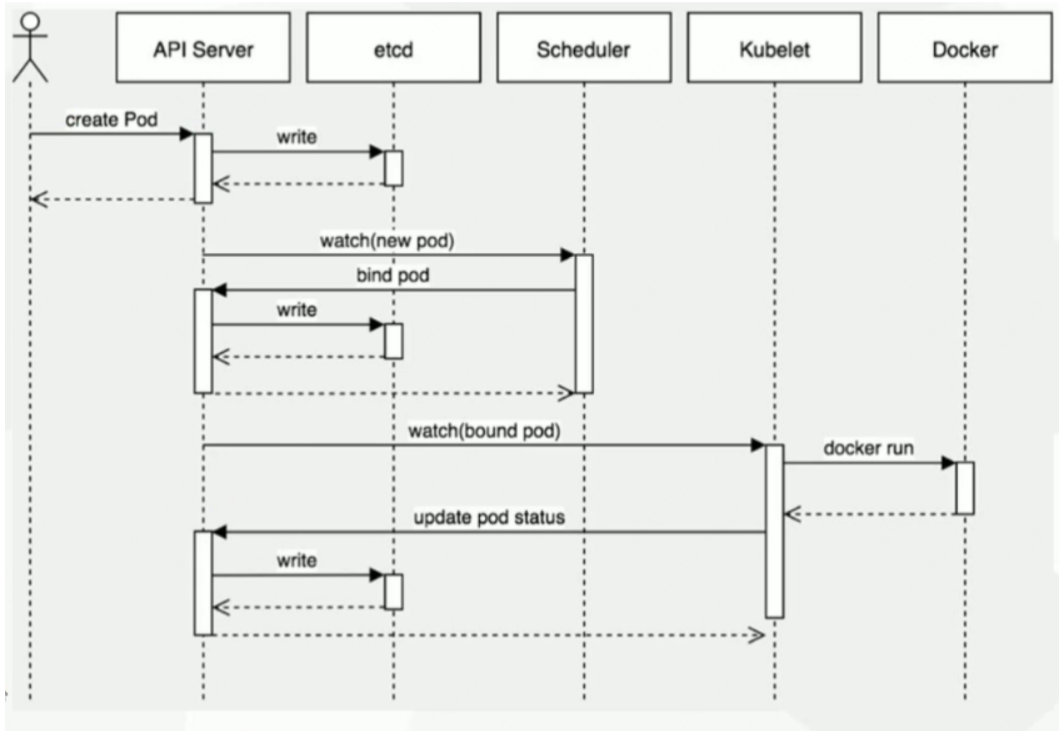
-
用户提交创建pod请求
-
api-server 处理用户请求,先存储pod数据到etcd中,写入成功,api-server将成功信息返回给客户端
-
scheduler通过watch机制监听到有新的pod后,会根据选出一个节点来进行调度到上面去
-
scheduler将成功绑定的信息写回到api-server,api-server将其写入到etcd中进行永久存储
-
kubelet接管pod创建,运行在目标节点上的kubelet监听pod资源中的变化
-
创建成功后kubelet返回信息给api-server,然后存入到etcd中
-
就是这样反复的一个写入过程
-
创建的pod在其他节点上面,就会运行相对应的容器,查看这个容器的相关信息也是可以的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号