

深入理解 Redis

数据库发展历史
![]() ==>就是IDVP--VADP哈哈哈哈
==>就是IDVP--VADP哈哈哈哈
网站的瓶颈是什么?
- 数据量太大,一个机器放不下;
- 数据的索引(B+树),一个机器的内存放不下
- 访问量(读写混合),一个服务器承受不了
发展过程:
1)优化数据结构和索引(垂直拆分+读写分离) --> 文件缓存(IO操作)--> Memcached(高速缓存插件)
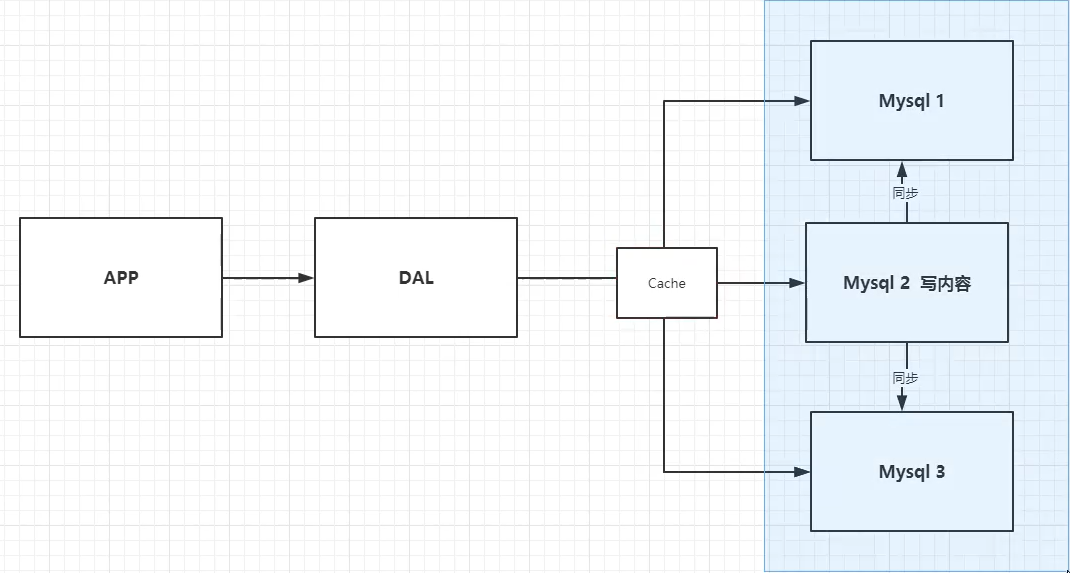
2)分库分表+水平拆分(MySQL集群)
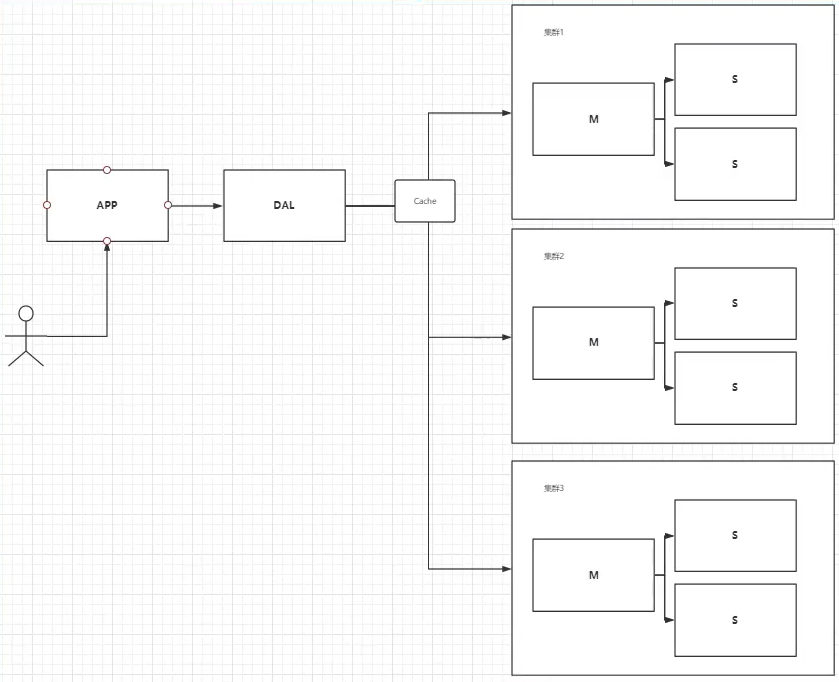

使用分库分表来解决写的压力 + MySQL集群
数据库拆分 优先级:
1)先用Redis等缓存挡一挡流量
2)读写分离(主从复制)
3)拆分数据:
3.1)垂直拆分【按业务】
3.2)水平拆分:先分库 [数据路由规则];再分表 [单表1000万以内];
什么是Nosql?
NoSQL = Not Only SQL(不仅仅是SQL)
泛指非关系型数据库,web2.0时代(音乐+视频),传统的关系数据库对付不了,尤其是高并发。
关系数据库RDBMS:表格,行+列,数据和关系都存在单独的表中
很多数据类型的信息,如:地理位置、社交网络、。。。不需要一个固定的格式,且不需要多于的操作就可以横向扩展
Map<String,Object> 键值对可以存一切,就是NoSQL的思想
Nosql特点:
方便扩展(数据之间没有关系,很好扩展)
大数据量,高性能(官方说明:11万次读/s 8万次写/s)(NoSQL的缓存记录级,是一种细粒度的缓存,性能会比较高!)
数据类型多样 5+3,不需要事先设计数据库


RDBMS + NoSQL 才是最好的(关系+非关系)
Nosql四大分类
-
KV键值对 Redis => 内容缓存、大数据量 高负载
-
文档型数据库 MongoDB =>Web应用;接近关系数据库
-
列存储数据库 HBase => 分布式文件系统
-
图形关系数据库 Neo4j => 社交网络、推荐系统、关系图谱
为什么需要Nosql?
用户的个人信息,社交网络,地理位置,用户日志等等都爆发式增长!

当今企业架构分析
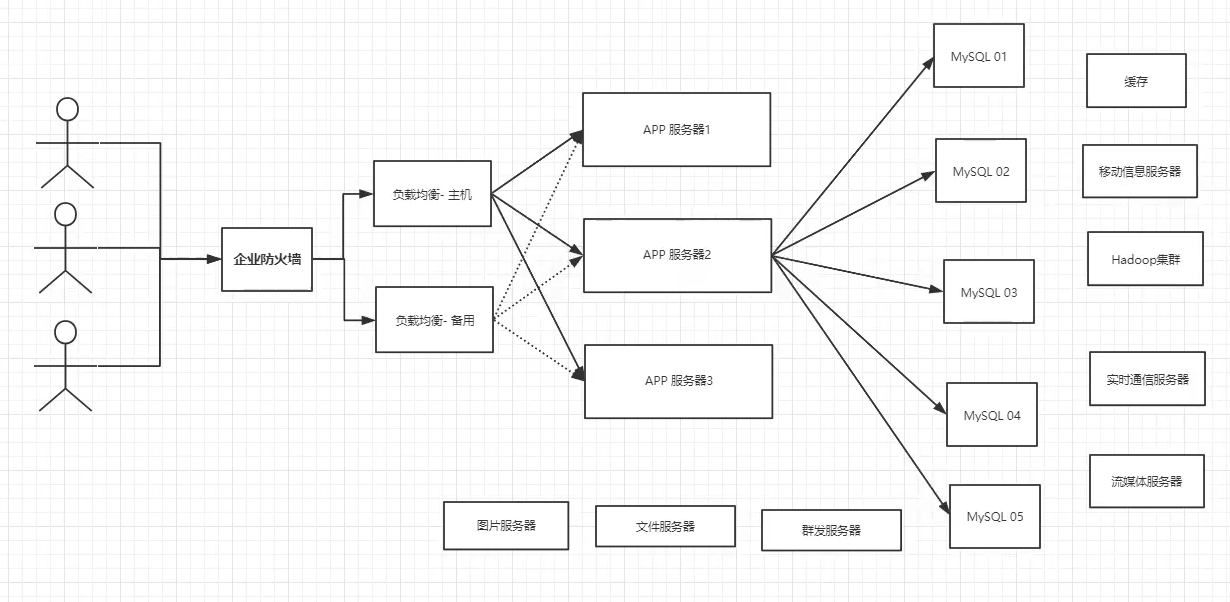
阿里巴巴技术演进
大量公司做的都是相同的业务(竞品协议)
![]()
 阿里巴巴在数据源之前加一层 UDSL,来统一操作数据源
阿里巴巴在数据源之前加一层 UDSL,来统一操作数据源
什么是Redis?
![]()
用处:
- 内存存储,持久化;内存中是断电丢失,持久化的两种机制(RDB+AOF)
- 效率高,可以用于高速缓存
- 发布订阅系统
- 地图信息分析
- 计时器、计数器(浏览量)
特性:
- 多样的数据类型
- 持久化
- 集群
- 事务
学习方法:
官网:redis.io 中文网:redis.cn
注意:
Redis推荐在Linux上搭建
Redis上手
Redis安装(Windows)

先后打开 server 和 cli
看到127.0.0.1:6379> 应该就好了!!
![]()
一些简单的使用:get set flushall

Redis安装(Linux服务器)
1)首先在Windows上面从官网 https://redis.io/ 去下载 tar.gz 型安装包,然后通过MobaXterm传到Linux机子上,
2)解压缩,后可以看到redis.conf 配置文件
3)然后 gcc -v 可查看gcc版本
之后直接 make 就可以了,等make完了之后,再输入make install 检查下即可
4)redis默认安装路径为:![]()
![]()
然后将redis.conf 复制到当前的安装目录下
5)之后修改配置文件 redis.conf(redis默认不是后台启动的)
找到(约257行) ![]() 从no改成yes
从no改成yes
6)通过指定的配置文件启动服务:![]() ##指定了配置文件
##指定了配置文件
7)启动客户端:![]()
然后测试一下:
8)关闭redis服务器:![]()
关闭client:exit 或者 Ctrl+C
redis-benchmark 性能测试
|
|
-h |
指定服务器主机名 |
127.0.0.1 |
|
|
-p |
指定服务器端口 |
6379 |
|
|
-s |
指定服务器 socket |
|
|
|
-c |
指定并发连接数 |
50 |
|
|
-n |
指定请求数 |
10000 |
|
|
-d |
以字节的形式指定 SET/GET 值的数据大小 |
3 |
![]()
然后查看具体的性能:
 100个并发客户端,每次写入3字节,只有1台服务器处理这些请求
100个并发客户端,每次写入3字节,只有1台服务器处理这些请求
Redis基础命令
redis默认16个数据库,默认使用第0个;
select 3 ##选择数据库 dbsize ##查看本数据库使用的空间大小 keys * ##查看(本库)所有的key
flushall ##清空所有的库 flushdb ##清空当前的库
move name 3 ##删除库3中的name字段
EXPIRE name 10 ##10秒过期
ttl name ##查看当前key的剩余时间
type name ##查看当前key的类型
set name jqy ##set get name ##get
info ##查看redis信息
save ##手动持久化
#### redis的命令在shell里面会自动提示字段,很方便
遇到不会的命令,可以到官网的命令来查找 redis.cn/commands.html
特性
Redis是单线程的!
Redis是基于内存操作,性能瓶颈是内存和网络带宽;
CPU不是它的性能瓶颈,所以用单线程;
Redis为什么快?
Redis是C语言写的,10万+ 的QPS(query per second),set和get分别10ms和3ms左右(1ms做到99%+)
- 内存存储:Redis是使用内存(in-memeroy)存储,没有磁盘IO上的开销
- 单线程实现:Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销
- 非阻塞IO:Redis使用多路复用IO技术,在poll,epool,kqueue选择最优IO实现
- 优化的数据结构:Redis有诸多可以直接应用的优化数据结构的实现,应用层可以直接使用原生的数据结构提升性能
Redis 数据类型 5+3
五大基本数据类型
String
set key1 value1 exists key1 ##判断是否存在 append key1 "hello" append key1 ",qingyang!" ##拼接字符串 strlen key1 ##获取长度
getrange key1 0 3 ##类似substring (左闭右闭区间)
setrange key1 0 xx ##替换 指定位置开始的字符串
set num 0
incr num ## 自增 1
decr num
incrby num 100 ## 加100
decrby num 25
setex key2 hello 30 ## set with expire 设置值&过期时间
setnx key2 hi ## set if not exist 不存在才设置,已存在则不会更新(如果直接set就可能会覆盖有的值)==》常用于:分布式锁
mset k1 v1 k2 v2 k3 v3 ##批量set
mget k1 k2 k3 ##批量get
msetnx k1 vv k4 v4 ##批量+不存在才设置==》msetnx原子性(都成功都失败)
get k4 ##(nil)
#### set对象(类似JSON格式的键值对)
set user:1{name:jqy,age:24}
mset user:1:name jqy user:1:age 24 ##与上一行等价
mget user:1:name user:1:age
##getset:不存在就设置,存在就替换;并且会返回当前值
getset nosql redis
(nil)
getset nosql mongodb
redis
get nosql
mongodb
现在的命令,Java里面都用Jedis里面的方法
List 链表
所有操作都是在String基础上,在之前加上 L
由于是链表,从两端push/pop效率比 数组随机操作,效率要高
list做一些规则,完成多功能:
- Stack 栈(Lpush Lpop)
- Queue 队列(Lpush Rpop)
- Array 数组
lpush list 1 ##left push
lpush list 2
lpush list 3
rpush list zero ##right push
lrange list 0 -1 ##显示list的全部内容
1) "3"
2) "2"
3) "1"
4) "zero"
llen list ##获得线性list的长度
(4)
lpop list ##left pop
(3)
rpop list ##right pop
(zero)
lindex list 1 ##通过下标获得list的值(这就是数组,随机查找)
lset list 1 one ##更新数组指定位置的值
lrem list 1 zero ##移除1个zero(如果有多个zero可以一次性移除多个)
ltrim ##截断(会减少元素数量)
linsert list before/after zero newWord
Set
set:无重复
sadd myset hello ##增加元素 sadd myset hi srem myset ##移除元素 sismember myset hello ##判断是否在set中 scard myset ##元素总个数
smembers myset ##列出所有元素
srandmember myset 2 #随机抽出2个
## Venn集合关系
sdiff set1 set2 ##差集
sinter set1 set2 ##交集
sunion set1 set2 ##并集
Hash
key-List<map> (key是hash表名)
hset myhash name jqy age 24
hgetall myhash
hkeys myhash
hvals myhash
hlen myhash
hget myhash name
hdel myhash age
hexist myhash age
...
Zset(有序集合)
应用:排行榜(有序+无重复)
zadd myset 1 one zadd myset 2 two 3 three zrange myset 0 -1
zrem myset ##实现排序 zadd student 80 jack zadd student 90 mary zadd student 95 yang zrangebyscore student -inf +inf ##负无穷到正无穷的范围,排序
zrem 移除
zrange 按范围展示
zcard 元素个数
三种特殊数据类型
Geo 地图
geoadd添加地理位置(经度,纬度)
经度(-180,+180);纬度(-85,+85)
java里面可以一次性导入 城市地理数据;
##添加一些城市的地理位置信息
127.0.0.1:6379> geoadd china:city 116 40 beijing 127.0.0.1:6379> geoadd china:city 121 31 shanghai 127.0.0.1:6379> geoadd china:city 107 30 chongqing 127.0.0.1:6379> geoadd china:city 114 22.5 shenzhen 127.0.0.1:6379> geoadd china:city 109 34 xian
##获取城市坐标 geopos china:city beijing ##获取距离 geodist china:city guangzhou hefei
##附近的人,获取半径内的点
georadiusbymember china:city hefei 1000 km ##按城市名来找
georadius china:city 117 31.5 1200 km
georadius china:city 117 31.5 1200 km withdist withcoord count 3
GEO的底层原理是zset,可以用zset的命令来操作geo
zrange china:city 0 -1
zrem china:city beijing
Hyperloglog
基数:不重复的元素
基数统计:网页UV(一个人访问一个网站多次,但还是算一个人)
传统方法:用set保存用户的id,然后统计id的数量;
缺点:如果不需要id的具体值,而只需要人数,则浪费空间
Hyperloglog特点:占用固定的空间:12KB==约2^64元素
缺点:有0.81%错误率,但UV一般忽略这个;如果不允许容错,就不能用这个了
pfadd uv1 a a b c d d d e e
pfcount uv1
(5)
pfadd uv2 c c e e f f g h i
(6)
pfcount uv2
pfmerge uv uv1 uv2 ##合并
pfcount uv
(9)
Bitmap
场景:用户bool状态(仅有0/1两种状态)
比如 用户是否登录,上班是否打卡
setbit weekday 0 0 setbit weekday 1 1 setbit weekday 2 1 setbit weekday 3 1 setbit weekday 4 1 setbit weekday 5 1 setbit weekday 6 0 getbit weekday 4
(1) bitcount weekday ##统计1的总数
(5)
Redis多种功能 / 机制
Redis事务操作(multi+exec)
Redis单条命令能保证原子性,但事务不保证原子性
Redis不存在隔离级别的概念
事务=》一次性、顺序性、排他性
Redis的事务:
- 开启事务(multi)
- 命令入队(...)
- 执行事务(exec)
multi ##开启事务
pfadd uv1 a a b c d d d e e
pfcount uv1
pfadd uv2 c c e e f f g h i
pfcount uv2
pfmerge uv uv1 uv2
pfcount uv
ping
exec ##执行事务
结果:

##如果在第二步命令入队的时候,想要放弃事务,可以用discard ##不建议用Ctrl+C discard
事务异常
1)编译型异常
==》所有命令,都不会执行
2)运行时异常
==》不保证原子性:错的语句报错、对的语句执行
Redis实现乐观锁(watch / unwatch)
==> 用 watch 加锁(乐观锁); unwatch 解锁
##测试多线程,watch当做redis的乐观锁操作,保证原子性 set money 100 watch money ##监视money multi DECRBY money 10 exec ##在这个执行之前,开启另一个线程,并修改money的值 ==>导致事务失败 (nil) ##(即使是改两次改回来也不行)
Redis实现发布订阅(作用同消息队列)
应用:聊天室、公众号
原理:
SUBSCRIBE => redis-server维护一个链表List:channel作为key,List<client>作为value
操作实例:
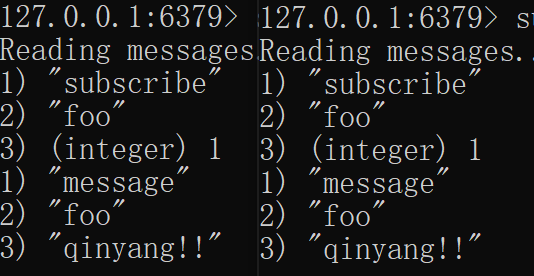
1)开两个client来订阅一个频道:

2)再开一个client来发布消息:

3)已经订阅的两个client会显示收到的信息:
基础API之Jedis详解
Jedis是java操作redis的中间件(jar包)
是SpringBoot整合的底层
首先,用maven导入依赖:
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.6.0</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.73</version> </dependency>
Jedis的hello world:
public class Test { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1",6379); //这里仅仅与本地redis-server相连,而没有连接数据库 // 所有redis操作的命令,都在 jedis. 里面 System.out.println(jedis.ping()); jedis.set("name","jqy"); //所有的操作命令和redis基本相同 jedis.set("age","24"); System.out.println("jedis.keys(\"*\") = " + jedis.keys("*")); } }
事务相关:
public class Test { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1",6379); jedis.flushAll(); //任务执行前先清空缓存(好习惯) JSONObject jsonObject = new JSONObject(); jsonObject.put("name","jqy"); jsonObject.put("age","24"); String result = jsonObject.toJSONString(); System.out.println("result = " + result); Transaction multi = jedis.multi();
jedis.watch(result); //多线程情况下要加并发锁,这里是乐观锁(这里加锁和下面的异常是两回事,异常时 事务保证的是原子性;并发冲突时,乐观锁保证并发正确性) try { multi.set("user1",result); // int x = 1/0; multi.set("user2",result); multi.exec(); } catch (Exception e) { multi.discard(); //出现异常,放弃事务 e.printStackTrace(); } finally { System.out.println(jedis.get("user1")); System.out.println(jedis.get("user2")); } jedis.close(); //关闭jedis连接(和上述事务无关) } }
SpringBoot集成Redis操作
1)导入maven
Spring数据操作都封装在Spring-data中,比如:jpa jdbc redis mongodb
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <version>2.4.5</version> </dependency>
按Ctrl+左键,点进去看到:
<artifactId>spring-boot-starter</artifactId> <artifactId>spring-data-redis</artifactId> <artifactId>lettuce-core</artifactId>
说明:在springboot 2.X 之后,原来使用的jedis被替换成了 lettuce(生菜)
jedis:采用的直连,多线程操作时不安全;用jedis pool连接池来解决并发问题,但效果一般
lettuce:采用netty,实例可以在多个线程中进行共享,线程安全,且不用开连接池
2)写配置文件
写配置文件方法论:
1)直接网上找 相关博客(二手资料)
2)看源码(一手资料):
在项目文件目录的 External Libraries里面搜: autoconfig,找到:
![]()
再进去搜redis:

点RedisAutoConfiguration,进去找到:
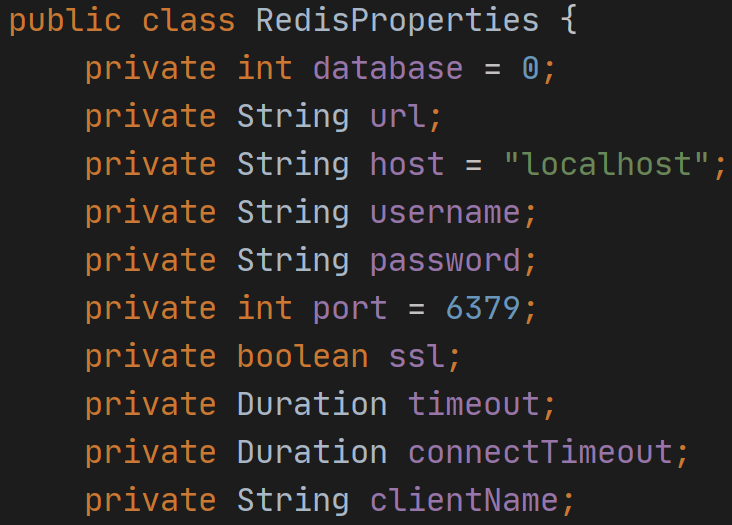
![]()
再点进去RedisProperties就可以看到所有属性了(15个属性,图中仅部分)
写配置文件application.properties
spring.redis.host = 127.0.0.1
spring.redis.port = 6379
3)测试
先写个类
@Data @AllArgsConstructor public class User{ private String name; private int age; }
测试:
@SpringBootTest class DemoApplicationTests { @Autowired private RedisTemplate redisTemplate; //redis模板,内含各种常用的API @Test public void Test() throws JsonProcessingException { User user = new User("jqy", 24); String jsonUser = new ObjectMapper().writeValueAsString(user); //序列化(将对象序列化为String) redisTemplate.opsForValue().set("user",jsonUser); System.out.println("redisTemplate.opsForValue().get(\"user\") = " + redisTemplate.opsForValue().get("user")); //一般在企业都会用RedisUtils而不是用原生的代码 // redisTemplate.opsForValue().set("user",user); //这样会报错,不能直接用对象,要序列化为String } }
![]()
自定义RedisTemplate
序列化
但是这样需要每次都手动序列化,繁琐;
所以希望能够通过配置,来AOP自动进行序列化:
首先将实体类 类名后面加上
implements Serializable
然后写自定义配置RedisConfig:
@Configuration public class RedisConfig { @Bean @SuppressWarnings("all") public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<String, Object>(); //为了方便使用(避免强制转换),将map的key从Object改为String template.setConnectionFactory(factory); Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // 配置具体的序列化方式 // key采用String的序列化方式 template.setKeySerializer(stringRedisSerializer); // hash的key也采用String的序列化方式 template.setHashKeySerializer(stringRedisSerializer); // value序列化方式采用jackson template.setValueSerializer(jackson2JsonRedisSerializer); // hash的value序列化方式采用jackson template.setHashValueSerializer(jackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; } }
@Qualifier
@Autowired @Qualifier("redisTemplate") private RedisTemplate redisTemplate; //redis模板,内含各种常用的API
Redis配置文件
需要仔细看源码的时候直接看 redis.config 文件
常用配置:
## redis config spring.redis.host= 127.0.0.1 spring.redis.port= 6379 ##集群的时候要修改端口 spring.redis.password= 123456 # 最大空闲连接数 spring.redis.jedis.pool.max-active=8 # 最小空闲连接数 spring.redis.jedis.pool.max-idle=8 # 等待可用连接的最大时间,负数为不限制 spring.redis.jedis.pool.max-wait=-1 # 最大活跃连接数,负数为不限制 spring.redis.jedis.pool.min-idle=1 # 数据库连接超时时间,2.0 中该参数的类型为Duration,这里在配置的时候需要指明单位 1.x可以将此参数配置10000 单位是ms # 连接池配置,2.0中直接使用jedis或者lettuce配置连接池 spring.redis.timeout=60s spring.redis.database=0
daemonize no ##守护进程no改为yes logfile "" ##输出log文件位置 databases 16 ##数据库的数量,默认是16个
## 【快照Snapshot】内存数据库的持久化 ## redis是内存数据库,如果没有持久化,那么数据断电即失 save 3600 1 ##3600s内,如果有1 key进行了修改,我们进行持久化操作 save 300 100 save 60 10000
![]()
Redis持久化(做缓存的时候,不用持久化;只有做数据库才要)
redis是内存数据库,如果没有持久化,那么数据断电即失 ==> 所以要做持久化
如果是用redis给其他数据库做缓存,那就不用持久化了
1)RDB(Redis DataBase)==》默认方式
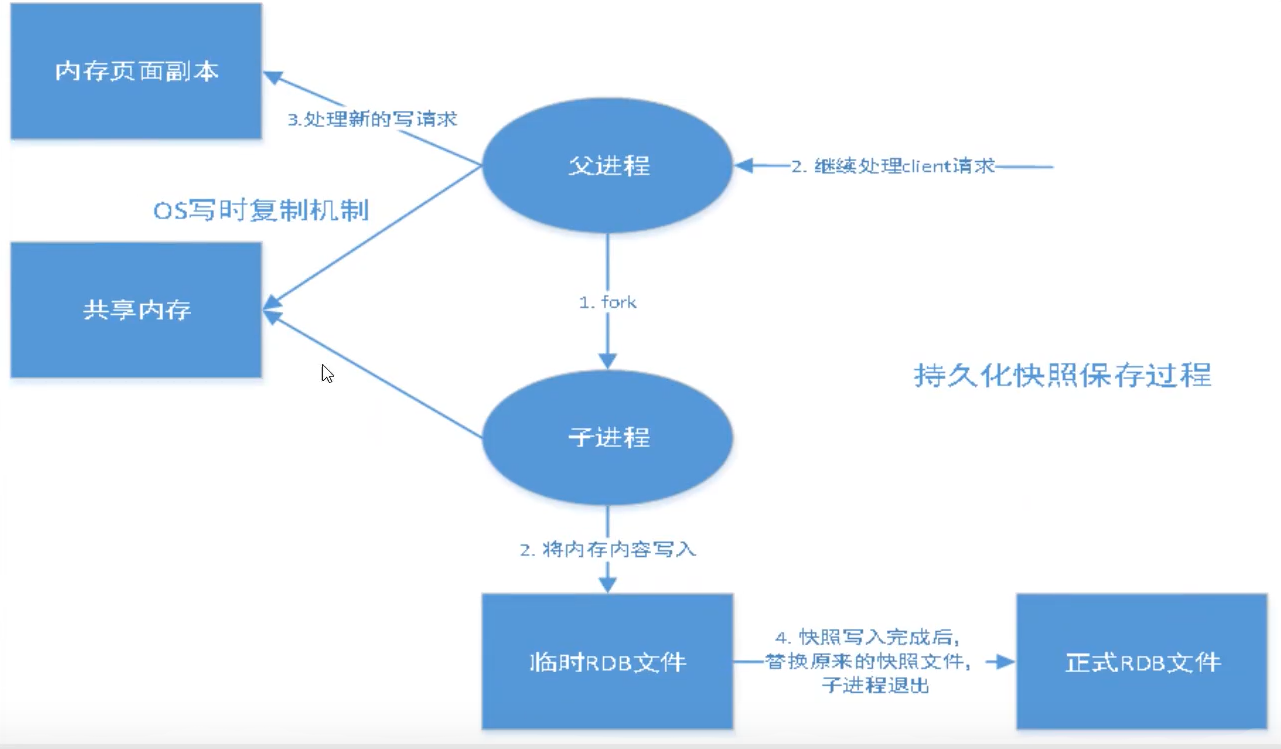
思想:
空间换时间,fork一个子进程,单独管理快照 ==> 数据写入临时文件 dump.rdb
父进程处理客户端请求,子进程单独管理快照(rdb),互不影响 性能高
优点:
备份由子进程来完成,不影响父进程的性能
适合大规模数据恢复 dump.rdb
二进制压缩,占用空间小
缺点:
save条件没有触发,或者宕机,那么最后一批的修改数据就没有了
子进程占用内存空间
dump.rdb触发规则:

## 【快照Snapshot】内存数据库的持久化 ## redis是内存数据库,如果没有持久化,那么数据断电即失 save 3600 1 ##3600s内,如果有1 key进行了修改,我们进行持久化操作 save 300 100 save 60 10000
![]() ==》usr/local/bin
==》usr/local/bin
2)AOF(Append Only File)
将我们的所有命令都记录下来,history,恢复的时候将命令都执行一遍
以日志的形式,记录 所有的 写操作,读不记录;
生成文件 appendonly.aof
appendonly no ## 将此处的no改为yes就可以使用AOF了
redis-check-aof --fix 可以尝试修复损坏的aof文件
aof默认文件会无限追加,超过size就再多来一个size(默认64M太小,建议设置到5G以上)
同步策略:
1)每次修改都同步 2)每秒同步一次 3)从不同步
优点:
文件完整性会更好
文本存储,可以看到每一个操作
缺点:
运行效率低,多次读写aof文件(IO操作)
aof 文件占用的空间比 rdb要大
==》费 时间空间,换完整性
同时开启RDB和AOF ==> 会优先使用AOF (ps:反正已经费了时间空间了,就用完整性好的那个)
Redis缓存更新
一、过期策略
1. 定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会全部立即清除。
该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
2. 惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。
该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
所有键读写命令执行之前都会调用 expireIfNeeded 函数对其进行检查,如果过期,则删除该键,然后执行键不存在的操作;未过期则不作操作,继续执行原有的命令。
3. 定期过期
每隔一定的时间,会扫描一定数量的数据库的expires字典中一部分的key,并清除其中已过期的key。
该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU & 内存,达到最优的平衡。
【过期策略】代码实现:(惰性+定期,双策略)
1. 设置过期时间:
//设置过期时间: EXPIRE <key> <ttl> :表示将键 key 的生存时间设置为 ttl 秒。 //(ttl设置为30) PEXPIRE <key> <ttl> :表示将键 key 的生存时间设置为 ttl 毫秒。 EXPIREAT <key> <timestamp> :表示将键 key 的生存时间设置为 timestamp 所指定的秒数时间戳。 //移除过期时间: PERSIST <key> :表示将key的过期时间移除。 //查询剩余时间: TTL <key> :以秒的单位返回键 key 的剩余生存时间。
2.1 惰性-删除:
所有键 读写命令执行之前,都会 调用 expireIfNeeded() 函数对其进行检查,
如果过期,则删除该键,然后执行键不存在的操作;未过期则不作操作,继续执行原有的命令。
2.2 定期-删除:
修改配置文件redis.conf 的 hz 选项
hz 10 //每秒10次(默认)
(hz的取值范围是1~500,通常不建议超过100) (1/10/100,根据任务来,不要超过25%CPU时间)
(ttl=30,hz=1表示30.0s-30.1s内进行更新)
二、内存淘汰策略:(应对内存不足,用LRU策略)
noeviction:默认策略,不会删除任何数据,拒绝所有写入操作,并返回OOM错误 ,此时Redis只响应读操作
volatile-random:随机删除过期键(expire),直到腾出足够空间为止
volatile-ttl:根据键值对象的TTL(剩余时间(time to live) )属性,删除最近将要过期数据。如果没有,回退到noeviction策略
volatile-lru:根据LRU删除过期键(expire),直到腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略
volatile-lfu:回收最少使用频次的键值(LFU算法),但仅限于在过期键值集合中
allkeys-random:随机删除所有键,直到腾出足够空间为止(不推荐)
allkeys-lfu:回收最少使用 频次 的键值(LFU算法)frequency
allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止
实现:
在配置文件redis.conf 中,
设定最大内存: maxmemory <bytes>
设定内存淘汰策略:maxmemory-policy allkeys-lru
LRU:
LRU 全称是 Least Recently Used,即最近最少使用。
经典LRU实现思路:
(基于HashMap + 双向链表)
head头部最常用MRU,尾部tail最不常用LRU
首先预先设置LRU的容量,如果存储满了,则删除双向链表的尾部,每次新增和访问数据,则把新的节点增加到头部,或者把已经存在的节点移动到头部。
性能花费:空间O(N),
时间:新增O(1)替换O(1)删除O(1)
Redis中的LRU:
Redis中的LRU与常规的LRU实现并不相同,常规LRU会准确的淘汰掉队头的元素,
Redis的LRU并不维护队列,
根据配置的策略,从key(所有key/过期key)中随机选择N个(N可以配置,10就挺好)
然后再从这N个键中选出最久没有使用的一个key进行淘汰。

LFU:
LFU算法是Redis4.0新加的淘汰策略。它的全称是Least Frequently Used
核心思想:是根据key的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来。
优点:避免
实现:需要维护一个队列 记录所有数据的访问记录,每个数据都需要维护引用计数。
 新加入是1,1最容易淘汰(并列时,按照时间淘汰)
新加入是1,1最容易淘汰(并列时,按照时间淘汰)
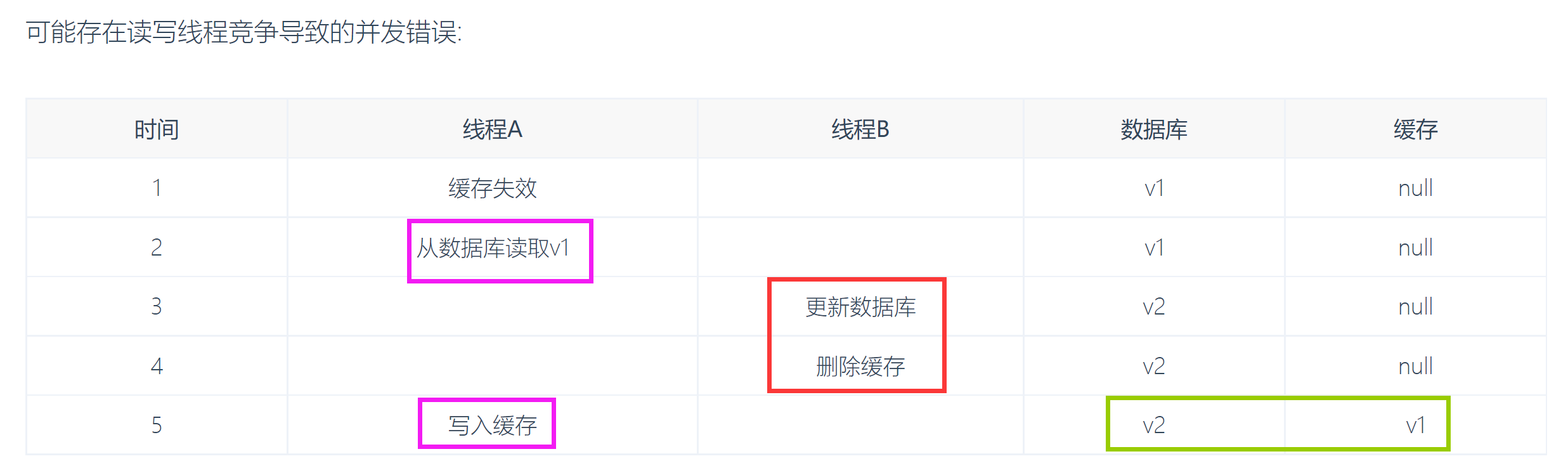
三、更新方式: (关于DB & 缓存) (4+1)(都会导致一致性问题==》原因是并发的“后开始-先结束”)
(1)先更新数据库,再删除缓存(最常用)
(2)先删除缓存,再更新数据库
(3)先更新缓存,再更新数据库
(4)先更新数据库,再更新缓存
(5)写回(不是强一致性,且可能丢失):
只更新缓存,不更新数据库;缓存异步批量更新数据库(持久化)
缓存数据 与 DB 异步;可能合并多次缓存操作;
并发 造成不一致的场景(仅针对方法一:先更DB、再删缓存):
Redis集群环境搭建
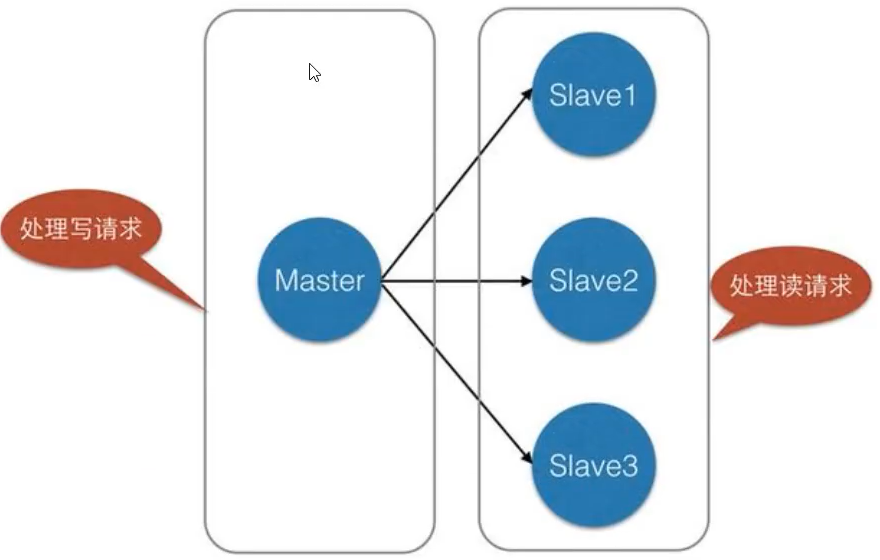
数据是单向的:主=>从
主从复制&读写分离:
主机以写为主,从机以读为主
最低配:一主二从 3台机子
作用:
1)数据冗余:主从复制 实现了数据的热备份
2)故障恢复
3)负载均衡:master以写为主,slave以读为主。大大提高并发量
4)高可用(集群)基石
为什么需要Redis集群?
1、单点故障(宕机)
2、内存有限,单台内存不应该超过20G
大部分项目都是“多读少些”,适合 读写分离+主从复制
集群配置实例
1)由不同配置的conf,来开启多个master
只需要配置slave,不需要配置master
info replication ##查看基本信息:role/connected_slave等
首先复制多个配置文件:
cp redis.conf redis6379.conf
cp redis.conf redis6380.conf
cp redis.conf redis6381.conf
修改配置文件
##修改6个参数,每个机子的配置要不重名 port 6379 pidfile /var/run/redis_6379.pid logfile "" dbfilename dump.rdb
## replicaof <masterip> <masterport>
## masterauth <master-password> ## 例子:port 6379 pidfile /var/run/redis_6379.pid logfile "6379.log" dbfilename dump6379.rdb
replicaof <127.0.0.1> <6379>
masterauth <123456> ## 然后设置6380 6381 6382...即可
查看redis的相关进程:
ps -ef|grep redis

可见,开启了3个 server
2)只留一个master,其余转为slave
配置slave,让slave认master:
SLAVEOF 127.0.0.1 6379 ##配置slave
然后info replication查看信息,发现已成功变成slave
如果要一劳永逸,就要在配置文件里面改。
vim redis.conf
## replicaof <masterip> <masterport>
## masterauth <master-password>
特性:
master写之后,slave自动获取master的更新;
slave只读,不可以写
宕 机
1)master宕机
master断开后,slave的读不受影响;
不过由于没有 "写功能" 了,slave的数据也不会有更新了
如果master又回来了,则一切照常运行
2)slave宕机
slave宕机后,如果连回来,则此时默认是master,也就拿不到原来master的信息
不过只要认好了原先的master,则slave立马就可以读到所有master的数据了(因为全量复制)
全量复制:slave初次连接 / 断后重连master
增量复制:master-slave持续连接时,会是增量复制,不然太费了
==》反正总的原则是:保证主从一致
旧master宕机后 手动配 新master
首先,每个slave摆脱 旧master:
SLAVEOF no one
然后,手动设置 新master即可:
SLAVEOF 127.0.0.1 6379 ##配置slave
如果此时旧的master恢复了,就不是master了
哨兵模式(自动选取master)
1)什么是哨兵模式?
监控当前master的状态,后面通过投票的模式来决定新master
需要设置一个哨兵sentinel:这是一个独立的进程,
用于监视所有Redis服务器(通过发命令,等待请求)
 然而,怕哨兵也宕机,就设置多个哨兵:
然而,怕哨兵也宕机,就设置多个哨兵: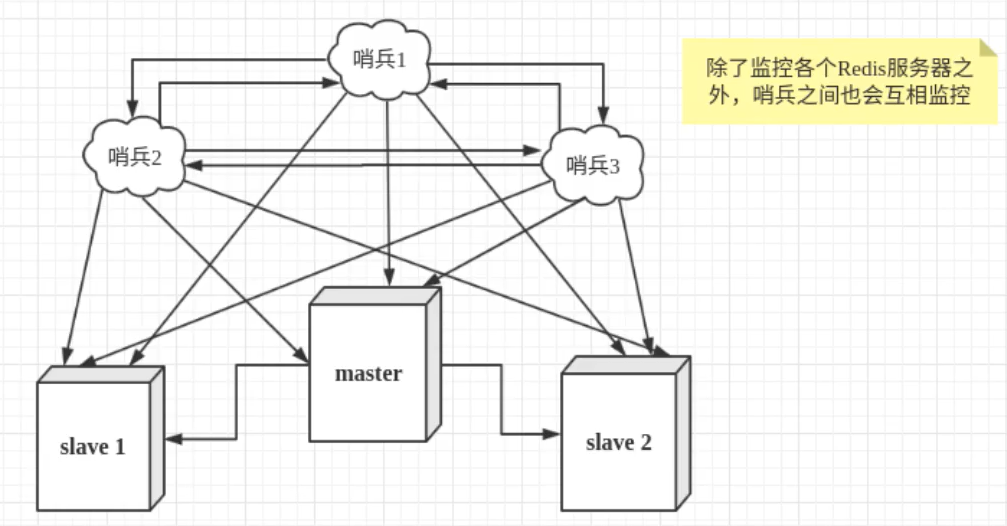
主观下线:当一个哨兵发现宕机,不会立马重新选举
客观下线:当达到一定数量的哨兵投票后,才会决定是否 重新选举(故障转移 failover)
2)配置哨兵模式
配置哨兵配置文件 sentinel.conf
最基本、最简单的选举方式:
sentinel monitor myredis 127.0.0.1 6379 1 ##1代表master宕机后,投票slave号
然后启动
redis-sentinel sentinel.conf
然后master宕机后,会failover故障转移,也就是选新的master
3)哨兵模式 特点
优点:
1)哨兵集群,基于主从复制,所有主从复制的优点它都有:数据冗余+故障恢复+负载均衡
2)主从可以切换,可用性高
3)自动配置,比手动更好(普通主从模式的改进,就是手动=>自动)
缺点:
1)Redis不好在线扩容:每一个存的内容都一样,难以扩容
2)哨兵模式的配置很繁琐,在线扩容需要改很多配置文件、非常麻烦(公司里面运维来配置)
注意:
旧的master回来后,就不是master了
缓存异常
缓存穿透(原因是cache查不到导致)
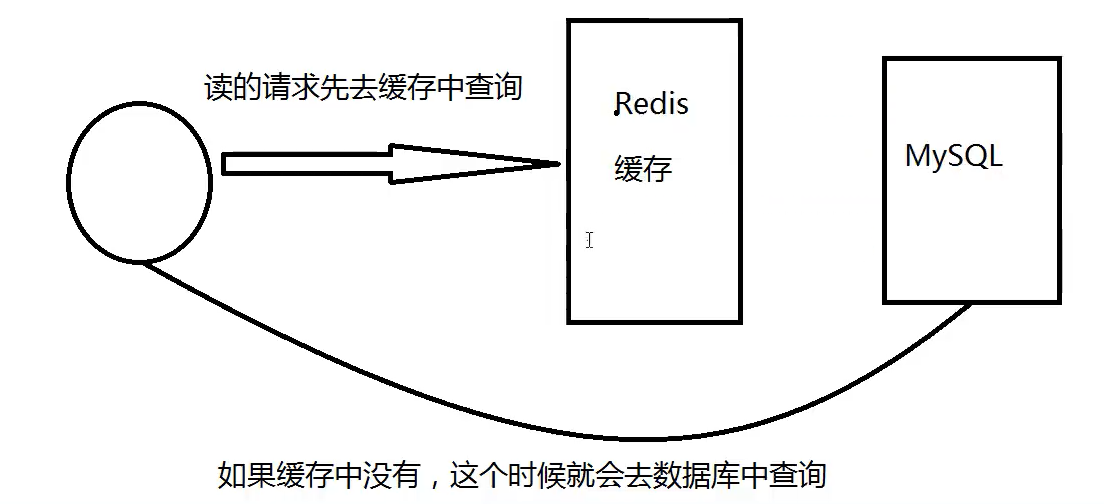 redis中没有,就会去DB查询,当DB压力过大就会崩掉
redis中没有,就会去DB查询,当DB压力过大就会崩掉
解决方法 =>
1)布隆过滤器
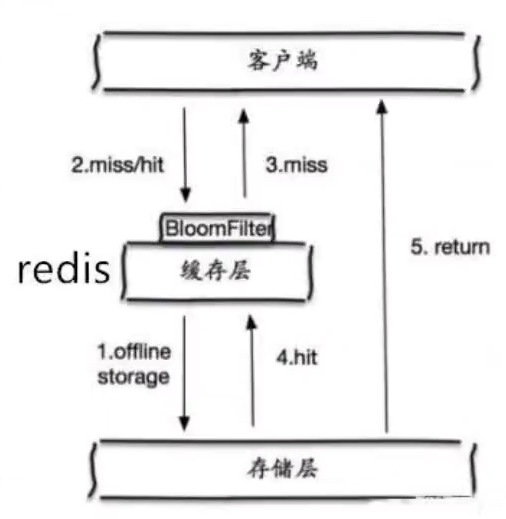
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,
在控制层先进行校验,不符合则丢弃
2)缓存空对象
平时为null不缓存,这里也去缓存。
当存储层不命中后,即使返回的空对象也将其缓存起来,
同时设置一个过期时间,之后再访问会从缓存走,而不是DB
存在两个问题:
1、存空对象、过期时间,消耗空间(空间换时间)
2、一致性下降(一致性换时间)
缓存击穿(缓存过期瞬间)
缓存key过期瞬间,请求会访问DB然后回写cache,大量并发请求导致瞬间压力过大。
解决方法:
1)设置 热点数据 永不过期;
2)分布式锁 synchronized(不适合高并发)。保证只有一个线程访问DB,其余进行等待。
缓存雪崩(Redis宕机)
缓存集中过期失效,导致 Redis宕机
解决方案:
1)redis集群:多几台redis
2)限流:通过加锁、队列
3)降级:普通服务停掉,保证核心服务
4)数据预热:正式部署前,把数据预先加载到缓存,然后手动设置不同的过期时间,让缓存失效时间点尽量均匀
缓存预热 ==》解决“冷启动”
- 统计 高频数据
- LRU数据删除策略,构建留存队列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号