


查找文献
最近好长时间不更新了,是因为学业负担加重,再加上经常熬夜,马上考试,真是令人头秃(我才不会告诉你们我是懒得写)
题目链接:https://www.luogu.com.cn/problem/P5318
题目描述
小K 喜欢翻看洛谷博客获取知识。每篇文章可能会有若干个(也有可能没有)参考文献的链接指向别的博客文章。小K 求知欲旺盛,如果他看了某篇文章,那么他一定会去看这篇文章的参考文献(如果他之前已经看过这篇参考文献的话就不用再看它了)。
假设洛谷博客里面一共有 n(n\le10^5)n(n≤105) 篇文章(编号为 1 到 nn)以及 m(m\le10^6)m(m≤106) 条参考文献引用关系。目前小 K 已经打开了编号为 1 的一篇文章,请帮助小 K 设计一种方法,使小 K 可以不重复、不遗漏的看完所有他能看到的文章。
这边是已经整理好的参考文献关系图,其中,文献 X → Y 表示文章 X 有参考文献 Y。不保证编号为 1 的文章没有被其他文章引用。
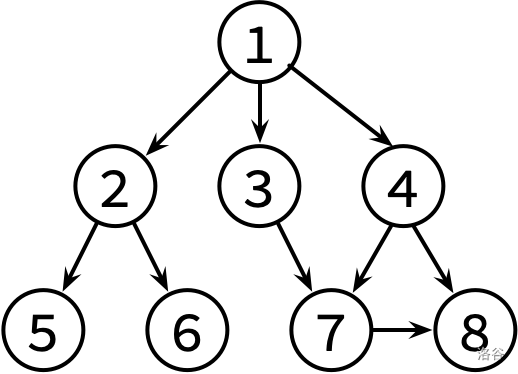
请对这个图分别进行 DFS 和 BFS,并输出遍历结果。如果有很多篇文章可以参阅,请先看编号较小的那篇(因此你可能需要先排序)。
输入格式
无
输出格式
无
输入输出样例
8 9
1 2
1 3
1 4
2 5
2 6
3 7
4 7
4 8
7 8
1 2 5 6 3 7 8 4 1 2 3 4 5 6 7 8
引:
首先,我们用一个结构体vector(为了节省空间,咱用vector来存)存储每个边的起点和终点,然后用一个二维vector(也就是一个vector数组)存储边的信息。
这个存储方法可能有点难理解,不过其实也没那么难:我们用ee[aa][bb]=cc,来表示顶点aa的第bb条边是cc号边。咱举个栗子,还是拿样例说吧:
8 9
1 2 //0号边(由于vector的下标是从0开始的,咱就“入乡随俗”,从0开始)
1 3 //1号边
1 4 //2号边
2 5 //3号边
2 6 //4号边
3 7 //5号边
4 7 //6号边
4 8 //7号边
7 8 //8号边
最后二维vector中的存储会如下所示:
0 1 2 //1号顶点连着0、1、2号边
3 4 //2号顶点连着3、4号边
5 //3号顶点连着5号边
6 7 //4号顶点连着6、7号边
//5号顶点没有边
//6号顶点没有边
8 //7号顶点连着8号边
//8号顶点没有边
看是不是对上号了?这个方法比较好懂,又节省空间,是个好方法。(此方法由大佬vectorwyx发明)
最后,别忘了题目要求:“如果有很多篇文章可以参阅,请先看编号较小的那篇”
那就排序呗!咱们按照题目要求,按照终点从小到大排列,如果终点相同按起点从小到大排列 注意我们说的第几号边是指排序后的序号
1 int uu,vv;
2 int m,n;
3 struct ed{ //存边结构体
4 int u,v;//u:起点,v:终点
5 };
6 vector <int> e[100005];//
7 vector <ed> s;
8 bool cmp(ed x,ed y){//排序
9 if(x.v==y.v)
10 return x.u<y.u;
11 else return x.v<y.v;
12 }
13 bool v1[100005]={0}, v2[100005]={0};
14 //v数组用来判断有没有遍历过这个顶点,v1用于深搜,v2用于广搜(我才不会告诉你我懒得memset呢)
//dfs
void dfs(int x){
v1[x]=1;//标记
cout<<x<<" ";
for(int i=0;i<e[x].size();i++){//一条边一条边地找
int p=s[e[x][i]].v;//找出当前这条边(也就是e[x][i])的终点
if(!v1[p]){
dfs(p);//接着往下搜
}
}
}
//bfs
void bfs(int x){
queue<int> q;//没有队列还叫广搜吗?!
q.push(x);//先把第一个顶点压进去
cout<<x<<" ";
v2[x]=1;
while(!q.empty()){//广搜板子 详情见:https://www.cnblogs.com/tflsnoi/p/13767816.html
int fro=q.front(); //把队首取出来
for(int i=0;i<e[fro].size();i++){
int front=s[e[fro][i]].v;//和dfs一样,把当前这条边(也就是e[x][i])的终点压进去
if(!v2[front]){//判定
q.push(front);//把符合条件的点压进去
cout<<front<<" ";//输出~
v2[front]=1;//标记
}
}
q.pop();//用完就扔
}
}
总体是这样的:
#include<bits/stdc++.h>//头文件yyds
#include<queue>
#include<vector>
using namespace std;
int uu,vv;
int m,n;
struct ed{ //存边结构体
int u,v;//u:起点,v:终点
};
vector <int> e[100005];//
vector <ed> s;
bool cmp(ed x,ed y){//排序
if(x.v==y.v)
return x.u<y.u;
else return x.v<y.v;
}
bool v1[100005]={0}, v2[100005]={0};
//v数组用来判断有没有遍历过这个顶点,v1用于深搜,v2用于广搜(我才不会告诉你我懒得memset呢)
//dfs
void dfs(int x){
v1[x]=1;//标记
cout<<x<<" ";
for(int i=0;i<e[x].size();i++){//一条边一条边地找
int p=s[e[x][i]].v;//找出当前这条边(也就是e[x][i])的终点
if(!v1[p]){
dfs(p);//接着往下搜
}
}
}
//bfs
void bfs(int x){
queue<int> q;//没有队列还叫广搜吗?!
q.push(x);//先把第一个顶点压进去
cout<<x<<" ";
v2[x]=1;
while(!q.empty()){//广搜板子 详情见:https://www.cnblogs.com/tflsnoi/p/13767816.html
int fro=q.front(); //把队首取出来
for(int i=0;i<e[fro].size();i++){
int front=s[e[fro][i]].v;//和dfs一样,把当前这条边(也就是e[x][i])的终点压进去
if(!v2[front]){//判定
q.push(front);//把符合条件的点压进去
cout<<front<<" ";//输出~
v2[front]=1;//标记
}
}
q.pop();//用完就扔了
}
}
int main(){
cin>>n>>m;//n个顶点,m条边
for(int i=0;i<m;i++){//m条边
cin>>uu>>vv;
s.push_back((ed){uu,vv});//初始化存边的s数组
}
sort(s.begin(),s.end(),cmp);
//优雅地排个序(别忘了vector的操作:start返回第一个(指针),end返回最后一个(指针)
for(int i=0;i<m;i++){
e[s[i].u].push_back(i);
}
//初始化e数组,在e[s[i].u](也就是i号边的起点s[i].u连接的边的数组)中存入i号边
dfs(1);
cout<<endl;
bfs(1);
return 0;
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号