
实验要求
结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
- 以fork和execve系统调用为例分析中断上下文的切换
- 分析execve系统调用中断上下文的特殊之处
- 分析fork子进程启动执行时进程上下文的特殊之处
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
完成一篇博客总结分析Linux系统的一般执行过程,以期对Linux系统的整体运作形成一套逻辑自洽的模型,并能将所学的各种OS和Linux内核知识/原理融通进模型中。
1、fork函数
零:返回到新创建的子进程。
正值:返回父进程或调电者。该值包含新创建的子进程的进程ID
pid_t fork( void);
#include<unistd.h>
定义函数:
int execve(const char * filename,char * const argv[ ],char * const envp[ ]);
如果执行成功则函数不会返回,执行失败则直接返回-1.
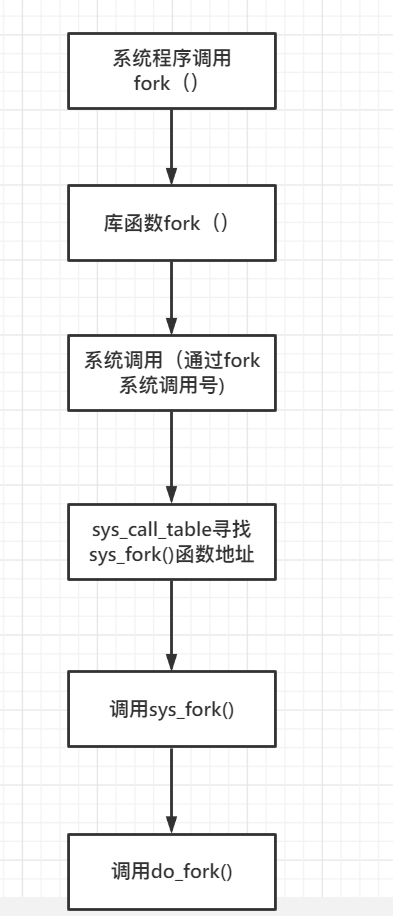
先在syscall_x64.tbl查看fork函数
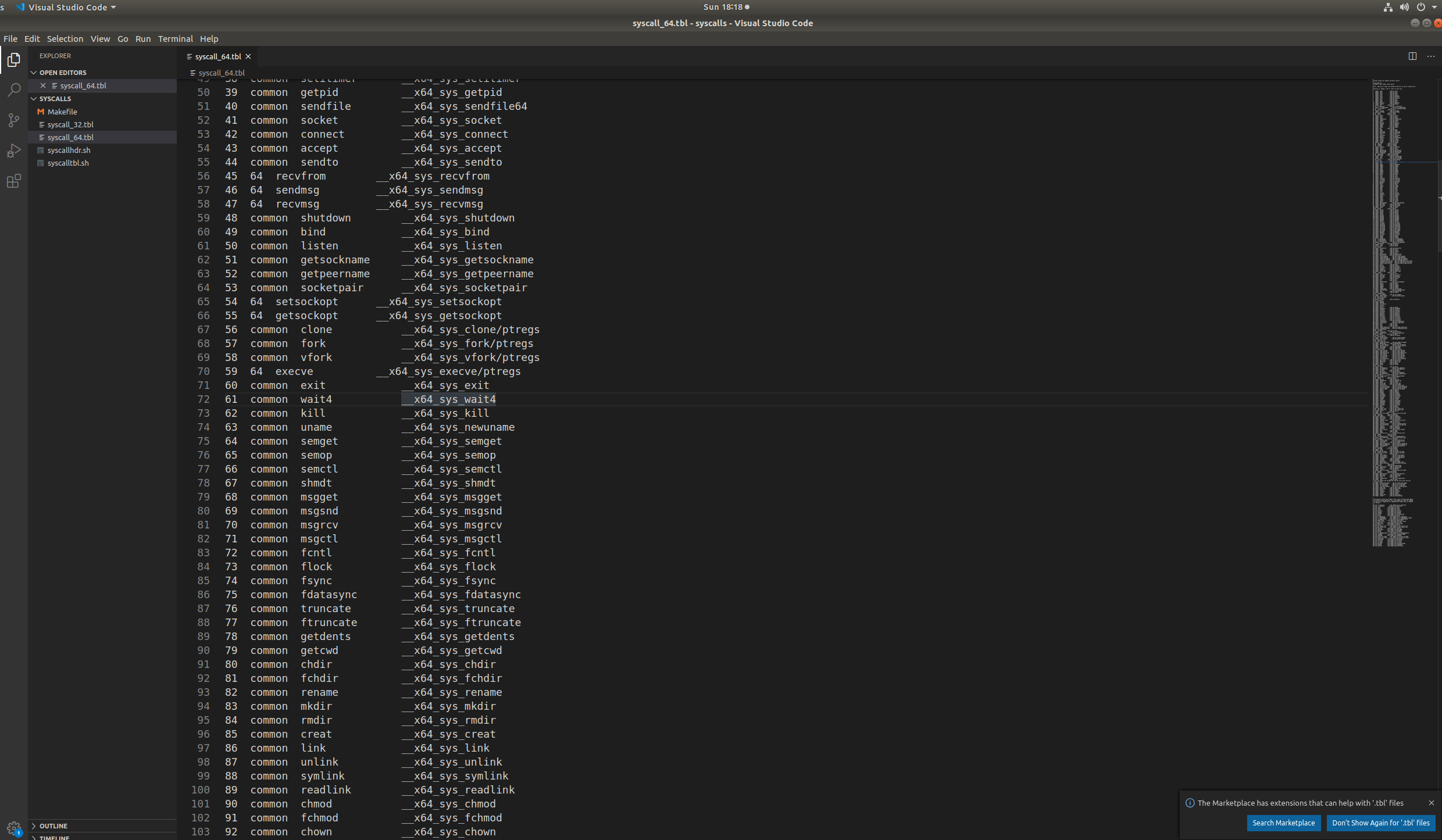
先查看sys_fork()函数
asmlinkage int sys_fork(struct pt_regs regs)
{
return do_fork(SIGCHLD, regs.esp, ®s, 0);
}
其次又发现还有几个函数也调用了do_fork()函数,如下,分别是sys_clone 和sys_vfork
asmlinkage int sys_clone(struct pt_regs regs) { unsigned long clone_flags; unsigned long newsp; clone_flags = regs.ebx; newsp = regs.ecx; //是(0)否(1)使用父进程用户空间堆栈 if(!newsp) newsp = regs.esp; return do_fork(clone_flags, newsp, ®s, 0); } asmlinkage int sys_vfork(struct pt_regs regs) { return do_fork((CLONE_VFORK|CLONE_VM|SIGCHLD), regs.esp, ®s, 0); }
显而易见,三个系统调用的实现都是通过调用do_fork()来完成的,不同的只是对do_fork()的调用参数..
接下来重点分析do_fork函数,函数大概代码如下:
long do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; // ... // 复制进程描述符,返回创建的task_struct的指针 p = copy_process(clone_flags, stack_start, stack_size, child_tidptr, NULL, trace); if (!IS_ERR(p)) { struct completion vfork; struct pid *pid; trace_sched_process_fork(current, p); // 取出task结构体内的pid pid = get_task_pid(p, PIDTYPE_PID); nr = pid_vnr(pid); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); // 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行 if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); get_task_struct(p); } // 将子进程添加到调度器的队列,使得子进程有机会获得CPU wake_up_new_task(p); // ... // 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间 // 保证子进程优先于父进程运行 if (clone_flags & CLONE_VFORK) { if (!wait_for_vfork_done(p, &vfork)) ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); } put_pid(pid); } else { nr = PTR_ERR(p); } return nr; }
do_fork具体分析:
- 在一开始,该函数定义了一个task_struct类型的指针p,用来接收即将为新进程(子进程)所分配的进程描述符。紧接着使用alloc_pidmap函数为这个新进程分配一个pid。由于系统内的pid是循环使用的,所以采用位图方式来管理。简单的说,就是用每一位(bit)来标示该位所对应的pid是否被使用。分配完毕后,判断pid是否分配成功。
- 接下来检查当前进程(父进程)的ptrace字段。ptrace是用来标示一个进程是否被另外一个进程所跟踪。所谓跟踪,最常见的例子就是处于调试状态下的进程被debugger进程所跟踪。父进程的ptrace字段非0时说明debugger程序正在跟踪父进程,那么接下来通过fork_traceflag函数来检测子进程是否也要被跟踪。如果trace为1,那么就将跟踪标志CLONE_PTRACE加入标志变量clone_flags中。通常上述的跟踪情况是很少发生的,因此在判断父进程的ptrace字段时使用了unlikely修饰符。使用该修饰符的判断语句执行结果与普通判断语句相同,只不过在执行效率上有所不同。正如该单词的含义所表示的那样,current->ptrace很少为非0。因此,编译器尽量不会把if内的语句与当前语句之前的代码编译在一起,以增加cache的命中率。与此相反,likely修饰符则表示所修饰的代码很可能发生。
- 接下来检查当前进程(父进程)的ptrace字段。ptrace是用来标示一个进程是否被另外一个进程所跟踪。所谓跟踪,最常见的例子就是处于调试状态下的进程被debugger进程所跟踪。父进程的ptrace字段非0时说明debugger程序正在跟踪父进程,那么接下来通过fork_traceflag函数来检测子进程是否也要被跟踪。如果trace为1,那么就将跟踪标志CLONE_PTRACE加入标志变量clone_flags中。通常上述的跟踪情况是很少发生的,因此在判断父进程的ptrace字段时使用了unlikely修饰符。使用该修饰符的判断语句执行结果与普通判断语句相同,只不过在执行效率上有所不同。正如该单词的含义所表示的那样,current->ptrace很少为非0。因此,编译器尽量不会把if内的语句与当前语句之前的代码编译在一起,以增加cache的命中率。与此相反,likely修饰符则表示所修饰的代码很可能发生。
- 如果copy_process函数执行成功,那么将继续下面的代码。
- 首先定义了一个完成量vfork,如果clone_flags包含CLONE_VFORK标志,那么将进程描述符中的vfork_done字段指向这个完成量,之后再对vfork完成量进行初始化。完成量的作用是,直到任务A发出信号通知任务B发生了某个特定事件时,任务B才会开始执行;否则任务B一直等待。我们知道,如果使用vfork系统调用来创建子进程,那么必然是子进程先执行。究其原因就是此处vfork完成量所起到的作用:当子进程调用exec函数或退出时就向父进程发出信号。此时,父进程才会被唤醒;否则一直等待。此处的代码只是对完成量进行初始化,具体的阻塞语句则在后面的代码中有所体现.
- 如果子进程被跟踪或者设置了CLONE_STOPPED标志,那么通过sigaddset函数为子进程增加挂起信号。signal对应一个unsigned long类型的变量,该变量的每个位分别对应一种信号。具体的操作是,将SIGSTOP信号所对应的那一位置1。
- 如果子进程并未设置CLONE_STOPPED标志,那么通过wake_up_new_task函数使得父子进程之一优先运行;否则,将子进程的状态设置为TASK_STOPPED。
- 如果父进程被跟踪,则将子进程的pid赋值给父进程的进程描述符的pstrace_message字段。再通过ptrace_notify函数使得当前进程定制,并向父进程的父进程发送SIGCHLD信号。
- 如果CLONE_VFORK标志被设置,则通过wait操作将父进程阻塞,直至子进程调用exec函数或者退出。
- 如果copy_process()在执行的时候发生错误,则先释放已分配的pid;再根据PTR_ERR()的返回值得到错误代码,保存于pid中。
- 返回pid。这也就是为什么使用fork系统调用时父进程会返回子进程pid的原因。至于为什么子进程会返回0则在copy_process()中有所体现。以上便是do_fork函数的大致执行过程。
4、execve系统调用
在syscall调用表中可见execve函数就在fork函数下面,为59号系统调用
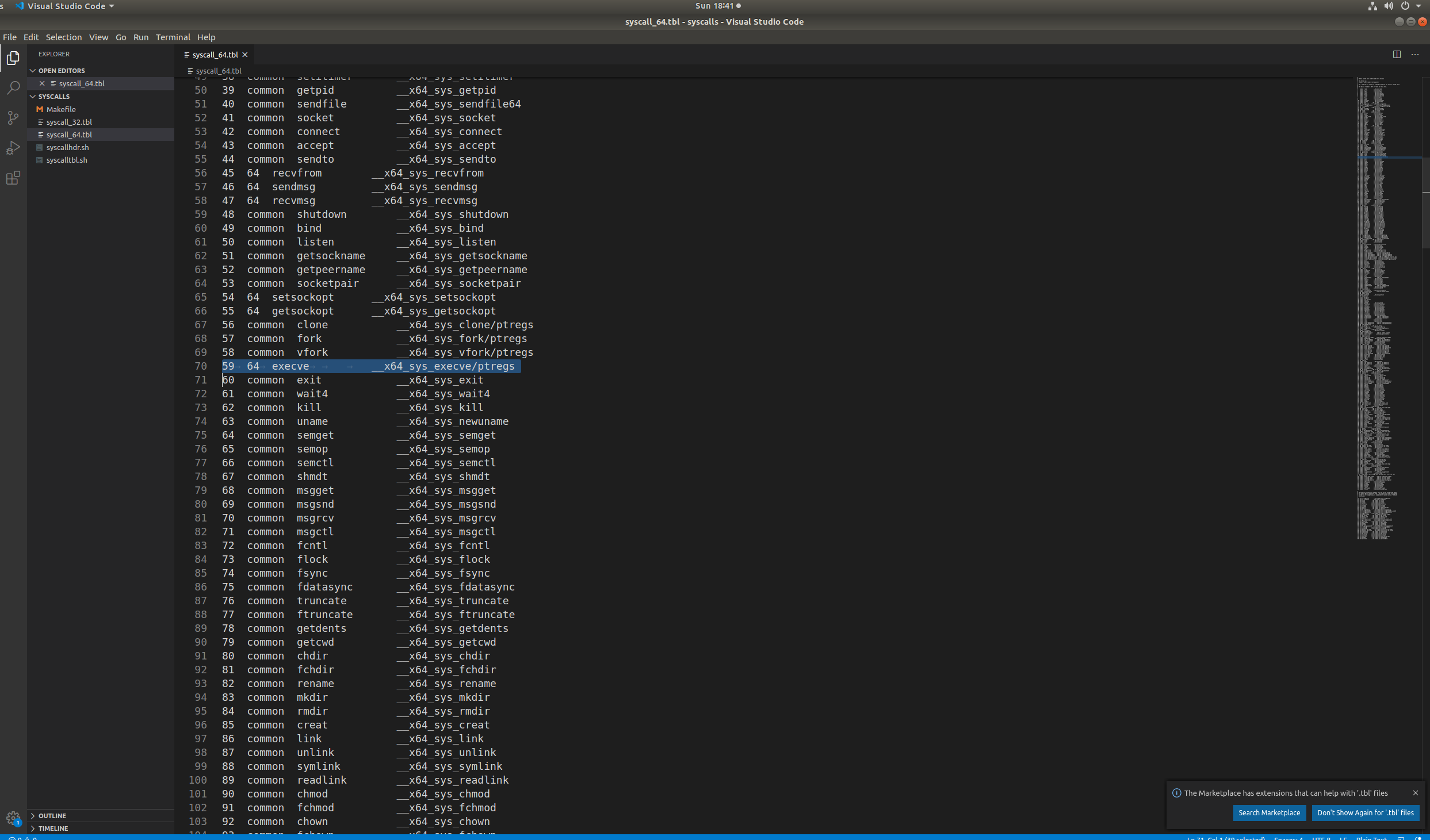
而系统调用execve的内核入口为sys_execve,定义在<arch/kernel/process.c>中:
asmlinkage int sys_execve(struct pt_regs regs) { int error; char * filename; filename = getname((char *) regs.ebx); error = PTR_ERR(filename); if (IS_ERR(filename)) goto out; error = do_execve(filename, (char **) regs.ecx, (char **) regs.edx, ®s); if (error == 0) current->ptrace &= ~PT_DTRACE; putname(filename); out: return error; }
regs.ebx保存着系统调用execve的第一个参数,即可执行文件的路径名。因为路径名存储在用户空间中,这里要通过getname拷贝到内核空间中。getname在拷贝文件名时,先申请了一个page作为缓冲,然后再从用户空间拷贝字符串。为什么要申请一个页面而不使用进程的系统空间堆栈?首先这是一个绝对路径名,可能比较长,其次进程的系统空间堆栈大约为7K,比较紧缺,不宜滥用。用完文件名后,在函数的末尾调用putname释放掉申请的那个页面。
sys_execve的核心是调用do_execve函数,传给do_execve的第一个参数是已经拷贝到内核空间的路径名filename,第二个和第三个参数仍然是系统调用execve的第二个参数argv和第三个参数envp,它们代表的传给可执行文件的参数和环境变量仍然保留在用户空间中。
do_execve主要流程如下:
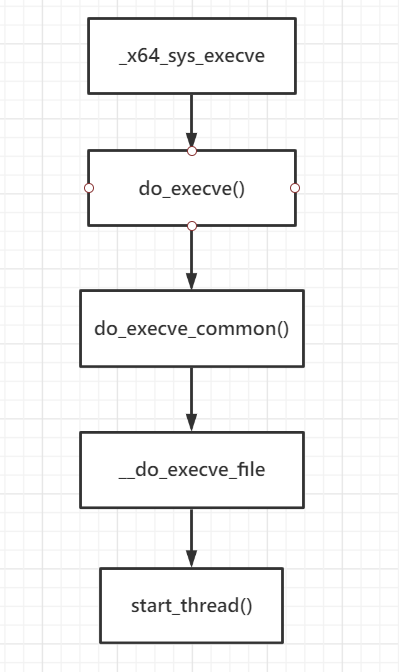
do_execve()和do_execve_common()函数代码如下:
int do_execve(struct filename *filename, const char __user *const __user *__argv, const char __user *const __user *__envp) { return do_execve_common(filename, argv, envp); } //do_execve_common static int do_execve_common(struct filename *filename, struct user_arg_ptr argv, struct user_arg_ptr envp) { // 检查进程的数量限制 // 选择最小负载的CPU,以执行新程序 sched_exec(); // 填充 linux_binprm结构体 retval = prepare_binprm(bprm); // 拷贝文件名、命令行参数、环境变量 retval = copy_strings_kernel(1, &bprm->filename, bprm); retval = copy_strings(bprm->envc, envp, bprm); retval = copy_strings(bprm->argc, argv, bprm); // 调用里面的 search_binary_handler retval = exec_binprm(bprm); // exec执行成功 } // exec_binprm static int exec_binprm(struct linux_binprm *bprm) { // 扫描formats链表,根据不同的文本格式,选择不同的load函数 ret = search_binary_handler(bprm); // ... return ret; }
可见:
- 在
do_exec()中会调用do_execve_common(),这个函数的参数与do_exec()一模一样 - 在
do_execve_common()中的sched_exec(),会选择一个负载最小的CPU来执行新进程 - 在这段代码中间出现了变量
bprm,这个是一个结构体struct linux_binfmt,如下: -
struct linux_binprm { char buf[BINPRM_BUF_SIZE]; #ifdef CONFIG_MMU struct vm_area_struct *vma; unsigned long vma_pages; #else //... unsigned interp_flags; unsigned interp_data; unsigned long loader, exec; };
- 在
do_execve_common()中的search_binary_handler(),这个函数回去搜索和匹配合适的可执行文件装载处理过程 - 装载ELF可执行程序的
load_binary的方法叫做load_elf_binary方法 - 最后调用
start_thread,修改保存在内核堆栈,但属于用户态的eip和esp,该函数代码如下: -
void start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp) { set_user_gs(regs, 0); // 将用户态的寄存器清空 regs->fs = 0; regs->ds = __USER_DS; regs->es = __USER_DS; regs->ss = __USER_DS; regs->cs = __USER_CS; regs->ip = new_ip; // 新进程的运行位置- 动态链接程序的入口处 regs->sp = new_sp; // 用户态的栈顶 regs->flags = X86_EFLAGS_IF; set_thread_flag(TIF_NOTIFY_RESUME); }
可见,exec本质在于替换fork()后,根据制定的可执行文件对进程中的相应部分进行替换,最后根据连接方式的不同来设置好执行起始位置,然后开始执行进程.
而且execve修改了中断上下文,fork修改的是进程上下文。
5、中断上下文和进程上下文:
进程上下⽂切换时需要保存要切换进程的相关信息(如thread.sp与thread.ip),这与中断上下⽂的切换是不同的。
中断是在⼀个进程当中从进程的⽤户态到进程的内核态,或从进程的内核态返回到进程的⽤户态。
切换进程需要在不同的进程间切换。
但⼀般进程上下⽂切换是嵌套到中断上下⽂切换中的,⽐如前述系统调⽤作为⼀种中断先陷⼊内核,即发⽣中断保存现场和系统调⽤处理过程。其中调⽤了schedule函数发⽣进程上下⽂切换,当系统调⽤返回到⽤户态时会恢复现场,⾄此完成了保存现场和恢复现场,即完成了中断上下⽂切换。
中断是由CPU实现的,所以中断上下⽂切换过程中最关键的栈顶寄存器sp和指令指针寄存器ip是由CPU协助完成的;
进程切换是由内核实现的,所以进程上下⽂切换过程中最关键的栈顶寄存器sp切换是通过进程描述符的thread.sp实现的,指令指针寄存器ip的切换是在内核堆栈切换的基础上巧妙利⽤call/ret指令实现的 。
6、Linux系统的⼀般执⾏过程:
(1)正在运⾏的⽤户态进程X。
(2)发⽣中断(包括异常、系统调⽤等), CPU完成load cs:rip(entry of a specific ISR),即跳转到中断处理程序⼊⼝。
(3)中断上下⽂切换,具体包括如下⼏点:
swapgs指令保存现场,可以理解CPU通过swapgs指令给当前CPU寄存器状态做了⼀个快照。
rsp point to kernel stack,加载当前进程内核堆栈栈顶地址到RSP寄存器。快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现⽤户堆栈和内核堆栈的切换。
save cs:rip/ss:rsp/rflags:将当前CPU关键上下⽂压⼊进程X的内核堆栈,快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现的。
此时完成了中断上下⽂切换,即从进程X的⽤户态到进程X的内核态。
(4)中断处理过程中或中断返回前调⽤了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下⽂切换等。
(5) switch_to调⽤了__switch_to_asm汇编代码做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程(本例假定为进程Y)的内核堆
栈,并完成了进程上下⽂所需的指令指针寄存器状态切换。之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以从switch_to下⼀⾏代码继续执⾏)。
(6)中断上下⽂恢复,与(3)中断上下⽂切换相对应。注意这⾥是进程Y的中断处理过程中,⽽(3)中断上下⽂切换是在进程X的中断处理过程中,因为内核堆栈从进程X
切换到进程Y了。
(7)为了对应起⻅中断上下⽂恢复的最后⼀步单独拿出来(6的最后⼀步即是7) iret - pop cs:rip/ss:rsp/rflags,从Y进程的内核堆栈中弹出(3)中对应的压栈内容。此时完
成了中断上下⽂的切换,即从进程Y的内核态返回到进程Y的⽤户态。注意快速系统调⽤返回sysret与iret的处理略有不同。
(8)继续运⾏⽤户态进程Y

 浙公网安备 33010602011771号
浙公网安备 33010602011771号