


Tensorflow 学习三 softmax 练习
以下为简易实现。
import tensorflow as tf import numpy as np import gzip IMAGE_SIZE = 784 TRAIN_SIZE=60000 VALIDATION_SIZE = 5000 TEST_SIZE = 10000 PIXEL_DEPTH = 255 BATCH_SIZE = 64 NUM_CLASSES=10 def extract_data(filename, num_images): with gzip.open(filename) as bytestream: bytestream.read(16) buf = bytestream.read(IMAGE_SIZE * num_images) data = np.frombuffer(buf, dtype=np.uint8).astype(np.float32) data = (data - (PIXEL_DEPTH / 2.0)) / PIXEL_DEPTH data = data.reshape(num_images, IMAGE_SIZE) return data def extract_labels(filename, num_images): with gzip.open(filename) as bytestream: bytestream.read(8) buf = bytestream.read(1 * num_images) labels = np.frombuffer(buf, dtype=np.uint8).astype(np.int64) index_offset = np.arange(num_images) * NUM_CLASSES labels_one_hot = np.zeros((num_images, NUM_CLASSES)) labels_one_hot.flat[index_offset + labels] = 1 return labels_one_hot train_data_filename = 'data//'+'train-images-idx3-ubyte.gz' train_labels_filename = 'data//'+'train-labels-idx1-ubyte.gz' test_data_filename = 'data//'+'t10k-images-idx3-ubyte.gz' test_labels_filename = 'data//'+'t10k-labels-idx1-ubyte.gz' train_data = extract_data(train_data_filename, TRAIN_SIZE) train_labels = extract_labels(train_labels_filename, TRAIN_SIZE) test_data = extract_data(test_data_filename, TEST_SIZE) test_labels = extract_labels(test_labels_filename, TEST_SIZE) train_data = train_data[VALIDATION_SIZE:, ...] train_labels = train_labels[VALIDATION_SIZE:] index=range(TRAIN_SIZE-VALIDATION_SIZE) np.random.shuffle(index) train_data=train_data[index] train_labels=train_labels[index] x = tf.placeholder("float", [None, IMAGE_SIZE]) W = tf.Variable(tf.zeros([IMAGE_SIZE,NUM_CLASSES])) b = tf.Variable(tf.zeros([NUM_CLASSES])) y = tf.nn.softmax(tf.matmul(x,W) + b) y_ = tf.placeholder("float", [None,NUM_CLASSES]) cross_entropy = -tf.reduce_sum(y_*tf.log(y)) train_step = tf.train.GradientDescentOptimizer(0.005).minimize(cross_entropy) init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) for i in range(1000): begin = (i*BATCH_SIZE)%(TRAIN_SIZE-BATCH_SIZE) end = begin+ BATCH_SIZE sess.run(train_step, feed_dict={x: train_data[begin:end], y_: train_labels[begin:end]}) correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print(sess.run(accuracy, feed_dict={x: test_data, y_: test_labels})) # 0.9131 sess.close()
添加了可视化后。
import tensorflow as tf import numpy as np import gzip IMAGE_SIZE = 784 TRAIN_SIZE=60000 VALIDATION_SIZE = 5000 TEST_SIZE = 10000 PIXEL_DEPTH = 255 BATCH_SIZE = 64 NUM_CLASSES=10 def extract_data(filename, num_images): with gzip.open(filename) as bytestream: bytestream.read(16) buf = bytestream.read(IMAGE_SIZE * num_images) data = np.frombuffer(buf, dtype=np.uint8).astype(np.float32) data = (data - (PIXEL_DEPTH / 2.0)) / PIXEL_DEPTH data = data.reshape(num_images, IMAGE_SIZE) return data def extract_labels(filename, num_images): with gzip.open(filename) as bytestream: bytestream.read(8) buf = bytestream.read(1 * num_images) labels = np.frombuffer(buf, dtype=np.uint8).astype(np.int64) index_offset = np.arange(num_images) * NUM_CLASSES labels_one_hot = np.zeros((num_images, NUM_CLASSES)) labels_one_hot.flat[index_offset + labels] = 1 return labels_one_hot train_data_filename = 'data//'+'train-images-idx3-ubyte.gz' train_labels_filename = 'data//'+'train-labels-idx1-ubyte.gz' test_data_filename = 'data//'+'t10k-images-idx3-ubyte.gz' test_labels_filename = 'data//'+'t10k-labels-idx1-ubyte.gz' train_data = extract_data(train_data_filename, TRAIN_SIZE) train_labels = extract_labels(train_labels_filename, TRAIN_SIZE) test_data = extract_data(test_data_filename, TEST_SIZE) test_labels = extract_labels(test_labels_filename, TEST_SIZE) train_data = train_data[VALIDATION_SIZE:, ...] train_labels = train_labels[VALIDATION_SIZE:] index=range(TRAIN_SIZE-VALIDATION_SIZE) np.random.shuffle(index) train_data=train_data[index] train_labels=train_labels[index] x = tf.placeholder("float", [None, IMAGE_SIZE]) W = tf.Variable(tf.zeros([IMAGE_SIZE,NUM_CLASSES])) b = tf.Variable(tf.zeros([NUM_CLASSES])) y = tf.nn.softmax(tf.matmul(x,W) + b) y_ = tf.placeholder("float", [None,NUM_CLASSES]) cross_entropy = -tf.reduce_sum(y_*tf.log(y)) train_step = tf.train.GradientDescentOptimizer(0.005).minimize(cross_entropy) with tf.name_scope('input_reshape'): image_shaped_input = tf.reshape(x, [-1, 28, 28, 1]) tf.summary.image('input', image_shaped_input, 10) with tf.name_scope('cross_entropy'): tf.summary.scalar('cross entropy', cross_entropy) with tf.name_scope('accuracy'): correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) tf.summary.scalar('accuracy', accuracy) with tf.name_scope('w'): mean = tf.reduce_mean(W) tf.summary.scalar('mean', mean) stddev = tf.sqrt(tf.reduce_mean(tf.square(W - mean))) tf.summary.scalar('stddev', stddev) tf.summary.scalar('max', tf.reduce_max(W)) tf.summary.scalar('min', tf.reduce_min(W)) tf.summary.histogram('histogram', W) with tf.name_scope('b'): mean = tf.reduce_mean(b) tf.summary.scalar('mean', mean) stddev = tf.sqrt(tf.reduce_mean(tf.square(b - mean))) tf.summary.scalar('stddev', stddev) tf.summary.scalar('max', tf.reduce_max(b)) tf.summary.scalar('min', tf.reduce_min(b)) tf.summary.histogram('histogram', b) merged = tf.summary.merge_all() init = tf.global_variables_initializer() sess = tf.Session() summary_writer = tf.summary.FileWriter('los', sess.graph) sess.run(init) for i in range(1000): begin = (i*BATCH_SIZE)%(TRAIN_SIZE-BATCH_SIZE) end = begin+ BATCH_SIZE sm,s_=sess.run([merged,train_step], feed_dict={x: train_data[begin:end], y_: train_labels[begin:end]}) summary_writer.add_summary(sm,i) correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print(sess.run(accuracy, feed_dict={x: test_data, y_: test_labels})) # 0.9131

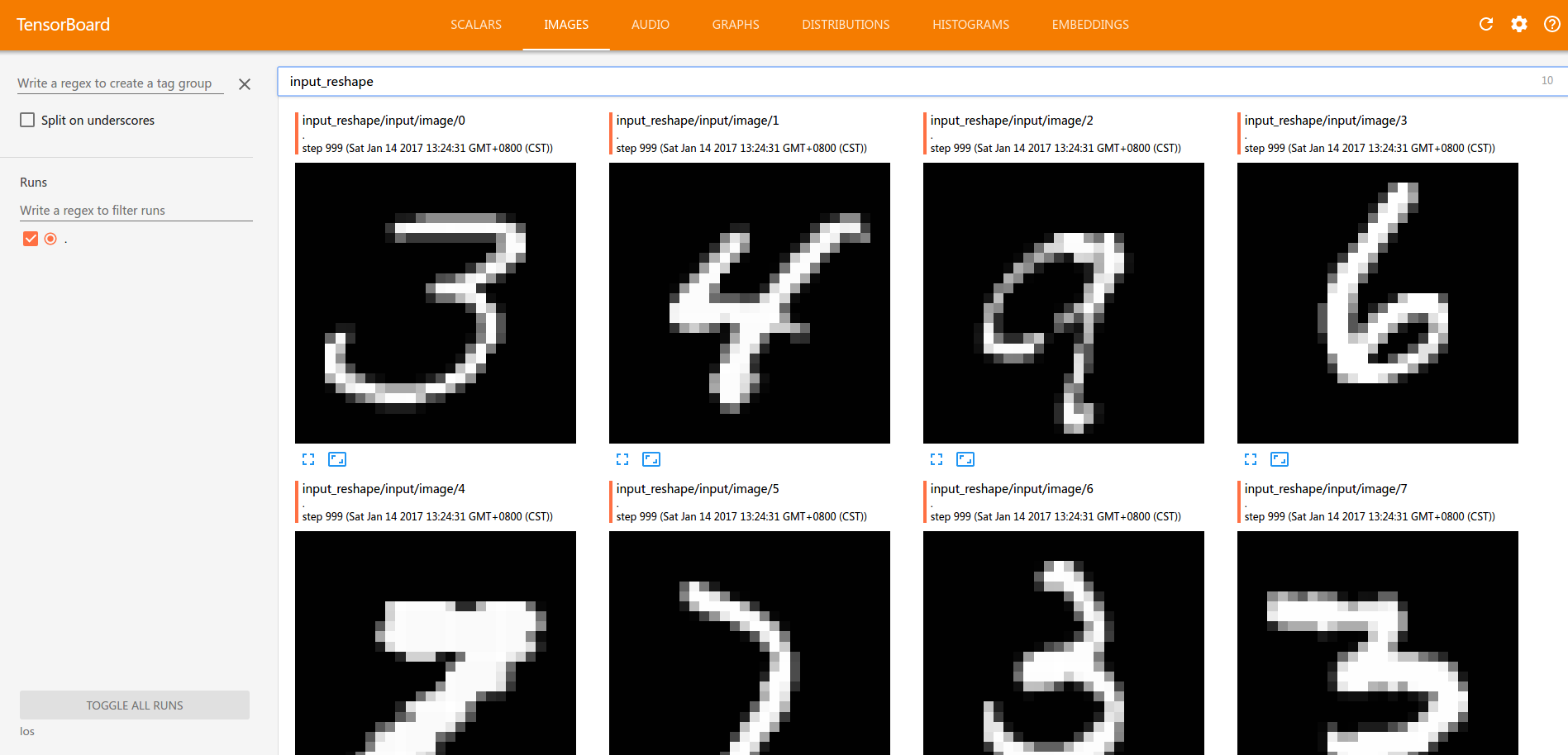
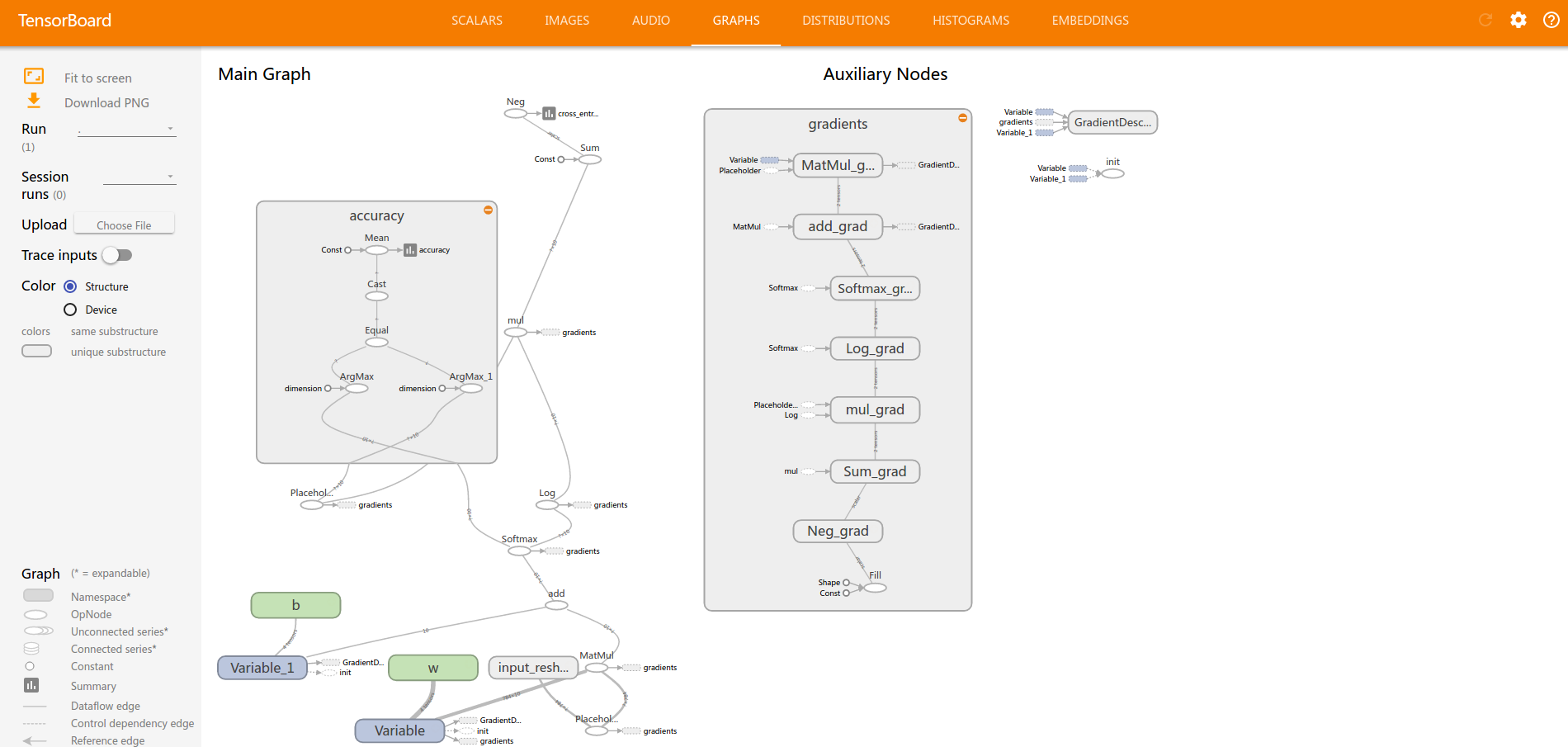
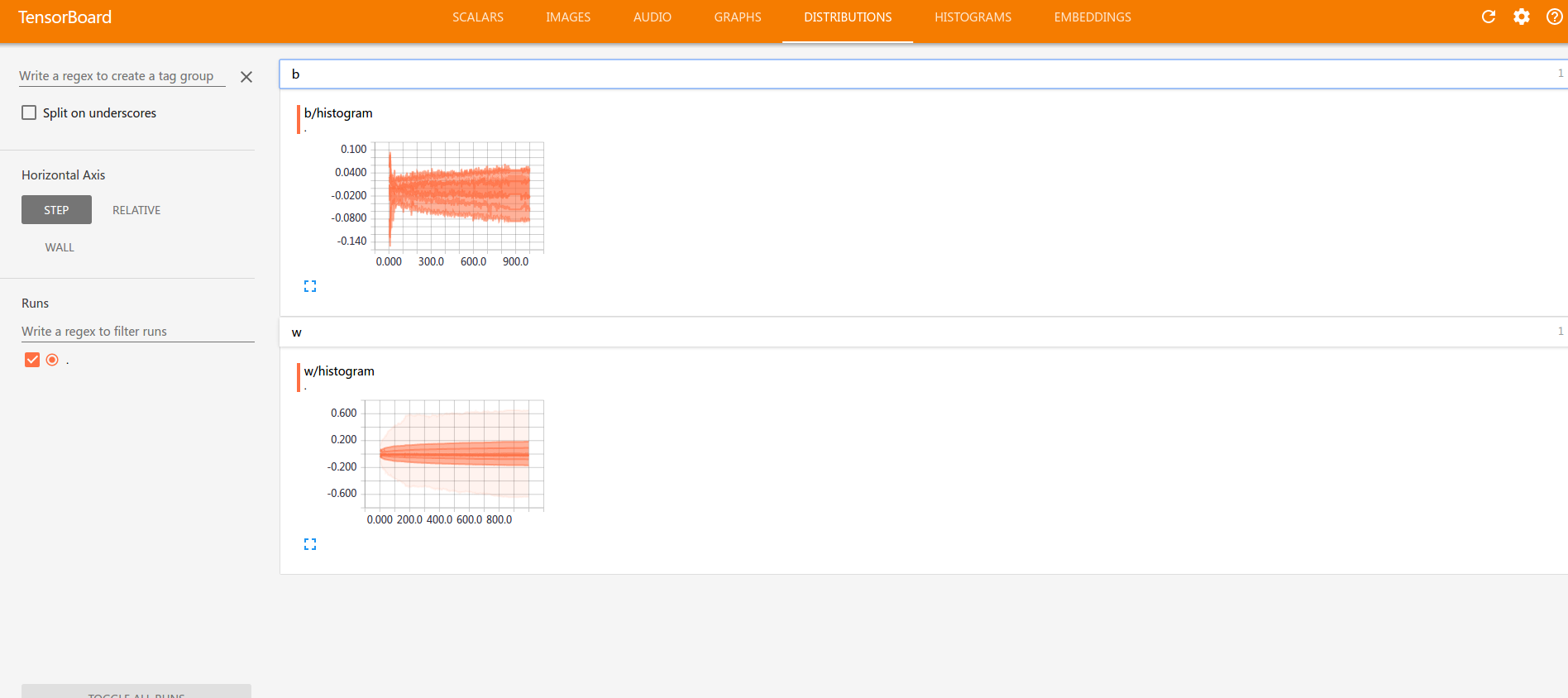

tf.reduce_sum和np.sum类似。
def reduce_sum(input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None): """Computes the sum of elements across dimensions of a tensor. Reduces `input_tensor` along the dimensions given in `axis`. Unless `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in `axis`. If `keep_dims` is true, the reduced dimensions are retained with length 1. If `axis` has no entries, all dimensions are reduced, and a tensor with a single element is returned. For example: ```python # 'x' is [[1, 1, 1] # [1, 1, 1]] tf.reduce_sum(x) ==> 6 tf.reduce_sum(x, 0) ==> [2, 2, 2] tf.reduce_sum(x, 1) ==> [3, 3] tf.reduce_sum(x, 1, keep_dims=True) ==> [[3], [3]] tf.reduce_sum(x, [0, 1]) ==> 6 ``` Args: input_tensor: The tensor to reduce. Should have numeric type. axis: The dimensions to reduce. If `None` (the default), reduces all dimensions. keep_dims: If true, retains reduced dimensions with length 1. name: A name for the operation (optional). reduction_indices: The old (deprecated) name for axis. Returns: The reduced tensor. @compatibility(numpy) Equivalent to np.sum @end_compatibility """
def sum(a, axis=None, dtype=None, out=None, keepdims=False): """ Sum of array elements over a given axis. Parameters ---------- a : array_like Elements to sum. axis : None or int or tuple of ints, optional Axis or axes along which a sum is performed. The default, axis=None, will sum all of the elements of the input array. If axis is negative it counts from the last to the first axis. .. versionadded:: 1.7.0 If axis is a tuple of ints, a sum is performed on all of the axes specified in the tuple instead of a single axis or all the axes as before. dtype : dtype, optional The type of the returned array and of the accumulator in which the elements are summed. The dtype of `a` is used by default unless `a` has an integer dtype of less precision than the default platform integer. In that case, if `a` is signed then the platform integer is used while if `a` is unsigned then an unsigned integer of the same precision as the platform integer is used. out : ndarray, optional Alternative output array in which to place the result. It must have the same shape as the expected output, but the type of the output values will be cast if necessary. keepdims : bool, optional If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array. Returns ------- sum_along_axis : ndarray An array with the same shape as `a`, with the specified axis removed. If `a` is a 0-d array, or if `axis` is None, a scalar is returned. If an output array is specified, a reference to `out` is returned. See Also -------- ndarray.sum : Equivalent method. cumsum : Cumulative sum of array elements. trapz : Integration of array values using the composite trapezoidal rule. mean, average Notes ----- Arithmetic is modular when using integer types, and no error is raised on overflow. The sum of an empty array is the neutral element 0: >>> np.sum([]) 0.0 Examples -------- >>> np.sum([0.5, 1.5]) 2.0 >>> np.sum([0.5, 0.7, 0.2, 1.5], dtype=np.int32) 1 >>> np.sum([[0, 1], [0, 5]]) 6 >>> np.sum([[0, 1], [0, 5]], axis=0) array([0, 6]) >>> np.sum([[0, 1], [0, 5]], axis=1) array([1, 5]) If the accumulator is too small, overflow occurs: >>> np.ones(128, dtype=np.int8).sum(dtype=np.int8) -128 """


 浙公网安备 33010602011771号
浙公网安备 33010602011771号