语言模型和共现矩阵(转)
本文转自: https://blog.csdn.net/hao5335156/article/details/80452793
1、语言模型
目的:克服one-hot、tf-idf方法中向量丢失句子中单词的位置关系信息
1)2-gram
假设语料库如下:
John likes to watch movies. Mary likes too.John also likes to watch football games.
2-gram建立索引如下:(把每个句子中相邻的2个单词用一个编码表示,不再是以前的一个单词一个编码)
“John likes” : 1,
“likes to” : 2,
“to watch” : 3,
“watch movies” : 4,
“Mary likes” : 5,
“likes too” : 6,
“John also” : 7,
“also likes” : 8,
“watch football”: 9,
“football games”: 10,
得到10个编码,所以构建的词向量长度为10;对于句子”John likes to watch movies. Mary likes too.”的编码如下:(依次判断1-10个编码,第一个编码”John likes” : 1在句子中出现则为1,否则为0)
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
2)N-gram
同2-gram,每个句子中相邻的N个单词用一个编码表示,不再是以前的一个单词一个编码
3)优缺点
优点: 考虑了词的顺序
缺点: 词表的膨胀
语言模型
一句话 (词组合) 出现的概率
Unigram/1-gram
Bi-gram/2-gram
不足:无法衡量词向量之间的关系,同时向量太稀疏
2、共现矩阵
主要用于发现主题,解决词向量相近关系的表示;
将共现矩阵行(列)作为词向量
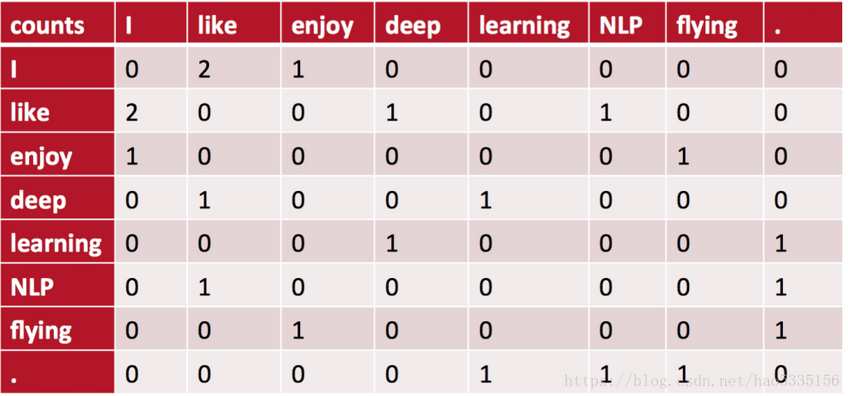
例如:语料库如下:
• I like deep learning.
• I like NLP.
• I enjoy flying.
则共现矩阵表示如下:(使用对称的窗函数(左右window length都为1) )
例如:“I like”出现在第1,2句话中,一共出现2次,所以=2。
对称的窗口指的是,“like I”也是2次
将共现矩阵行(列)作为词向量表示后,可以知道like,enjoy都是在I附近且统计数目大约相等,他们意思相近
共现矩阵不足:
面临稀疏性问题、向量维数随着词典大小线性增长
解决:SVD、PCA降维,但是计算量大
3、word2vec
前面方法需要存储的数据过大,这里主要是保存参数来节省,需要时候再通过计算参数得出结果。原理是通过浅层的神经网络训练(input是onehot词向量,output是预测的词向量,比如“我喜欢自学习”,input=“我”和“学习”,out=“喜欢”,input=(0001000)的话,输出时候1的位置是概率,P“喜欢”=1,语料库中的其他词则是P=0)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号