

gitlab 频繁 502 问题排查
最近部署了公司内部的gitlab代码仓库(docker方式)。
部署后发现gitlab页面经常显示502错误。然后重新刷新页面大概率就又可以正常显示了。
这严重影响使用。所以对此问题进行了排查。
首先应该知道的是gitlab是有多个内部组件组成的复杂系统。其内部是使用的Puma作为web页面部分的服务器
进入docker镜像,执行:gitlab-ctl status 可以查询gitlab各个组件的状态
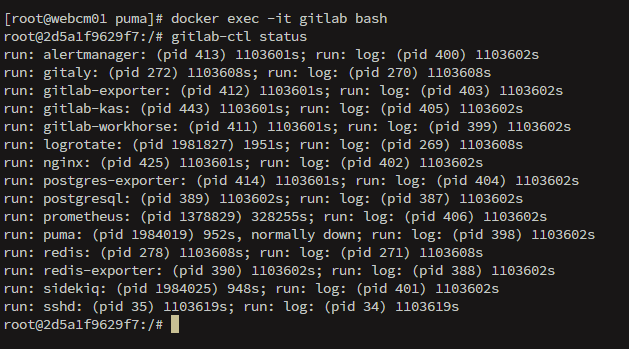
📚 GitLab 各组件功能一览表
| 组件 | 作用说明 | 是否处理 Web 页面 | 是否处理 Git 操作 | 常见问题 | 备注 |
|---|---|---|---|---|---|
| Nginx | 反向代理服务器,接收所有外部请求(HTTP/HTTPS),并路由到后端服务(Puma、Gitaly、Registry 等)。也提供静态文件服务。 | ✅ 是(入口) | ✅ 是(代理 Git over HTTP) | 502/504 错误、连接超时、SSL 配置错误 | 所有请求的“门卫” |
| Puma | GitLab 的 Web 应用服务器,处理所有 Web 页面、API 请求(如登录、项目列表、CI/CD 页面、Merge Request 等)。 | ✅ 是(核心) | ❌ 否 | 502 错误、Worker 重启、内存过高 | 不处理 Git 操作 |
| Gitaly | Git 存储服务,负责所有 Git 操作:git clone、push、pull、fetch、查看文件历史等。所有 Git 请求最终由它执行。 |
❌ 否 | ✅ 是(核心) | 性能慢、连接失败、磁盘 I/O 高 | Git 操作的“引擎” |
| GitLab Shell | 处理 SSH 协议 的 Git 请求(如 git@gitlab:group/project.git),验证用户权限,并将请求转发给 Gitaly。 |
❌ 否 | ✅ 是(SSH 路径) | SSH 登录失败、权限拒绝 | 仅用于 SSH Git |
| PostgreSQL | GitLab 的主数据库,存储用户、项目、权限、Issue、Merge Request、CI/CD 配置等元数据(非代码本身)。 | ✅ 是(依赖) | ✅ 是(依赖) | 连接数满、慢查询、磁盘满 | 所有服务都依赖它 |
| Redis | 缓存和消息队列服务,用于会话存储、Sidekiq 任务队列、实时通知等。 | ✅ 是(加速) | ✅ 是(加速) | 内存耗尽、连接超时 | 提升性能的关键 |
| Sidekiq | 后台任务处理器,执行异步任务:发送邮件、CI/CD 流水线、仓库扫描、Webhooks 等。 | ✅ 是(后台) | ✅ 是(后台) | 队列积压、任务超时 | CI/CD 的“幕后工作者” |
| Prometheus | 内置监控系统,收集各组件的性能指标(CPU、内存、请求延迟等)。 | ✅ 是(监控) | ❌ 否 | 监控数据丢失 | 用于性能分析 |
| Alertmanager | 告警管理,与 Prometheus 配合,发送告警通知(邮件、Slack 等)。 | ✅ 是(告警) | ❌ 否 | 告警未触发 | 运维告警系统 |
| Logrotate | 日志轮转工具,自动压缩和清理旧日志文件。 | ❌ 否 | ❌ 否 | 日志文件过大 | 防止磁盘被日志占满 |
| Registry | Docker 镜像仓库服务,用于存储和管理容器镜像(GitLab Container Registry)。 | ✅ 是(镜像页面) | ❌ 否(但提供镜像存储) | 镜像 push/pull 失败 | 可选组件 |
| Pages | GitLab Pages 服务,用于托管静态网站(如文档、博客)。 | ✅ 是(Pages 页面) | ❌ 否 | 页面无法访问 | 可选组件 |
| GitLab Exporter | Prometheus 的指标导出器,暴露 GitLab 内部监控数据。 | ✅ 是(监控) | ❌ 否 | 指标采集失败 | 监控辅助组件 |
根据上数功能表,首先考虑应该是puma的问题。
然后我去查看了puma的日志:
容器内执行:gitlab-ctl tail puma/puma_stdout.log
看到了如下内容:
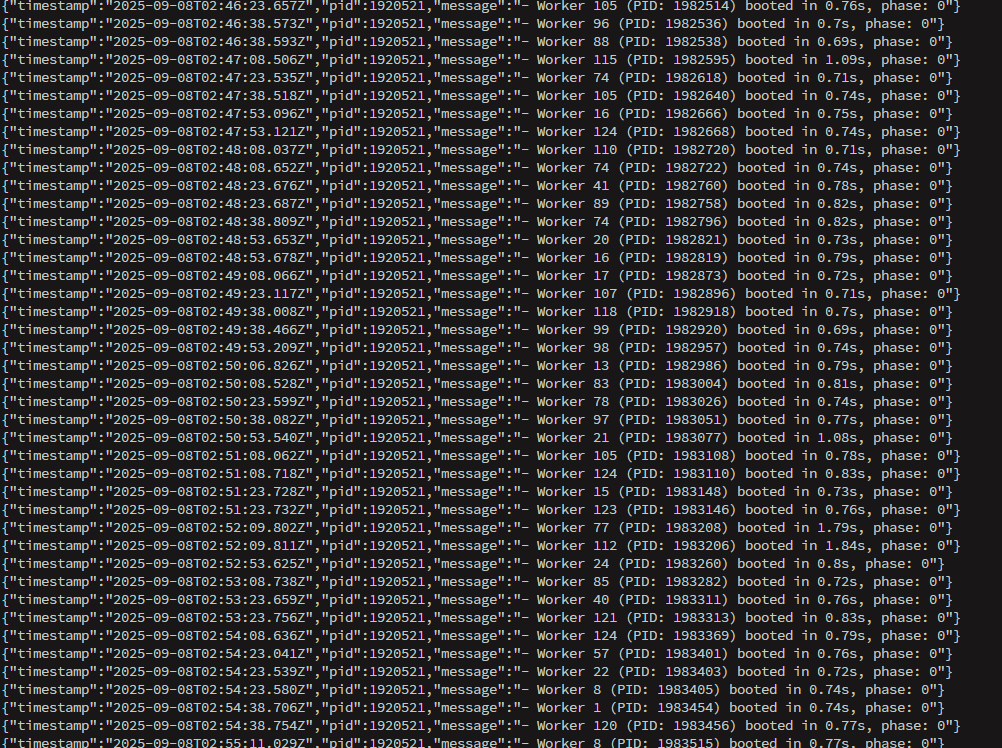
这里就能看出问题了。puma的工作线程在频繁的重启。这样基本上就可以确定了。是线程频繁重启导致时断时续的出现502错误。
然后去看一下gitlab的配置文件里puma相关的部分:
容器内执行:vi /etc/gitlab/gitlab.rb
找到如下配置项目:
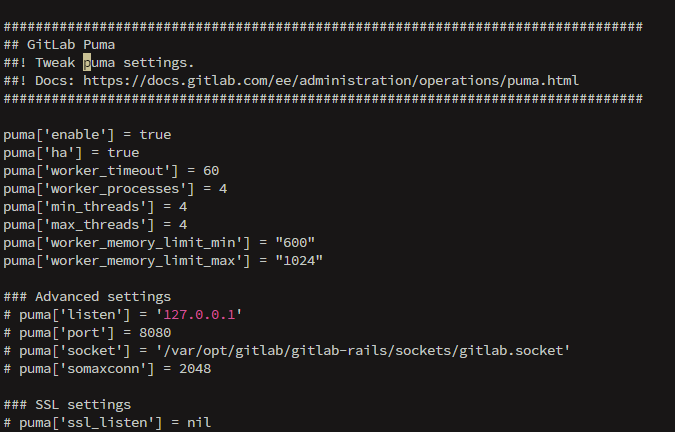
这是我配置完毕以后得内容。
配置项说明如下:
📊 GitLab Puma 配置项详解
| 配置项 | 说明 | 默认值 | 建议值 | 影响与注意事项 |
|---|---|---|---|---|
puma['enable'] = true |
是否启用 Puma 服务。设为 false 时,Puma 不启动(仅用于高可用集群中由外部负载均衡调度的场景)。 |
true |
true |
⚠️ 一般不要关闭,否则 Web 页面和 API 无法访问。 |
puma['ha'] = true |
启用 Puma 高可用(High Availability)模式。开启后,主进程会监控 worker 健康状态,自动重启无响应或内存超限的 worker。 | true |
true ✅ |
推荐保持开启,可防止 worker 卡死。但若频繁重启 worker,会导致 502。 |
puma['worker_timeout'] = 60 |
每个 worker 最大无响应时间(秒)。如果 worker 在此时间内未处理请求,将被主进程杀死并重启。 | 60 |
60 ~ 90 |
过短可能导致正常长请求被误杀;过长则卡死 worker 恢复慢。 |
puma['worker_processes'] = 4 |
Puma 启动的 worker 进程数。每个 worker 是独立的 Ruby 进程,可处理并发请求。 | CPU 核心数(通常 2~4) | 2 ~ CPU 核心数 |
- 每个 worker 内存约 300~800MB<br>- 内存不足时应减少此值<br>- 通常设为 CPU 核心数 |
puma['min_threads'] = 4 |
每个 worker 的最小线程数。Puma 使用多线程处理请求,此值决定空闲时的线程数量。 | 0 或 1(版本不同) |
4 |
线程用于处理并发请求,设为 4 表示每个 worker 至少有 4 个线程处理请求。 |
puma['max_threads'] = 4 |
每个 worker 的最大线程数。当请求增多时,Puma 会在此范围内动态增加线程。 | 16 或 4 |
4 ~ 16 |
若 min == max,则线程数固定,适合稳定负载。 |
puma['worker_memory_limit_min'] = "600" |
worker 内存使用低于此值时,不触发内存检查(单位:MB)。用于避免频繁检查小内存进程。 | 300 |
600 |
配合 max 使用,避免误杀刚启动的 worker。 |
puma['worker_memory_limit_max'] = "1024" |
当 worker 内存使用超过此值时,会被主进程杀死并重启,防止内存泄漏。 | 600 |
800 ~ 1024(根据内存调整) |
🔑 关键配置:过低会导致频繁重启(502);过高可能导致 OOM。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号