Hive入门学习随笔(一)
===什么是Hive?
Hive是基于Hadoop HDFS之上的数据仓库。
我们可以把数据存储在这个基于数据的仓库之中,进行分析和处理,完成我们的业务逻辑。
本质上就是一个数据库
===什么是数据仓库?
实际上就是一个数据库。我们可以利用数据仓库来保存我们的数据。
与一般意义上的数据库不同。数据库是一个面向主题的、集成的、不可更新的、随时间不变化的数据集合,它用于支持企业和组织的决策分析处理。
1)面向主题的:
数据仓库中的数据是按照一定的主题来组织的。*主题:指的是用户使用数据仓库进行决策时所关心的重点方面。
2)集成的:
数据仓库中的数据来自于分散的操作性的数据,我们把分散性的数据的操作性的数据从原来的数据中抽取出来进行加工和处理,然后满足一定的要求才可以进入我们的数据仓库。
原来的数据,可能来源于我们的Oracle、MySQL等关系型数据库,文本文件,或者其他的系统。将不同的数据集成起来就形成了数据仓库。
3)不可更新的
也就是说数据仓库主要是为了决策分析所提供数据,所以涉及的操作主要是数据的查询。我们一般都不会再数据仓库中进行更新和删除。
4)随时间不变化
数据仓库中的数据是不会随时间产生变化的集合。
===数据仓库的结构和建立过程
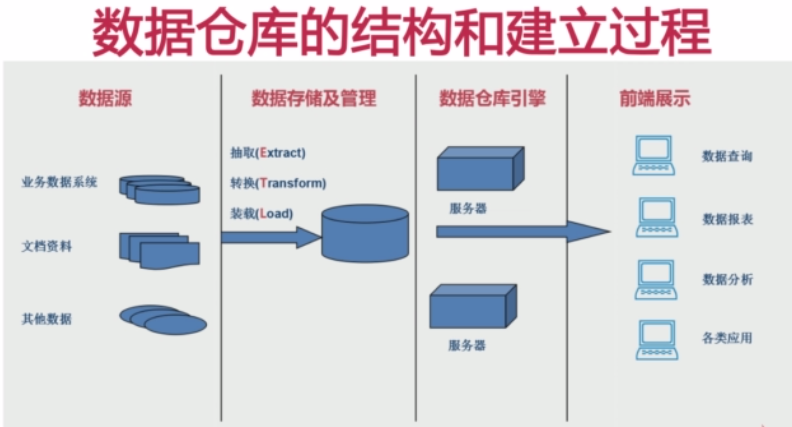
1)数据源:
有可能来自由业务数据系统(关系型数据库),文档资料(csv,txt等),其他数据
2)数据存储和管理:
俗称的ETL的过程。
•抽取(Extract):把数据源的数据按照一定的方式读取出来
•转换(Transform):不同数据源的数据它的格式是不一样的,不一定满足我们的要求,所以需要按照一定的规则进行转换。
•装在(Load):将满足格式的数据存取到数据仓库之中。
3)数据仓库引擎:
建立了数据仓库以后,当然是提供对外的数据服务,所以产生了数据仓库引擎。
在数据仓库引擎之中包含有不同的服务器,不同的服务器提供不同的服务。
4)前端展示:
前端展示的数据均来自数据仓库引擎中的各个服务。而服务又读物数据仓库中的数据。
•数据查询
•数据报表
•数据分析
•各类应用
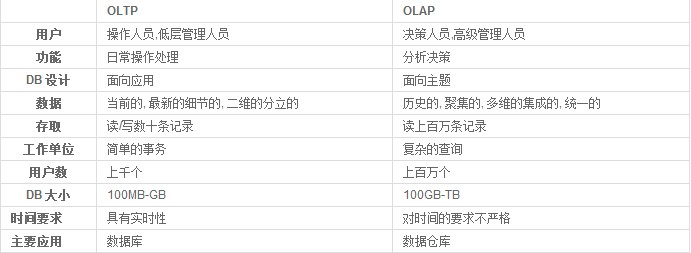
===OLTP应用与OLAP应用
数据处理大致可以分成两大类
联机事务处理OLTP(on-line transaction processing):主要面向事务。
联机分析处理OLAP(on-line analytical processing):主要面向查询。
OLTP是传统的关系型数据库的主要应用。主要是基本的、气场的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作。
OLAP系统泽强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
===数据仓库中的数据模型
1)星型模型
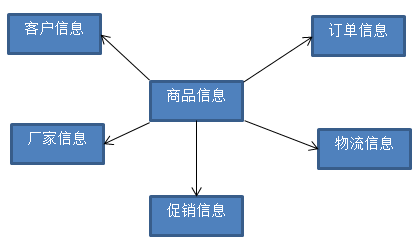
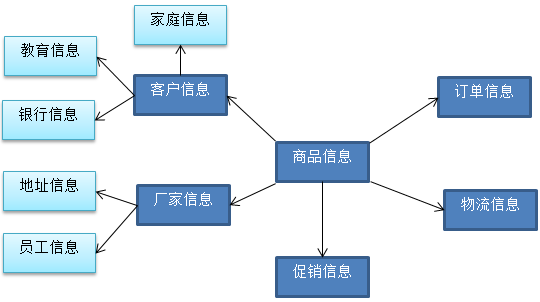
2)雪花模型
星型模型尽管反映了一定的数据仓库的某种信息,但是在某些情况下可能满足不了我们的要求。基于星型模型发展出了雪花模型。
比如从上述的星型模型中,我们可以以客户信息为主题,关联出其他信息。
这样这个模型就回越发展越大,发展成为了雪花模型。
===什么是Hive?
它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据仓库还有区别。
一般来说,我们也可以基于传统方式(Oracle或者MySQL数据库)来搭建这个数据仓库,这个时候数据仓库中的数据是保存在Oracle或者MySQL的数据库当中的。
Hive跟传统方式是不一样的,Hive是建立在Hadoop HDFS基础之上的数据仓库基础框架。也就是说
--Hive这个数据仓库中的数据是保存在HDFS上。
--Hive可以用ETL的方式来进行数据提取转化加载。
--Hive定义了简单的类似SQL查询语言,称为HQL。
--Hive允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理內建的mapper和reducer无法完成的复杂的分析工作。
--Hive是SQL解析引擎,它将SQL语句转移成M/R Job,然后在Hadoop上执行。把执行的结果最终反映给用户。
--Hive的表其实就是HDFS的目录,Hive的数据其实就是HDFS的文件
===Hive的体系结构之元数据
Hive将元数据(meta data)存储在数据库中(meta store),支持mysql,oracle,derby(默认)等数据库。
Hive中的元数据包括表的名字,表的列和分区以及属性,表的属性(是否为外部表等),表的数据所在目录等。

===Hive的体系结构之HQL的执行过程
一条HQL语句如何在Hive的数据仓库当中中进行查询的?
由解释器、编译器、优化器来共同完成HQL查询语句从词法解析、语法解析、编译、优化以及查询计划(Plan)的生成。
生成的查询计划存储在HDFS中,并在随后又MapReduce调用执行。

*执行计划:类似于我们的javac命令。
===Hive的体系结构
--Hadoop:用HDFS进行存储,利用MapReduce进行计算。
--元数据存储(MetaStore):通常是存储在关系数据库中。
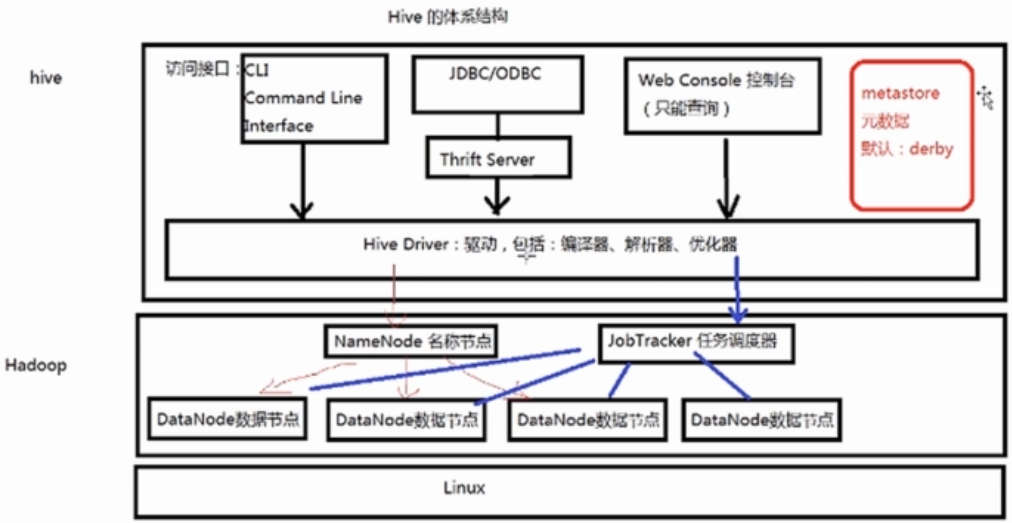
*CUI:与Oracle中的sqlplus类似。
*ThriftServer:可以使用不同(JDBC/ODBC)的语言连接到Thrift Server上进行访问。
*Web控制台:可以经过Web工具来查询数据。这个控制台只能进行查询。
而且在Hive的0.13版本当中并没集成在Hive的安装包里面,需要下载Hive的源代码进行编译打包,将打包后的Web控制台部署到Hive的安装目录下。
===Hive的安装
下载最新Hive安装文件的网址:http://hive.apache.org/
下载过去版本Hive安装文件的网址:http://archive.apache.org/
由于Hive是基于Hadoop的,所以在安装Hive之前,需要先安装Hadoop。可以安装单机、伪分布、集群环境的Hadoop。
Hive的安装有三种模式:嵌入模式、本地模式、远程模式
1)嵌入模式:
--元数据信息被存储在Hive自带的Derby数据库中。
--只允许创建一个连接
--多用于Demo(演示)
2)本地模式:
--元信息被存储在MySQL数据库中。
--MySQL数据库与Hive运行在同一台物理机器上。
--多用于开发和测试
3)远程模式:
--元信息被存储在MySQL数据库中。
--MySQL数据库与Hive运行不在同一台物理机器上。
--多用于实际的生产运行环境。
===Hive安装之嵌入模式
需要将安装文件上传到Linux操作系统之上。
使用tar -zxvf xxxx.tar.gz解压缩文件。
执行hive命令,会自动创建Derby数据库来保存我们的元信息。执行之后将进入命令行窗口。
执行之后会在bin目录下增加一个metastore_db目录,这就是Derby数据库,用它来保存我们的元信息。
也就是说不需要进行任何的配置就可以进入到嵌入式的模式当中。
当然,最好是将我们的Hive路径配置到配置文件当中,这样就可以在任何地方执行我们的Hive命令。
配置文件路径vi ~/.bash_profile,然后使用source ~/.bash_profile命令来使更改生效。
===Hive安装之远程模式
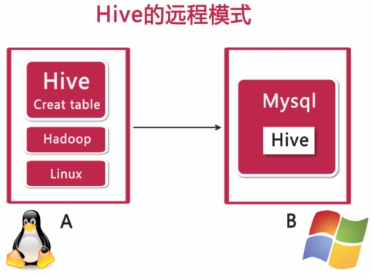
1)将安装包上传。
2)解压缩安装包:tar -zxvf apache-hive-0.13.0-bin.tar.gz
3)由于需要在Hive中访问MySQL,所以需要把MySQL的驱动程序Jar包上传至apache-hive-0.13.0/lib下。
驱动程序包下载地址:http://dev.mysql.com/downloads/connector/j/
4)更改apache-hive-0.13.0/conf的配置文件。在conf下面追加hive-site.xml文件(注意文件名必须是这个)
具体需要配置哪些值可以去MySQL的官方网站进行查询。
https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin#AdminManualMetastoreAdmin-RemoteMetastoreDatabase
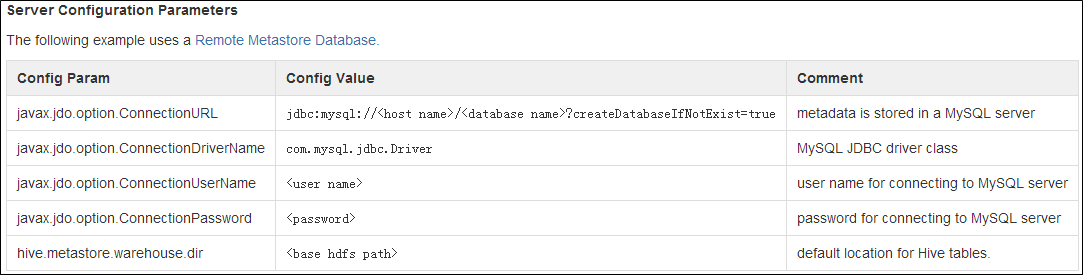
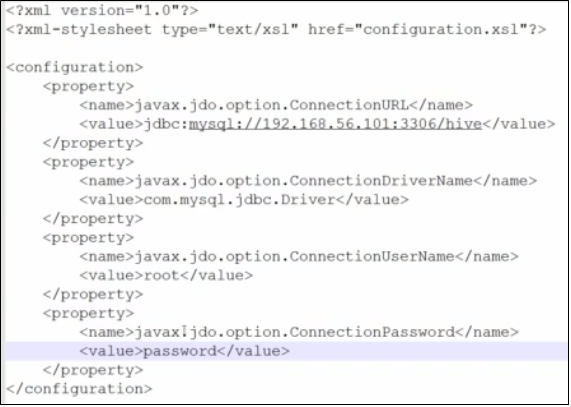
配置文件的内容大概如下:
===Hive安装之本地模式
与远程模式基本类似,只需要将配置文件中的链接地址修改为localhost即可。
===Hive的管理
Hive的启动方式
--CLI(命令行)方式
--Web界面方式
--远程服务启动方式
===Hive的管理之CLI方式(命令行方式)
启动方式
--直接输入#<HIVE_HOME>/bin/hive的执行程序
--或者输入#hive --service cli
===常用的CLI命令
--清屏:Ctrl + L 或者!clear
--查看数据仓库中的表:show tables;
--查看数据仓库中的内置函数:show functions;
--查看表结构:desc 表名
--查看HDFS上的文件:dfs -ls 目录,或者,dfs -lsr 目录(以递归的方式查看目录)
--执行操作系统的命令:!命令
--执行HQL语句:select * from test1;
注意:select * 的查询语句并不会转换成MapReduce作业。
--执行SQL的脚本:source SQL文件
*以上命令是在进入命令行模式下执行的,也可以不进入命令行模式来执行。hive -e 'show tables';
===CLI的静默模式命令
通常在执行SQL等脚本的时候,会转换成MapReduce作业,所以在控制台中会出现大量的日志信息。
如果不想关注这些日志信息,就可以启动CLI的静默模式。
--启动方法:hive -S(S为大写)
===Hive的管理之Web界面方式
--默认端口号:9999
--通过浏览器访问:http://<IP地址>:9999/hwi
--启动方式:#hive --service hwi
如果执行命令出错,可以编译Hive源代码,作成Jar包,如下:
1)解压缩:tar -zxvf apache-hive-0.13.0-src.tar.gz
2)进入apache-hive-0.13.0-src/hwi目录。下面有个Web目录,这里面保存的就是Web管理界面的JSP页面。
3)使用Jar命令打包:jar cvfM0 hive-hwi-0.13.0.war -C web/ .
4)将war包移动到hive的lib目录下。
5)修改hive-site.xml配置文件。
<property>
<name>hive.hwi.listen.host</name> //
<value>0.0.0.0</value>
<description>This is the host address the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>/usr/lib/hive/lib/hive_hwi.war</value>
<description>This is the WAR file with the jsp content for Hive Web Interface</description>
</property>
6)拷贝JDK的tools.jar:cd <JDK_HOME>/lib/tools.jar <HIVE_HOME>/lib/
如果不拷贝这个工具包,访问Web界面时会出现500的错误。
6)重新启动Web界面:hive --service hwi > hwi.log
===Hive的远程服务
如果以JDBC或ODBC的程序登录到hive中操作数据时,必须选用远程服务启动方式。
--端口号:10000
--启动方式:#hive --service hiveserver
===Hive的数据类型之基本数据类型

--整数类型:tinyint/smallint/int/bigint
--浮点数类型:fload/double
--布尔类型:boolean
--字符串类型:string
每种类型的精度可以参考Hive的官方帮助文档
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
===Hive的数据类型之复杂数据类型
--数组类型:Array,由一系列相同数据类型的元素组成。
create table student1 (
sid int,
sname string,
grade array<float>;
)
数据插入形式:(1, Tom, [80,90,75])
--集合类型:Map,包含key->value键值对,可以通过key来访问元素。
create table student2 (
sid int,
sname string,
grade map<string, float>;
)
数据插入形式:(1, Tom, <'大学语文',85>)
create table student3 (
sid int,
sname string,
grades array<map<sring, float>>;
)
数据插入形式:(1, Tom, [<'大学语文',85>, <'高等数学',90>])
--结构类型:Struct,可以包含不同数据类型的元素,这些元素可以通过"点语法"的方式来得到所需要的元素。
create table student4 (
sid int,
info struct<name:string, age:int, sex:string>;
)
数据插入形式:(1, {'Tom', '20', '男'})
===Hive的数据类型之时间数据类型
--Data(从Hive0.12.0开始支持)
--Timestamp(从0.8.0开始支持)
两者有区别,也可以使用日期函数进行相互转换。
===Hive的数据存储
--基于HDFS
--没有专门的数据存储格式
--存储结构主要包括:数据库、文件、表、视图
--可以直接加载文本文件(.txt文件等)
--创建表时,指定Hive数据的列分隔符与行分隔符
===Hive的数据模型
1)表
--Table:内部表
--Partition:分区表
--External Table:外部表
--Bucket Table:桶表
2)视图
是一个逻辑概念,类似于我们的表
===内部表
--与数据库中的Table在概念上是类似的。
--每一个Table在Hive中都有一个相应的存储数据。
--所有的Table数据(不包括External Table)都保存在这个目录中。
--删除表的时候,元数据与数据都会被删除。
创建表的命令:
create table t1 (tid int, tname string, age int;)
可以指定HDFS的创建目录:
create table t2 (tid int, tname string, age int;) location '/mytable/hive/t2';
可以志明列与列的分隔符:
create table t3 (tid int, tname string, age int;) row format delimited fields terminated by ',';
创建表的同事插入数据:
create table t4 as select * from sample_data;
变更表结构:如添加列
alter table t1 add columns (qnglish int);
删除表:会将表移入到回收站当中。
drop table t1;
===分区表(Partition Table)
--Partition对应于数据库中的Partition列的密集索引
--在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。
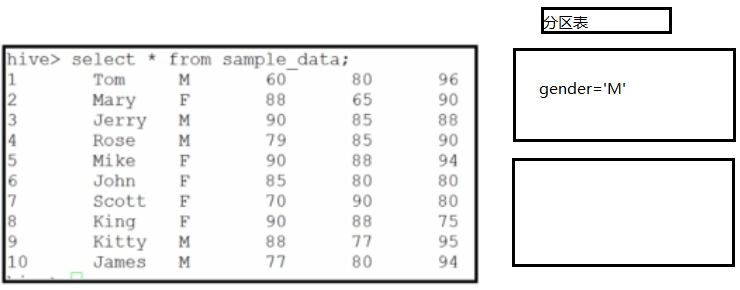
创建一张基于性别的分区表,以逗号分隔:
create table partition_table(sid int, sname string) partitioned by (gender string)
row format delimited fields terminated by ',';
创建之后,查询一下表的结构可以看分区信息。

向分区表中插入数据
insert into table partition_table partition(gender='M') select sid, sname from sample_data where gender='M';
insert into table partition_table partition(gender='F') select sid, sname from sample_data where gender='F';
分区表是非常有用的,当我们的数据量非常大的时候,我们需要按照一定的条件将数据分区,
这样在我们查询操作的时候就能降低需要遍历的记录数,从而提高查询的效率。
===外部表(External Table)
--指向已经在HDFS中存在的数据的表,它也可以来创建Partiton
--它和内部表在元数据的组织上是相同的,也就是说外部表依然是保存在我们的数据库当中。而实际数据的存储则有较大的差异。
--外部表"只是一个过程",加载数据和创建表同事完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅仅删除该链接。
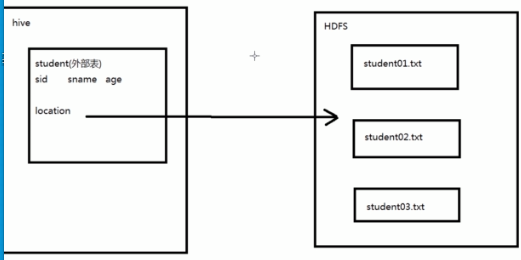
创建外部表
create external table external_student(sid int, sname string, age int) location '/input'
row format delimited fields terminated by ',';
*location是HDFS中的路径。
===桶表(Bucket Table)
--桶表是对数据进行哈希取值,然后放到不同文件中存储。
桶表中的数据是经过哈希运算之后,将之打散了存在文件当中。这样的好处是可以避免造成“热块”。
创建桶表
create table bucket_table(sid int, sname string, age int) clustered by (sname) into 5 buckets
(有待细化)
===视图(View)
--视图是一种虚表,是一个逻辑概念;可以扩越多张表。
--视图建立在已有表的基础上,视图赖以建立的这些表称为基表。
--视图可以简化复杂的查询。(最大的优点)
创建视图
create view empinfo as <SQL语句>
===入门总结
数据仓库的基本概念
搭建数据仓库的基本过程
什么是Hive?Hive的体系结构
Hive的安装和管理
Hive的数据模型
--END--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号