
Hadoop入门学习随笔
推荐视频:慕课网http://www.imooc.com/video/8107
===Hadoop是什么?
开源的、分布式存储+分布式计算平台。
http://hadoop.apache.org
===Hadoop的组成
包括两个核心组成:
HDFS:分布式文件系统,存储海量的数据
MapReduce:并行处理框架,实现任务分解和调度
===Hadoop可以用来做什么?
搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务。
===Hadoop的优势:
高扩展:理论上是可以做到无限的,因为在它的设计框架下面,可以通过一些简单的增加一些硬件来提升性能和容量
低成本:借鉴Google的思想,借助普通的PC机就可以实现。
成熟的生态圈:借助开源的力量,围绕Hadoop有很多开源的工具。
===Hadoop的应用情况
===Hadoop生态系统
*HDFS全称:Hadoop Distributed File System
常用开源工具有:
Hive:利用Hive可以不用编写复杂的Hadoop任务程序,只需要写一个SQL语句,Hive就会将SQL转换成一个Hadoop任务。降低了使用Hadoop的门槛。
HBase:存储结构化数据的分布式数据库。与传统的关系型数据库不同,HBase放弃了事务这个特性,追求更高的扩展。和HDFS不同,HBase提供数据的随机读写和实时访问,实现对数据库的读写功能。
zookeeper:动物管理员。就像动物管理员一样,它要监控Hadoop集群里面每个节点的状态,管理整个集群的配置,维护节点之间的数据一致性等等。
===Hadoop的安装
(1)前提准备
①、安装JDK
②、配置无秘钥访问。
(2)配置文件
我这里使用的是hadoop-2.5.1。各个配置文件的详解,可以参考一下两个网站:
官网:http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-common/ClusterSetup.html
博客:http://blog.163.com/yangshaohui_2004/blog/static/618545020144495622847/
博客:http://slaytanic.blog.51cto.com/2057708/1101111/
(3)环境变量
vim /etc/profile
export HADOOP_HOME=/opt/hadoop1.2.1
exprot PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$PATH
source /etc/profile
(4)结果验证
配置完了之后,在任意位置输入hadoop命令,都应该可以正常执行。
在执行之前,需要对namenode进行格式化操作:hadoop namenode -format
使用start-all.sh启动hadoop。
使用jps命令查看hadoop是否正常执行,正常执行时的进程如下:
7005 JobTracker
7329 Jps
6824 DataNode
7259 TaskTracker
6647 NameNode
7001 SecondaryNameNode
===HDFS的基本概念
-块(Block) HDFS的文件被分成块进行存储,块的默认大小64MB,块是文件存储处理的逻辑单元。
-NameNode 是管理节点,存放文件元数据。包括:①文件与数据块的映射表,②数据块与数据节点的映射表
-DataNode HDFS的工作节点,存放数据块。
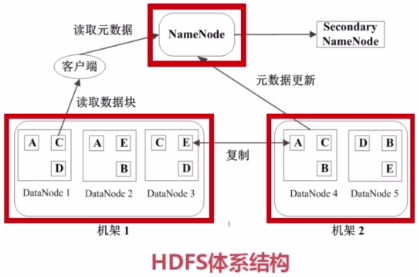
===HDFS数据管理策略
1)数据块的放置:每个数据块3个副本,分布在两个机器内的三个节点。
2)心跳检测:DataNode与NameNode之间有一个心跳协议,每隔多少秒钟DataNode会想NameNode报告状况(发送心跳信息)。
3)二级NameNode:二级NameNode定期同步元数据映像文件和修改日志。NameNode发生故障时,备胎转正。
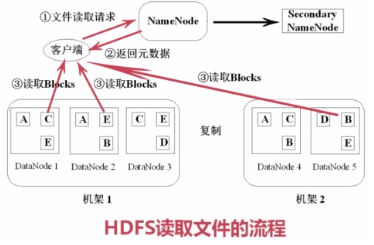
===HDFS读取文件的流程
1)从客户端向NameNode发送读取数据请求。这个请求可能是一个Java程序,也可能是一个命令行。
2)NameNode返回元数据信息。告诉客户端,这些数据都有哪些块,这些块都在哪里可以找到等。
3)客户端从DataNode中下载数据块并进行组装。
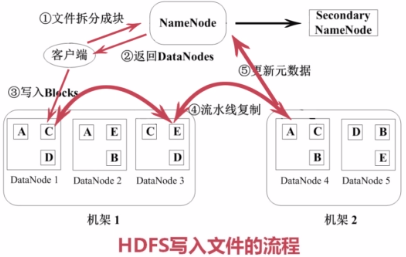
===HDFS写入文件的流程
1)将文件拆分成固定大小的块,通知NameNode。
2)NameNode会找到一些可用的DataNode返回给客户端。
3)根据返回的结果将数据块写入DataNode。写入时,先写入一个块。
4)对写入的数据块进行进行流水线复制。
5)更新元数据。告诉NameNode更新已经完成,创建了一个新的数据块。
===HDFS特点:
1、数据冗余,硬件容错
2、流式的数据访问:就是一次写入多次读取,一旦写入之后不会进行修改。
3、适合存储大文件。如果大量的小文件的话,NameNode的压力会很大。
4、适用性和局限性
-适合数据批量读写、吞吐量高
-不适合交互式应用,低延迟很难满足
-适合一次写入多次读取,顺序读写
-不支持多用户并发写相同文件
===HDFS使用
HDFS里面提供了Shell接口。
hadoop namenode -farmat:安装完hadoop在启动之前的格式化命令
hadoop fs -ls /xxxx:打印当前HDFS的文件夹。/xxxx为要打印的文件夹路径。/为根目录。
hadoop fs -put xxxx:将本地文件提交到HDFS。xxxx为要提交的文件名。
hadoop fs -mkdir xxxx:建立路径。xxxx为要建立的路径。
hadoop fs -rm xxxx:删除文件。xxxx为要删除的文件。
hadoop fs -cat xxxx:查看文件。xxxx为要查看的文件。
hadoop fs -get xxxx yyyy:从HDFS下载文件至本地。xxxx为要下载的文件名,yyyy为本地路径。
hadoop dfsadmin -report:查看文件系统的所有信息。
===什么是MapReduce?
简单的说MapReduce采用了分而治之的思想,将一个大任务分成多个小的子任务(Map),
然后由多个小节点并行执行然后合并结果,合并的过程就是(Reduce)。
其实,很多计算的任务都可以抽象成两个步骤,一个Map、一个Reduce。
如:找出5000张扑克中,缺失的一张。
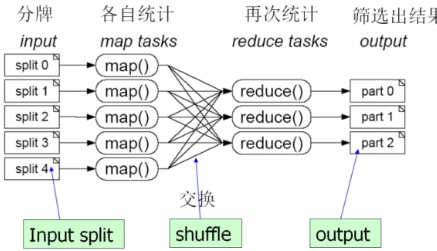
再如:100GB的网站访问日志文件,找出访问次数最多的IP地址
1)先把日志进行切分。如按时间切分。
2)统计没份文件中相同IP的访问次数。
3)根据一定的规则进行交换,归约IP的访问次数。
网上摘录的对 MapReduce 的最简洁明了的解析:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
===MapReduce的运行流程(Hadoop1.X)
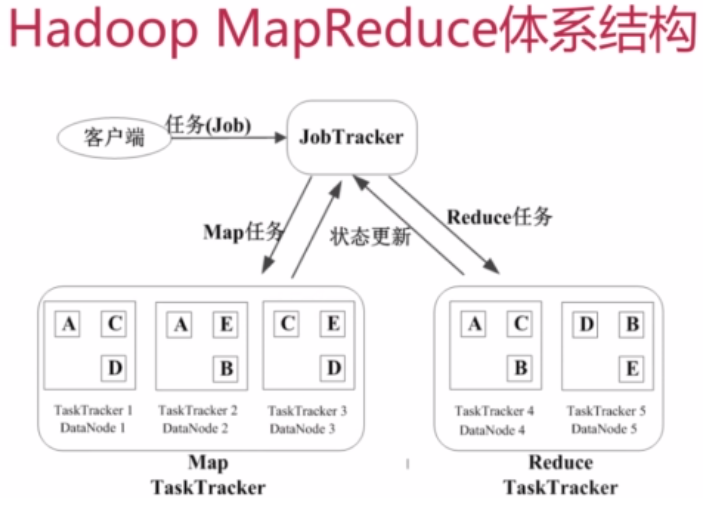
--Job&Task:
一个任务/作业。
如找出访问次数最多的IP地址。一个Job下分为多个Task,Task又分为MapTask和ReduceTask。
--JobTracker:
一个Mast管理节点。
负责接收客户端的任务,将任务房到候选队列里面,在适当的时候进行调度,选择一个Job出来,将Job分成多个Map和Reduce,然后分发给TaskTracker来处理。总结来说JobTracker的角色如下:
•作业调度
•分配任务、监控任务执行进度(TaskTracker在做的时候会定时给JobTracker通知状态)
•监控TaskTracker的状态
--TaskTracker:
在部署的时候,TackTracker往往和HDFS的DataNode是同一组物理节点,以保证计算是跟着数据走。总结来说TaskTracker的角色如下:
•执行任务
•汇报任务状态
===MapReduce作业执行过程
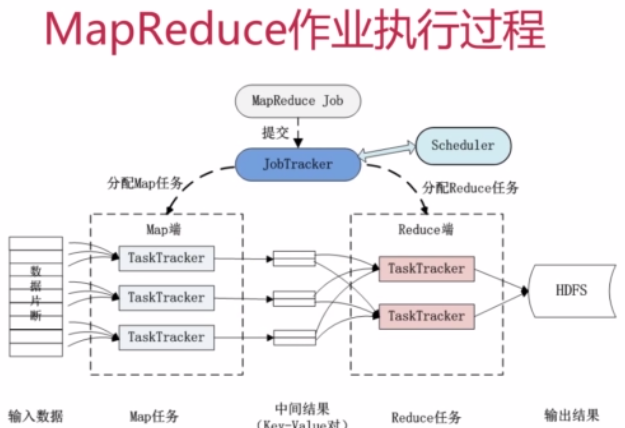
对输入数据进行分片,按照一定的规则分给TaskTracker。分配Map任务。
任务处理好之后产生一个中间结果(key-value对),key和value根据一些映射规则进行交换。
然后到Reduce端进行处理,运算完之后,数据结果写会到HDFS里面。
Map-Reduce可以进行多次。完成复杂的计算操作。
===MapReduce的容错机制
有两种机制:
1)重复执行:默认重复执行4次只有,如果仍然出错,将放弃执行
2)推测执行:在整个任务执行过程中,需要等待整个Map端都计算完成之后,Reduce端才会开始。
这个时候,可能会存在某个节点计算特别慢。JobTracker一旦发现这种情况,将重新安排一个TaskTracker去做同样的事情,只要这个事情两者谁先完成,就会将另一个终止执行。
===MapReduce应用案例(WordCount单词计数)
1)思考实现过程
计算文件中出现每个单词的频数,输出结果按照字母顺序排序。
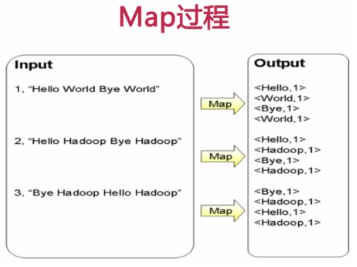
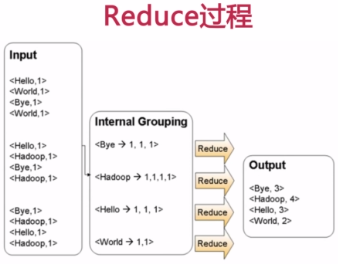
2)编写实现代码。如WordCount.java,包含Mapper类和Reducer类。
3)编译WordCount.java成Class。命令如下:
javac -classpath /opt/hadoop-1.2.1/hadoop-cour-1.2.1.jar:/opt/hadoop-1.2.1/lib/commons-cli-1.2.jar -d word_count_class/ WordCount.java
4)打包。命令如下例:
jar -cvf WordCount.jar *.classes
5)作业提交。命令如下:
hadoop jar WordCount.jar WordCount input output
===利用MapReduce进行排序
数据排序是许多任务数据中的第一项任务。
基本思路:将数据进行分片,然后进行Reduce真正排序。如下例:
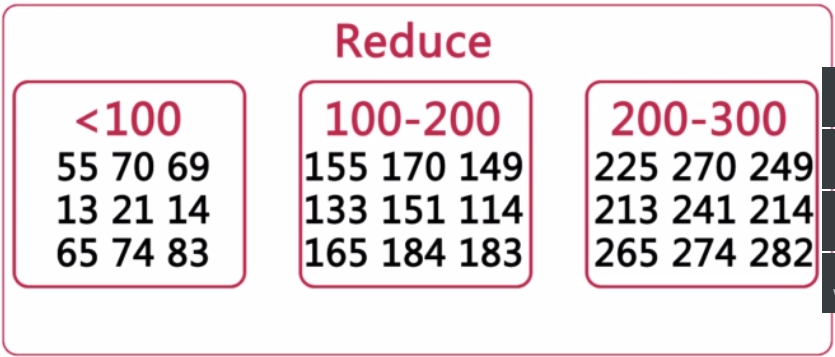
--END--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号