Flink DataStream Operators(Java)
==官网地址==
https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/operators/
==nc工具==
【Windows】
配置windows的nc端口,在网上下载nc.exe(https://eternallybored.org/misc/netcat/)
使用命令开始nc制定端口为9000(nc -L -p 9001 -v) 启动插件

【Linux】
Linux平台上可以使用
nc -lk 9000
==Git代码==
以下的样例代码都上传到了Git上,供参考。
https://github.com/quchunhui/demo-macket/tree/master/flink
==参考博客==
以下测试部分参考了网友的博客
https://blog.csdn.net/chybin500/article/details/87260869
==算子关系==

==Map==
[DataStream -> DataStream]
map可以理解为映射,对每个元素进行一定的变换后,映射为另一个元素。
调用用户定义的MapFunction对DataStream[T]数据进行处理,形成新的DataStream[T],其中数据格式可能会发生变化,常用作对数据集内数据的清洗和转换。
package demo; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class MapDemo { private static int index = 1; public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听9000端口的socket消息 DataStream<String> textStream = env.socketTextStream("localhost", 9001, "\n"); //3.map操作。 DataStream<String> result = textStream.map(s -> (index++) + ".您输入的是:" + s); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } }
socket输入:

控制台显示:

==FlatMap==
[DataStream -> DataStream]
flatmap可以理解为将元素摊平,每个元素可以变为0个、1个、或者多个元素。
package demo; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class FlatMapDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听9000端口的socket消息 DataStream<String> textStream = env.socketTextStream("localhost", Constants.PORT, "\n"); //3.flatMap操作,对每一行字符串进行分割 DataStream<String> result = textStream.flatMap(new Splitter()) //这个地方要注意,在flatMap这种参数里有泛型算子中。 //如果用lambda表达式,必须将参数的类型显式地定义出来。 //并且要有returns,指定返回的类型 //详情可以参考Flink官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.6/dev/java_lambdas.html .returns(Types.STRING); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } public static class Splitter implements FlatMapFunction<String, String> { @Override public void flatMap(String sentence, Collector<String> out) { for (String word: sentence.split("")) { out.collect(word); } } } }
socket输入内容:

控制台输出的结果:

==Fliter==
[DataStream -> DataStream]
该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出,将不符合条件的数据过滤掉。
package demo; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class FilterDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听9000端口的socket消息 DataStream<String> textStream = env.socketTextStream("localhost", Constants.PORT, "\n"); //3.filter操作,筛选非空行。 DataStream<String> result = textStream.filter(line->!line.trim().equals("")); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } }
socket中输入:

控制台输出的结果:

==keyBy==
[DataStream -> KeyedStream]
该算子根据指定的key将输入的DataStream[T]数据格式转换为KeyedStream[T],也就是在数据集中执行Partition操作,将相同的key值的数据放置在相同的分区中。简单来说,就是sql里面的group by。
逻辑上将Stream根据指定的Key进行分区,是根据key的散列值进行分区的。
package demo; import java.util.concurrent.TimeUnit; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; public class KeyByDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听端口的socket消息 DataStream<String> textStream = env.socketTextStream("localhost", Constants.PORT, "\n"); //3. DataStream<Tuple2<String, Integer>> result = textStream //map是将每一行单词变为一个tuple2 .map(line -> Tuple2.of(line.trim(), 1)) //如果要用Lambda表示是,Tuple2是泛型,那就得用returns指定类型。 .returns(Types.TUPLE(Types.STRING, Types.INT)) //keyBy进行分区,按照第一列,也就是按照单词进行分区 .keyBy(0) //指定窗口,每10秒个计算一次 .timeWindow(Time.of(10, TimeUnit.SECONDS)) //计算个数,计算第1列 .sum(1); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } }
socket输入:
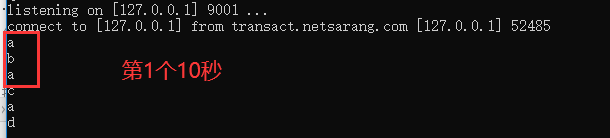
控制台输出的结果:
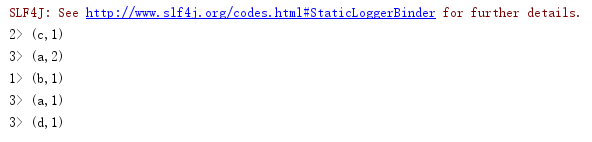
==Reduce==
[KeyedStream -> DataStream]
该算子和MapReduce的Reduce原理基本一致,主要目的是将输入的KeyedStream通过传入的用户自定义的ReduceFunction滚动的进行数据聚合处理,其中定义的ReduceFunction必须满足运算结合律和交换律。
package demo; import java.util.concurrent.TimeUnit; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; public class ReduceDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听端口的socket消息 DataStream<String> textStream = env.socketTextStream("localhost", Constants.PORT, "\n"); //3. DataStream<Tuple2<String, Integer>> result = textStream //map是将每一行单词变为一个tuple2 .map(line -> Tuple2.of(line.trim(), 1)) //如果要用Lambda表示是,Tuple2是泛型,那就得用returns指定类型。 .returns(Types.TUPLE(Types.STRING, Types.INT)) //keyBy进行分区,按照第一列,也就是按照单词进行分区 .keyBy(0) //指定窗口,每10秒个计算一次 .timeWindow(Time.of(10, TimeUnit.SECONDS)) //对每一组内的元素进行归并操作,即第一个和第二个归并,结果再与第三个归并... .reduce((Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) -> new Tuple2(t1.f0, t1.f1 + t2.f1)); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } }
socket输入:

控制台输出的结果:

==Fold==
给定一个初始值,将各个元素逐个归并计算。它将KeyedStream转变为DataStream。
不过这个API过时了,不建议使用。
package demo; import java.util.concurrent.TimeUnit; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; public class FoldDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听端口的socket消息 DataStream<String> textStream = env.socketTextStream("localhost", Constants.PORT, "\n"); //3. DataStream<String> result = textStream //map是将每一行单词变为一个tuple2 .map(line -> Tuple2.of(line.trim(), 1)) //如果要用Lambda表示是,Tuple2是泛型,那就得用returns指定类型。 .returns(Types.TUPLE(Types.STRING, Types.INT)) //keyBy进行分区,按照第一列,也就是按照单词进行分区 .keyBy(0) //指定窗口,每10秒个计算一次 .timeWindow(Time.of(10, TimeUnit.SECONDS)) //指定一个开始的值,对每一组内的元素进行归并操作,即第一个和第二个归并,结果再与第三个归并... .fold("结果:",(String current, Tuple2<String, Integer> t2) -> current+t2.f0+","); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } }
socket输入:

控制台显示:

==Union==
[DataStream -> DataStream]
将两个或者多个输入的数据集合并成一个数据集,需要保证两个数据集的格式一致,输出的数据集的格式和输入的数据集格式保持一致。
package demo; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class UnionDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听9000端口的socket消息 DataStream<String> textStream9000 = env.socketTextStream("localhost", 9000, "\n"); DataStream<String> textStream9001 = env.socketTextStream("localhost", 9001, "\n"); DataStream<String> textStream9002 = env.socketTextStream("localhost", 9002, "\n"); DataStream<String> mapStream9000 = textStream9000.map(s->"来自9000端口:" + s); DataStream<String> mapStream9001 = textStream9001.map(s->"来自9001端口:" + s); DataStream<String> mapStream9002 = textStream9002.map(s->"来自9002端口:" + s); //3.union用来合并两个或者多个流的数据,统一到一个流中 DataStream<String> result = mapStream9000.union(mapStream9001, mapStream9002); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } }
socket1(9000)输入:a
socket2(9001)输入:b
socket2(9002)输入:c 
控制台输出的结果:

==Join==
根据指定的Key将两个流进行关联。
package demo; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; public class JoinDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听9000端口的socket消息 DataStream<String> textStream9000 = env.socketTextStream("localhost", 9000, "\n"); DataStream<String> textStream9001 = env.socketTextStream("localhost", 9001, "\n"); //将输入处理一下,变为tuple2 DataStream<Tuple2<String,String>> mapStream9000 = textStream9000 .map(new MapFunction<String, Tuple2<String,String>>() { @Override public Tuple2<String, String> map(String s) throws Exception { return Tuple2.of(s, "来自9000端口:" + s); } }); DataStream<Tuple2<String,String>> mapStream9001 = textStream9001 .map(new MapFunction<String, Tuple2<String,String>>() { @Override public Tuple2<String, String> map(String s) throws Exception { return Tuple2.of(s, "来自9001端口:" + s); } }); //3.两个流进行join操作,是inner join,关联上的才能保留下来 DataStream<String> result = mapStream9000.join(mapStream9001) //关联条件,以第0列关联(两个source输入的字符串) .where(t1->t1.getField(0)).equalTo(t2->t2.getField(0)) //以处理时间,每10秒一个滚动窗口 .window(TumblingProcessingTimeWindows.of(Time.seconds(10))) //关联后输出 .apply((t1,t2)->t1.getField(1)+"|"+t2.getField(1)); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } }
socket9000输入:a

socket9001输入:a

控制台输出的结果:

如果两个socket输入内容不一样,则控制台没有输出。
==CoGroup==
关联两个流,关联不上的也保留下来。
package demo; import org.apache.flink.api.common.functions.CoGroupFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; public class CoGroupDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听9000端口的socket消息 DataStream<String> textStream9000 = env.socketTextStream("localhost", 9000, "\n"); DataStream<String> textStream9001 = env.socketTextStream("localhost", 9001, "\n"); //将输入处理一下,变为tuple2 DataStream<Tuple2<String, String>> mapStream9000 = textStream9000 .map(new MapFunction<String, Tuple2<String, String>>() { @Override public Tuple2<String, String> map(String s) throws Exception { return Tuple2.of(s, "来自9000端口:" + s); } }); DataStream<Tuple2<String, String>> mapStream9001 = textStream9001 .map(new MapFunction<String, Tuple2<String, String>>() { @Override public Tuple2<String, String> map(String s) throws Exception { return Tuple2.of(s, "来自9001端口:" + s); } }); //3.两个流进行coGroup操作,没有关联上的也保留下来,功能更强大 DataStream<String> result = mapStream9000.coGroup(mapStream9001) //关联条件,以第0列关联(两个source输入的字符串) .where(t1 -> t1.getField(0)).equalTo(t2 -> t2.getField(0)) //以处理时间,每10秒一个滚动窗口 .window(TumblingProcessingTimeWindows.of(Time.seconds(10))) //关联后输出 .apply(new CoGroupFunction<Tuple2<String, String>, Tuple2<String, String>, String>() { @Override public void coGroup(Iterable<Tuple2<String, String>> iterable, Iterable<Tuple2<String, String>> iterable1, Collector<String> collector) throws Exception { StringBuffer stringBuffer = new StringBuffer(); stringBuffer.append("来自9000的stream:"); for (Tuple2<String, String> item : iterable) { stringBuffer.append(item.f1 + ","); } stringBuffer.append("来自9001的stream:"); for (Tuple2<String, String> item : iterable1) { stringBuffer.append(item.f1 + ","); } collector.collect(stringBuffer.toString()); } }); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } }
socket9000上输入:abc
socket9001上输入:def

控制台输出的结果:

socket9000上输入:111
socket9001上输入:111

控制台输出的结果:

==Connect, CoMap, CoFlatMap==
[DataStream -> DataStream]
参考:https://www.jianshu.com/p/5b0574d466f8
将两个流纵向地连接起来。
Connect算子主要是为了合并两种后者多种不同数据类型的数据集,合并后会保留原来的数据集的数据类型。连接操作允许共享状态数据,也就是说在多个数据集之间可以操作和查看对方数据集的状态。
package demo; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.CoMapFunction; public class ConnectDemo { public static void main(String[] args) throws Exception { //1.获取执行环境配置信息 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.定义加载或创建数据源(source),监听9000端口的socket消息 DataStream<String> textStream9000 = env.socketTextStream("localhost", 9000, "\n"); DataStream<String> textStream9001 = env.socketTextStream("localhost", 9001, "\n"); //转为Integer类型流 DataStream<Integer> intStream = textStream9000.filter(s -> isNumeric(s)).map(s -> Integer.valueOf(s)); //连接起来,分别处理,返回同样的一种类型。 SingleOutputStreamOperator result = intStream.connect(textStream9001) .map(new CoMapFunction<Integer, String, Tuple2<Integer, String>>() { @Override public Tuple2<Integer, String> map1(Integer value) throws Exception { return Tuple2.of(value, ""); } @Override public Tuple2<Integer, String> map2(String value) throws Exception { return Tuple2.of(null, value); } }); //4.打印输出sink result.print(); //5.开始执行 env.execute(); } private static boolean isNumeric(String str) { Pattern pattern = Pattern.compile("[0-9]*"); Matcher isNum = pattern.matcher(str); return isNum.matches(); } }
在socket9000和9001上随便进行了一些输入

控制台上输出如下:

==Split-Select(已过时)==
==Side-Output(现推荐)==
参考:https://blog.csdn.net/wangpei1949/article/details/99698868
注意:
Side-Output是从Flink 1.3.0开始提供的功能,支持了更灵活的多路输出。
Side-Output可以以侧流的形式,以不同于主流的数据类型,向下游输出指定条件的数据、异常数据、迟到数据等等。
Side-Output通过ProcessFunction将数据发送到侧路OutputTag。
package demo; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; /** * 注意: * Side-Output是从Flink 1.3.0开始提供的功能,支持了更灵活的多路输出。 * Side-Output可以以侧流的形式,以不同于主流的数据类型,向下游输出指定条件的数据、异常数据、迟到数据等等。 * Side-Output通过ProcessFunction将数据发送到侧路OutputTag。 */ public class SplitStreamBySideOutput { public static void main(String[] args) throws Exception{ //运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //输入数据源 DataStreamSource<Tuple3<String, String, String>> source = env.fromElements( new Tuple3<>("productID1", "click", "user_1"), new Tuple3<>("productID1", "click", "user_2"), new Tuple3<>("productID1", "browse", "user_1"), new Tuple3<>("productID2", "browse", "user_1"), new Tuple3<>("productID2", "click", "user_2"), new Tuple3<>("productID2", "click", "user_1") ); //1、定义OutputTag OutputTag<Tuple3<String, String, String>> sideOutputTag = new OutputTag<Tuple3<String, String, String>>("side-output-tag"){}; //2、在ProcessFunction中处理主流和分流 SingleOutputStreamOperator<Tuple3<String, String, String>> processedStream = source.process(new ProcessFunction<Tuple3<String, String, String>, Tuple3<String, String, String>>() { @Override public void processElement(Tuple3<String, String, String> value, Context ctx, Collector<Tuple3<String, String, String>> out) throws Exception { //侧流-只输出特定数据 if (value.f0.equals("productID1")) { System.out.println("1"); ctx.output(sideOutputTag, value); //主流 }else { System.out.println("2"); out.collect(value); } } }); //获取主流 processedStream.print(); //获取侧流 processedStream.getSideOutput(sideOutputTag).print(); //开始执行 env.execute(); } }
--END--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号