
python爬虫-基础巩固
网络爬虫(又称网络蜘蛛、网络机器人)就是模拟客户端(浏览器)发送网络请求(伪造请求),然后接收请求响应。一种按照一定的规则,自动地抓取互联网信息的程序。
所谓"模拟"就是去照着做,说白了,就是让爬虫得到跟浏览器一样的响应。而且,只要浏览器能够做的事情,原则上,爬虫都能做。
补充一点:比如你爬了某鱼平台的一个主播,这个主播有一千万人在看,其中很多是机器人,但你无法分辨哪些是真人哪些是机器人。因为浏览器也是获得了这一千万人,你也只能获得到这一千万人。
总结来说,客户端怎么样的,爬虫也是拿到这样的。无法一下子就判断出数据的真假。
数据从何而来
1.企业产生的
2.数据平台购买
3.政府/机构公开的
4.爬取网络数据
爬虫的分类
1.通用爬虫:通常指搜索引擎的爬虫,它是搜索引擎抓取系统的组成,大而全但信息不精确
2.聚焦爬虫:针对特定网站的爬虫,抓取之前先筛选内容,只抓取需要的数据
几点提示:
1.requests很好用,但个别难缠的网站还是要用urllib
2.打码平台可以对付12306图片验证码
3.网页上找不到数据,可以把浏览器调成手机模式
Python字符串内容补充
字符串的两种表现形式:
1.bytes类型:二进制。网上数据都是以二进制的方式进行传输
2.str类型:unicode的呈现形式
ASCII、GB2312、unicode等都是字符集
ASCII编码是1个字节,unicode编码通常是2个字节。
UTF-8是unicode的实现方式之一(UTF-8是unicode的升级版或子集),UTF-8是一种变长的编码,可以是1、2、3个字节。
Python3中bytes和str之间的类型转换:
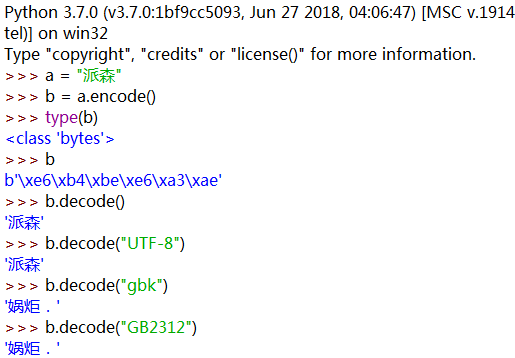
encode()编码,默认utf-8;decode()解码,默认也是utf-8
注意:编码时若指定了其他编码格式,那么解码时也必须是对应的编码,否则就会发生解码解出来不是原本的内容或是一堆看不懂的乱码,甚至报错!
HTTP/HTTPS
HTTP:超文本传输协议,默认端口80。所谓协议就是互联网的约定,约定好怎么传数据,怎么拿数据。
HTTPS:HTTP+SSL(安全套接字层),默认端口443。发送数据时进行加密,接受到数据时先解密再拿数据。
HTTPS更加安全,但效率比较慢。
备注:在Django开发中是可以指定80端口的,但小于1000的端口号需要超级管理员权限才能启动。
URL的形式
scheme://host[:port#]/path/.../[?query-string][#anchor]
scheme:协议,如:http、https、ftp
host:服务器的IP或域名
port:服务器的端口(走默认协议的话是80/443)
path:访问资源的路径
query-string:参数,发送给http服务器的数据
anchor:锚(跳转到网页指定锚点位置)。在发送请求时,加锚和不加锚是一样的,不会发生再次请求。
请求头
User-Agent:浏览器名称,服务器通过这个知道是哪个设备来请求的
(小写的q表示权重,表示更愿意接受哪个)
cookie:服务器可以通过cookie的某些字段来判断是否为爬虫。(cookie保存在本地端,有一定的上限;session保存在服务器端,只要服务器资源够,就是无上限)
静态HTML和动态HTML
内容通过JS(AJAX)加载的,就是动态HTML页面。静态HTML页面,就是本来就有内容。
浏览器渲染出来的页面和爬虫请求的页面并不一样。
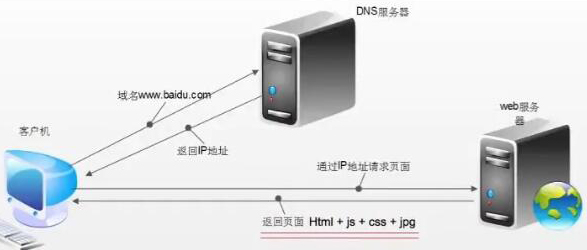
爬虫的工作流程

浏览器发送HTTP请求的过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号