
Redis
在实际开发中,一个产品为了留住客户总是为客户送一些优惠券,但是这些优惠券都是有过期时间的,如何设置并保证这些优惠券的过期时间呢?如何保证用户订单过期15分钟就失效呢?
第一个我想到的就是定时任务,通过设置一个定时任务,每个多少时间就扫描数据库信息,扫描出未处理的订单,判断是否超过15分钟,让它失效。
由于使用定时任务是会对数据库造成影响的,当数据库数据量比较大时,每个几秒钟就扫描数据库,对数据库的压力是很大的。
第二个就是消息通知。使用Redis,由于Redis可以当做缓存组件来使用,并可以设置过期时间。当用户下一个订单之后,将这个用户订单信息存入Redis缓存中,并设置一个过期时间,当超过过期时间之后,订单信息会自动销毁。
存在通知服务器,这个通知服务器中存在一些过期消息,然后发送数据到java代码中,最后更新数据库中过期消息的状态。
介绍一下Redis的缓存
缓存穿透
用最简单的语言概况为:每次使用一个数据库一定不存在的数据去访问访问数据库,当大量的恶意请求访问数据库,对数据库的压力是非常大的,可能会造成数据库垮掉。
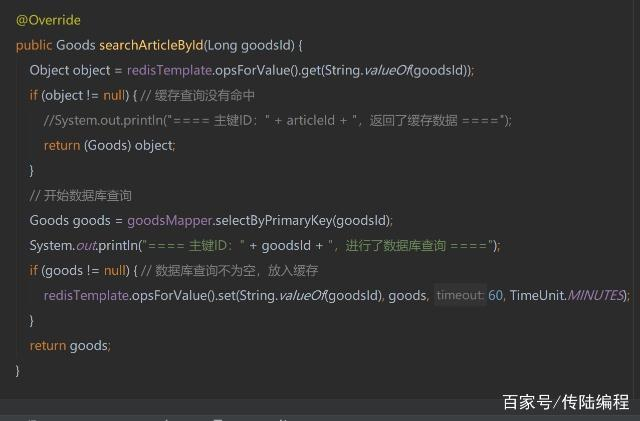
一般我们查询某个数据,先查询缓存中是否存在,如果缓存中不存在,那么再查询数据库,如果数据库查到了就放入缓存中,如果数据库查询为null,那么什么都不做。这种操作本身是没有什么问题的,但是当大量的不存在的请求访问数据库,这个时候就出现了问题。
一般的解决方法是:如果数据库查询未null,那么设置这个key的value为null,并设置过期时间,但是这个过期时间越短和越长都不好。为什么呢?过期时间短的话,一旦又有请求那么又要查询数据库,压力又大了。过期时间长的话,当大量的请求查询为null的话,都要将key:null存入缓存中,但是这个是吃内存的,对内存开销就很大。
缓存雪崩
在某一个时间段,缓存集中过期失效
当某个时间段内我向redis缓存中存入了大量的数据,并设置了过期时间,但是但这个过期时间一到的时候,同时刚好又有大量请求访问,那么直接就是去数据库查询,直接将数据库压蹦。
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
比如在做电商项目的时候,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
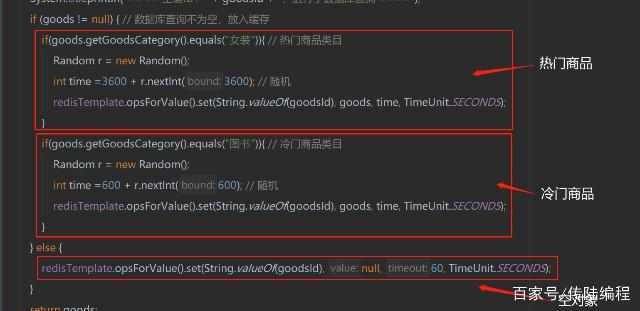
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,那么那个时候数据库能顶住压力,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
在做电商项目的时候,把这货就成为“爆款”。
其实,大多数情况下这种爆款很难对数据库服务器造成压垮性的压力。达到这个级别的公司没有几家的。所以,往往对主打商品都是早早的做好了准备,让缓存永不过期。即便某些商品自己发酵成了爆款,也是直接设为永不过期就好了。
Redis的持久化
Redis的持久化非常重要,项目里面会遇到,面试的时候也会问,所以我这里专门记录一下。
Redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为“半持久化模式”);也可以把每一次数据变化都写入到一个append only file(aof)里面(这称为“全持久化模式”)。
由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。redis提供两种方式进行持久化,一种是RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化),另外一种是AOF(append only file)持久化(原理是将Reids的操作日志以追加的方式写入文件)。那么这两种持久化方式有什么区别呢,改如何选择呢?网上看了大多数都是介绍这两种方式怎么配置,怎么使用,就是没有介绍二者的区别,在什么应用场景下使用。
Redis为持久化提供了两种方式:
1 RDB:在指定的时间间隔能对你的数据进行快照存储。
2 AOF:记录每次对服务器写的操作,当服务器重启的时候回重新执行这些命名来回复原始数据。
持久化的配置:
为了能够更好的使用持久化功能,我们需要开启某些功能。
RDB的持久化配置:
# 时间策略 save 900 1 save 300 10 save 60 10000 # 文件名称 dbfilename dump.rdb # 文件保存路径 dir /home/work/app/redis/data/ # 如果持久化出错,主进程是否停止写入 stop-writes-on-bgsave-error yes # 是否压缩 rdbcompression yes # 导入时是否检查 rdbchecksum yes
- save 900 1:表示900秒内如果有1次是写入命令,就触发一次快照,可以理解为进行存储备份
- save 300 10:表示300秒内如果有10次是写入命令,就触发快照,进行数据存储备份
那为什么我们需要配置这么多的规则呢?因为每个Redis的每个时间段的读写请求肯定不是均匀的,可能某个时间读写请求少,也可能请求多,所以我们需要根据实际需求来设置这些配置。
- stop-write-on-bgsave-error yes:这个配置也是非常重要的配置,这是当备份进程出错时,主线程就停止接受新的写入操作,这是为了保护数据一致性的问题。因为不可能由于备份的时候出错导致数据前后不一致,当然如果你有非常完善的监控系统,你可以禁用此项,当然一般是开启的
- rdbchecksum yes:建议没有必要开启,毕竟redis本身就属于CPU密集型服务器,再开启压缩会带来更多的内存消耗,相比硬盘成本,CPU更值钱
当然如果你想要禁用RDB配置,也是非常容易的,只需要在save的最后一行写上:save ""
AOF的配置
# 是否开启aof appendonly yes # 文件名称 appendfilename "appendonly.aof" # 同步方式 appendfsync everysec # aof重写期间是否同步 no-appendfsync-on-rewrite no # 重写触发配置 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb # 加载aof时如果有错如何处理 aof-load-truncated yes # 文件重写策略 aof-rewrite-incremental-fsync yes
appendfsync everysec,它其实有三种模式:
- alwarys:把每个写命令都立即头部到aof中,很安全。当然往往非常安全就意味着很慢
- everysec:每秒同步一次,是折中方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号