


综合练习:词频统计
world = f.read()
f.close()
xiaoqu = {'the','and','of','to', 'a', 'on','in','was','his','at','that','as','were','said','by','with', 'we','all','he',}
depart = ''',.?":!'''
for c in depart:
world = world.replace(c,' ')
wordlist = world.lower().split()
wordDict = {}
wordSet = set(wordlist) - xiaoqu
for a in wordSet:
wordDict[a] = wordlist.count(a)
dictlist = list(wordDict.items())
dictlist.sort(key=lambda x:x[1], reverse=True)
for i in range(20):
print(dictlist[i])
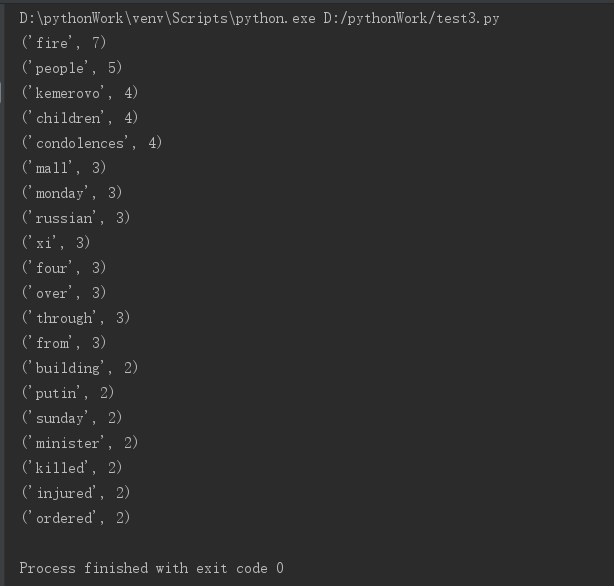
运行结果
2.中文词频统计
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20(或把结果存放到文件里)
# -*- codding: UTF-8 -*-
# -*- author: WF -*-
import jieba
f = open('hongloumeng.txt','r',encoding='utf-8') #将文本放在同等的路径下,以文件的方式读出来
hongloumeng = f.read()
f.close()
depart = '''?":“。”.!'《》''' #用循环列表,用空格来代替,.?":!标点符号
for c in depart:
hongloumeng = hongloumeng.replace(c,' ')
hongloumenglist = list(jieba.cut(hongloumeng))
paichu = [' ','了','的','我','\n','他','道', '你','也','是','又','着','去','来', '在','都','不',
'虽','为','却','那','亦','之','将','这','便','则','只','但','乃','再','因','得','此','与']
hongloumengDict = {} #生成一个空字典
for a in hongloumenglist:
hongloumengDict[a] = hongloumengDict.get(a,0)+1
for a in paichu:
del (hongloumengDict[a]);
dictlist = list(hongloumengDict.items())
dictlist.sort(key=lambda x:x[1], reverse=True)
f = open('hongloumengcount.txt','a')
for i in range(20): # 输出前20个
f.write(dictlist[i][0]+" "+str(dictlist[i][1])+'\n')
f.close()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号