爬虫入门----小说下载(静态网页的文字爬取)
小说下载
工具
Python3.6 + Requests + BeautifulSoup4
PS:点击 Requests 或 BeautifulSoup 可查看对应中文文档
任务
通过Python的爬虫下载一本小说。
此次爬取的网站为 http://www.kbiquge.com/
分析
首先我们随便打开一个小说打开一章看看
如:斗罗大陆的 引子 穿越的唐家三少 (url:http://www.kbiquge.com/104_104216/28964753.html)
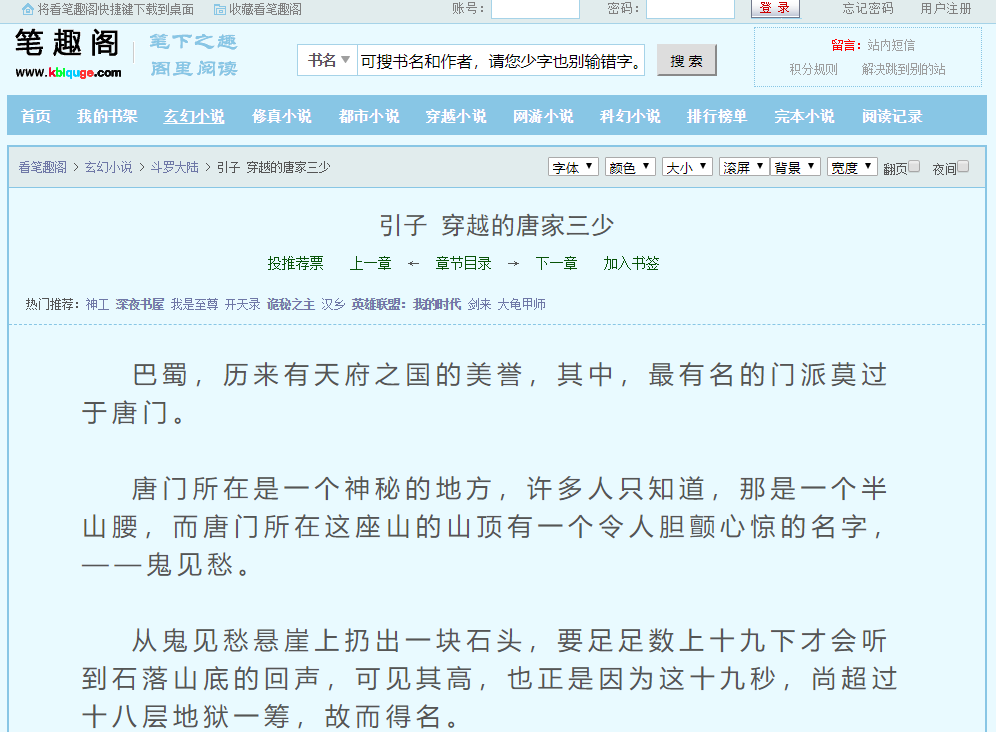
图一
我们可以使用requests来获取一下页面内容(这个极少的代码就不贴了。大家动手一下哈)
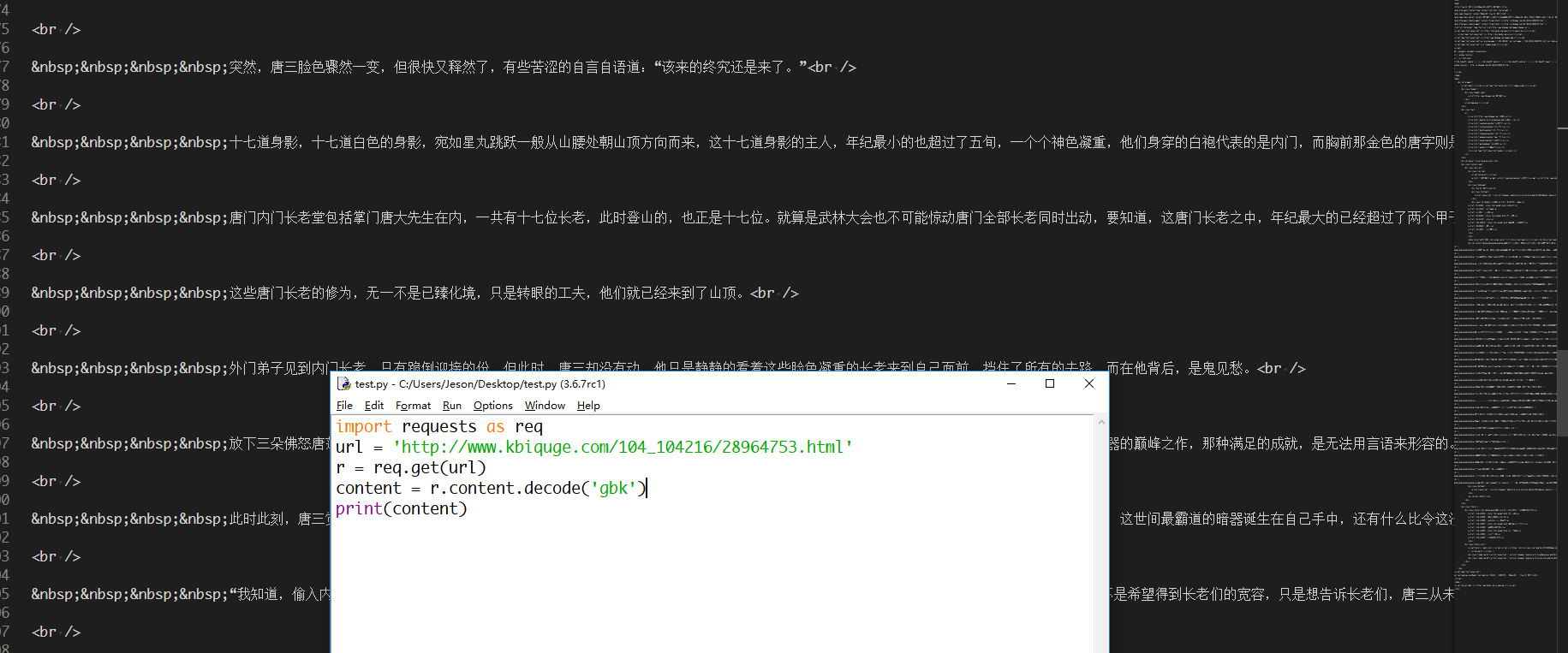
图二
可以正常获取。那这个格式因为是源代码,所以有大量的非小说内容。
在这里看源代码 emmm 确实很难受。Chrome 页面内右键检查,或直接F12可以动态查看修改源代码(其他浏览器同理)
接下来我们使用BeautiSoup来获取我们需要的部分(以下是内容部分,标题同理可获取)
1 import re 2 import requests as req 3 from bs4 import BeautifulSoup as bs 4 5 url = 'http://www.kbiquge.com/104_104216/28964753.html' 6 7 r = req.get(url) 8 text = r.content.decode('gbk') 9 b = bs(text) 10 11 # 数据清洗 12 # 以下步骤可以自行逐步执行,以便熟悉其作用 13 content = b.find_all(id='content') # 获取id为content的标签 14 content = content[0].text # 清除html标签 15 content = re.sub(u'[\u3000, \xa0]', '', content).replace(' ', '') # 清理空格 16 content = content.replace('\n\r', '') # 清楚多余换行回车 17 print(content)
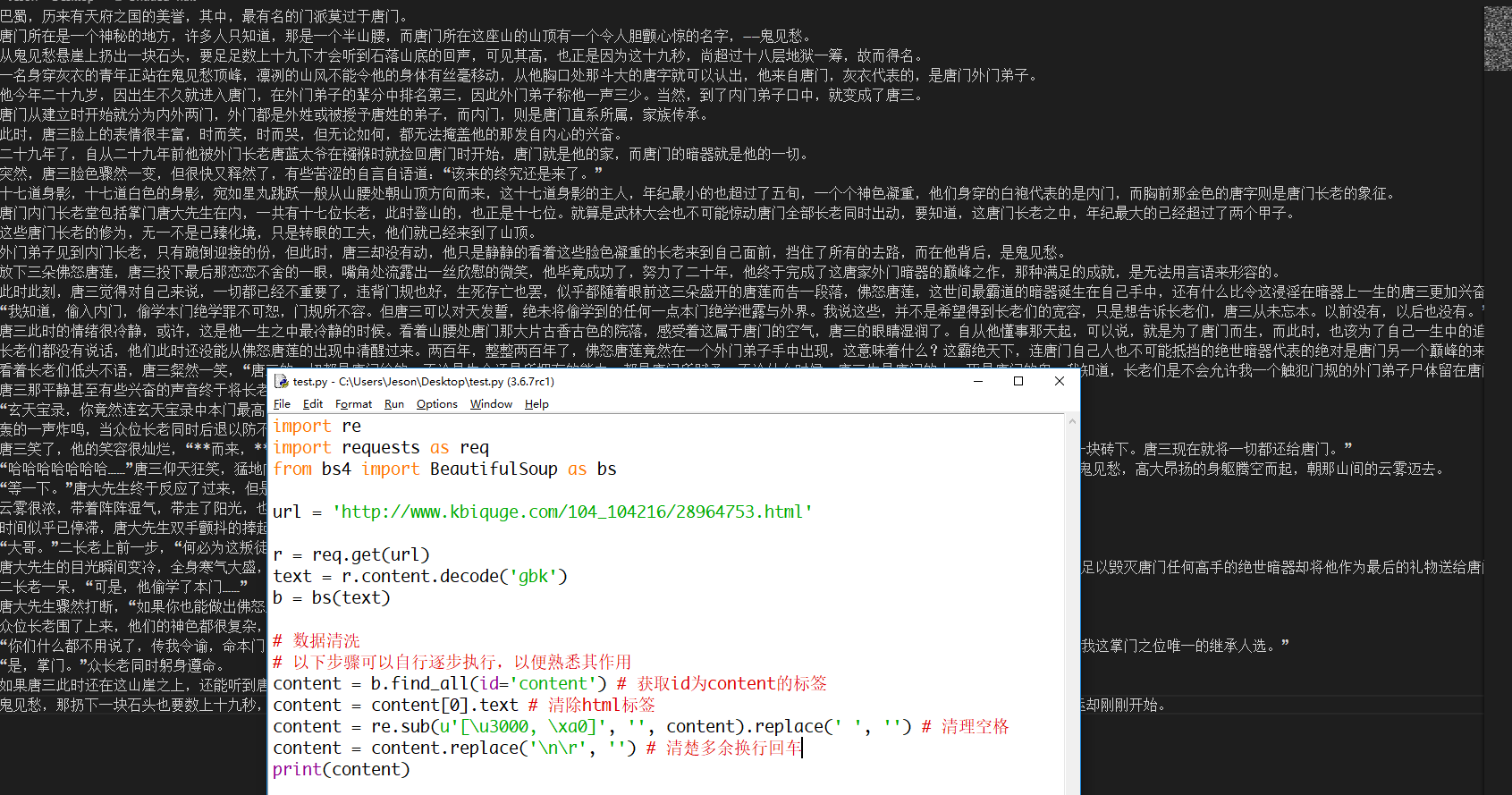
图三
代码结合如下
1 import re 2 import requests as req 3 from bs4 import BeautifulSoup as bs 4 5 url = 'http://www.kbiquge.com/104_104216/28964753.html' 6 7 r = req.get(url) 8 text = r.content.decode('gbk') # 防止中文乱码 9 b = bs(text) 10 11 # 获取标题并截取 12 title = b.find_all('h1')[0].text[1:] 13 14 # 数据清洗 15 # 以下步骤可以自行逐步执行,以便熟悉其作用 16 content = b.find_all(id='content') # 获取id为content的标签 17 content = content[0].text # 清除html标签 18 content = re.sub(u'[\u3000, \xa0]', '', content).replace(' ', '') # 清理空格 19 content = content.replace('\n\r', '') # 清楚多余换行回车 20 21 # 整合 22 content = title + '\n' + content +'\n\n' # 将标题和内容整合
接下来我们来看看 目录
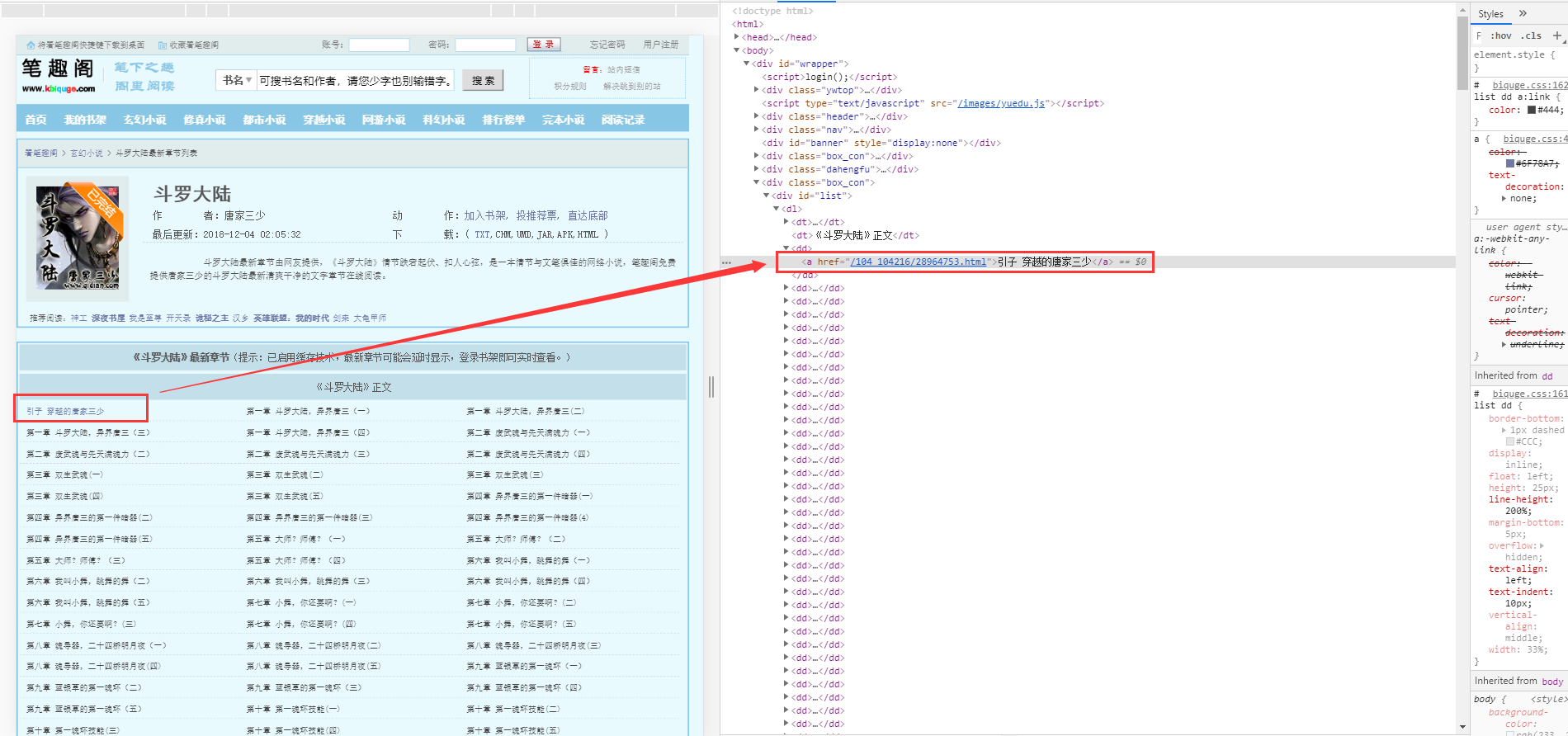
图四
目录这里我采用正则的方式获取标题和 url(详情了解可以查看文档)
1 import re 2 import requests as req 3 from bs4 import BeautifulSoup as bs 4 5 list_url = 'http://www.kbiquge.com/104_104216/' 6 r = req.get(list_url) 7 b = bs(r.content.decode('gbk')) 8 text = b.find_all(href=re.compile('/104_104216/')) # 使用正则的方式获取链接列表 9 for each in text: # 遍历列表打印查看 10 print(each.string + ' ' + each.get('href'))
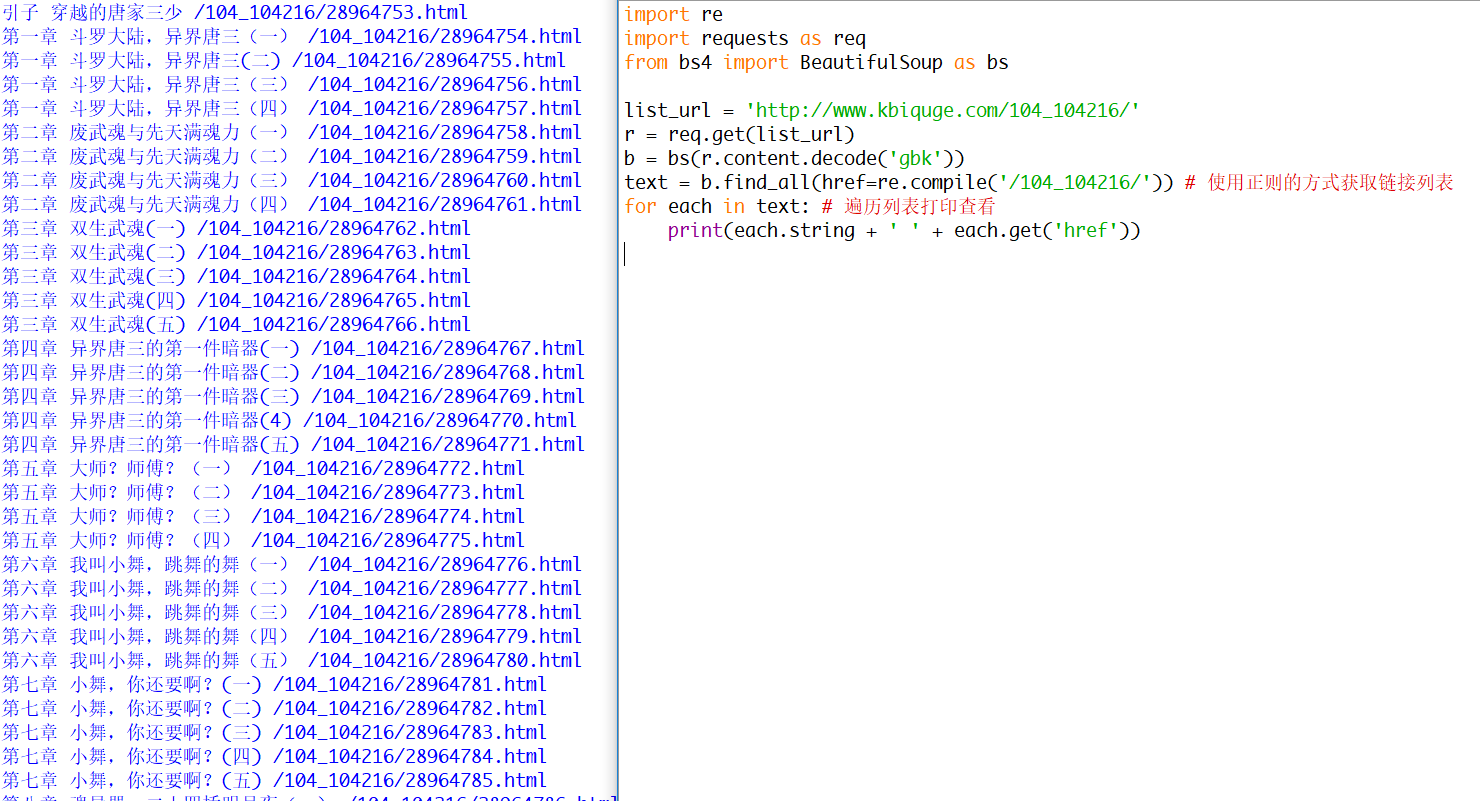
图五
基本上就这么多。接下来就是依次获取目录 URL 然后再下载每章小说即可。
关于章节 URL 问题,可能有人会说应该都是有序的,仔细观察可能发现有非连续的。故依次获取即可
编码
1 import re 2 import requests 3 from bs4 import BeautifulSoup 4 5 list_url = 'http://www.kbiquge.com/104_104216/' 6 7 r = requests.get(list_url) 8 b = BeautifulSoup(r.content.decode('gbk')) 9 t = b.find_all(href = re.compile('/104_104216/')) 10 list_len = len(t) 11 i = 1 12 print('Strat Download:') 13 for each in t: 14 print('正在下载第' + str(i) + '章,共' + str(list_len) + '章') 15 url = list_url + each.get('href')[12:] 16 r = requests.get(url) 17 b = BeautifulSoup(r.content.decode('gbk')) 18 19 # 获取标题并截取 20 title = b.find_all('h1')[0].text[1:] 21 22 # 数据清洗 23 content = b.find_all(id='content')[0].text # 清除html标签 24 content = re.sub(u'[\u3000, \xa0]', '', content).replace(' ', '').replace('\n\r', '') 25 content = title + '\n' + content +'\n\n' # 将标题和内容整合 26 with open('斗罗大陆.txt', 'a', encoding='utf-8') as f: 27 f.write(content) 28 i = i+1 29 print('Download successful!')
