
如何提升大模型的Agent推理规划等能力?
参考地址:https://mp.weixin.qq.com/s/0qkMbzlU9ks6DNS5MBiU8g
论文地址:
(1)cot:https://arxiv.org/pdf/2201.11903.pdf
(2)tot:https://arxiv.org/pdf/2305.10601.pdf
(3)react:https://arxiv.org/pdf/2210.03629.pdf
(4)reflexion:https://arxiv.org/pdf/2303.11366.pdf
(5)agent tuning:https://arxiv.org/pdf/2310.12823.pdf
(6)fireact:https://arxiv.org/pdf/2310.05915.pdf
(7)agentFlan:https://arxiv.org/pdf/2403.12881.pdf
(8)knowagent:https://arxiv.org/pdf/2403.03101.pdf
(9)autoact:https://arxiv.org/pdf/2401.05268.pdf
(10)Travel Plan:https://arxiv.org/pdf/2402.01622.pdf
特别说明:本文章仅作为个人笔记使用。
1、COT(思维链)
将推理过程添加到Prompt中,能很大幅度的提升推理能力。
2、TOT(思维树)
在Prompt工程中进行如下设置:
假设三位不同的专家来回答这个问题。所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。然后,所有专家都写下他们思考的下一个步骤并分享。以此类推,直到所有专家写完他们思考的所有步骤。只要大家发现有专家的步骤出错了,就让这位专家离开。请问..
3、ReAct(Reason And Act)
既思考又行动,这里的Reason就是指的思维链推理过程,Action指的是不同场景下采取的动作,跟环境紧密相关。
Prompt流程:
想法:...
行动:...
观察(重复多次):...
4、Reflexion:Verbal强化学习
在ReAct的基础之上,专门增加一个Evaluator进行reward的打分,等价于强化学习中的环境奖励。使用交互轨迹和奖励进行综合反思。
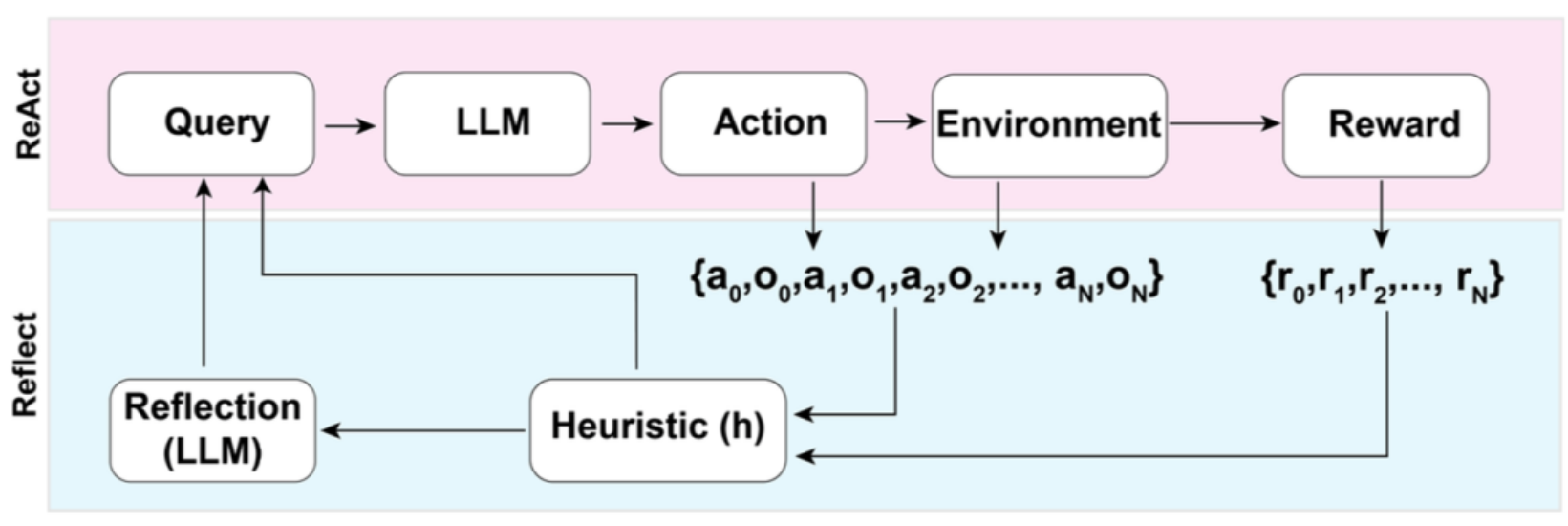
5、AgentTuning:多任务微调Agent
通过构建一个轻量级的指令调整数据集AgentInstruct,并采用混合指令调整策略,结合AgentInstruct和开源通用指令进行微调,从而在不损害LLMs的一般能力的情况下增强其代理能力。
6、FireACT:对话路径多样性
也是通过微调的方式提升大模型的Agent的能力,只不过数据的形式有了些新的思考:不同思维框架如COT、React、Reflexion等的数据格式混合能提升多样性。
7、AgentFLAN:数据构造与预训练一致性
8、KnowAgent:动作知识库增强
它通过结合明确的行动知识来解决LLMs在与环境交互时生成可执行行动的复杂推理任务中的不足,特别是在任务解决过程中规划轨迹的指导不足,导致规划幻觉问题。
具体来说KNOWAGENT利用行动知识库来约束规划过程中的行动路径,通过将行动知识转换为文本,使模型能够更深入地理解和利用这些知识来创建行动轨迹。最后,通过知识型自学习阶段,使用模型迭代过程中开发的轨迹来不断改进其对行动知识的理解及其应用即迭代式SFT。
总结来说也是一篇关于数据的工作,只不过,框架从多轮轨迹的优化增加到类似RAG的思路,将动作知识库转化为文本融入模型微调过程中去。
什么是动作知识库?
动作知识库(Action Knowledge Base, AKm)是KNOWAGENT框架中的一个关键组成部分,它定义了一组特定的动作(Ea)以及管理这些动作转换的规则(R)。这些动作和规则构成了一个结构化的知识体系,用于指导语言模型在执行任务时生成合理的行动轨迹。
以下是一个简化的动作知识库案例,用于解释其结构和应用:
(1)动作集合 (Ea):
Search: 搜索相关信息或数据。
Retrieve: 检索特定的信息或实体。
Lookup: 在已知信息中查找特定关键词或数据。
Finish: 完成任务并输出结果。
(2)动作规则 (R):
Rule 1 (Search -> Retrieve): 如果当前动作是Search,下一个合法的行动可以是Retrieve,表示在搜索后找到一个具体实体。
Rule 2 (Search -> Lookup): 从Search动作可以转换到Lookup,表示在搜索过程中需要查找特定关键词。
Rule 3 (Retrieve -> Finish): 如果Retrieve动作成功,可以接着执行Finish动作,表示检索到所需信息后完成任务。
Rule 4 (Lookup -> Finish): 如果Lookup动作找到了所需答案,可以直接执行Finish动作结束任务。
动作知识库应用案例:
假设我们有一个多跳问答任务,需要回答“华盛顿特区最大的私立医院是儿童国家医疗中心还是MedStar华盛顿医院中心?”这个问题。
Start: 初始状态,模型需要确定如何获取答案。
Search: 模型执行Search动作,搜索“华盛顿特区私立医院”相关信息。
Retrieve: 根据Search结果,模型执行Retrieve动作,找到“儿童国家医疗中心”和“MedStar华盛顿医院中心”的具体信息。
Lookup: 模型在检索到的信息中执行Lookup动作,查找两个医院的规模比较。
Finish: 一旦模型通过Lookup动作确定了哪个医院更大,就执行Finish动作,输出最终答案并结束任务。
在这个案例中,动作知识库确保了模型在规划和执行任务时遵循逻辑和顺序,避免了不合理的行动序列,
如直接从Search跳到Finish而忽略了中间的检索和查找步骤。通过这种方式,动作知识库有助于提高模型在复杂任务中的性能和准确性。
9、AutoAct:MultiAgent
前面的这些工作,不同prompt框架,不同agent finetuning的方法,基本都是建立在一个模型完成所有的agent任务的目标去的。这篇论文则考虑到了多智能体的思路。并且给出了一个表格对比他所拥有的能力范围,自然是比较全面的选手,只不过Generality和Reflection都没那么值得去说,这里比较的重点应该是多智能体的提出。怎么进行多代理协作等应该比较被关注?
数据和轨迹获取是指获取训练数据和轨迹的方法。计划代表了计划的方式,根据每个步骤的行动是由全局还是迭代决定的。多Agent表示该框架是否包含多个Agent。精细调整表示该方法是否是一个基于微调的Agent学习框架。通用性表示方法是否适用于各种任务。反射表示计划过程是否包含反射。
多代理协作的一个具体案例可以通过以下步骤实现:
(1)任务定义:
假设我们有一个多跳问答任务(例如HotpotQA),其中问题需要通过多个步骤和推理来解答。例如,问题可能是:“在《傲慢与偏见》中,达西先生的庄园位于英格兰德比郡的什么地方?”答案应该是“彭伯里”。
(2)自我规划:
元代理(META-AGENT)首先通过自我指导(Self-Instruct)生成一组初始的问答对,这些问答对作为训练数据。然后,元代理利用工具库(Tool Library)中的信息自动选择适合的工具,比如搜索引擎、知识检索工具等。
(3)规划轨迹合成:
元代理使用选定的工具来自动生成规划轨迹,这些轨迹包含了一系列的思考(Thought)、行动(Action)和观察(Observation)记录。例如,元代理可能会生成一个轨迹,其中包含使用搜索引擎查找与“达西先生”和“彭伯里”相关的信息,然后从搜索结果中提取答案。
(4)自我分化:
根据合成的规划轨迹,元代理分化成三个子代理:
计划代理(Plan-Agent)决定下一步的行动计划。
工具代理(Tool-Agent)根据计划代理的指示调用搜索引擎,并提供必要的参数(如搜索查询)。
反思代理(Reflect-Agent)评估行动的结果,并确定是否需要进一步的行动或已经找到了正确答案。
(5)微调实现:
对于每个子代理,使用特定的LoRA(Low-Rank Adaptation)模型进行微调。微调过程中,每个子代理都会针对其特定的任务和责任进行训练,以便更有效地执行其功能。例如,计划代理可能会被训练来更好地理解问题和上下文,以便制定有效的行动计划;工具代理可能会被训练来更准确地调用和使用外部工具;反思代理可能会被训练来更好地评估答案的正确性。
(6)群体规划:
在实际的推理过程中,这些子代理会协作完成任务。计划代理提出行动计划,工具代理执行计划中的工具调用,反思代理评估结果并提供反馈。这个协作过程可能需要多轮迭代,直到找到满意的答案。
通过这种方式,AUTOACT框架能够实现多代理之间的有效协作,每个代理都在其专业领域内进行微调,以提高整体任务的执行效率和准确性。这种方法允许每个代理专注于其特定的任务,而不是将所有任务都放在一个单一的模型中处理,从而提高了系统的灵活性和可扩展性。
本质上还是拆解任务,做更好的数据处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号