
对transformer里attention和mlp机制的直观具象理解笔记
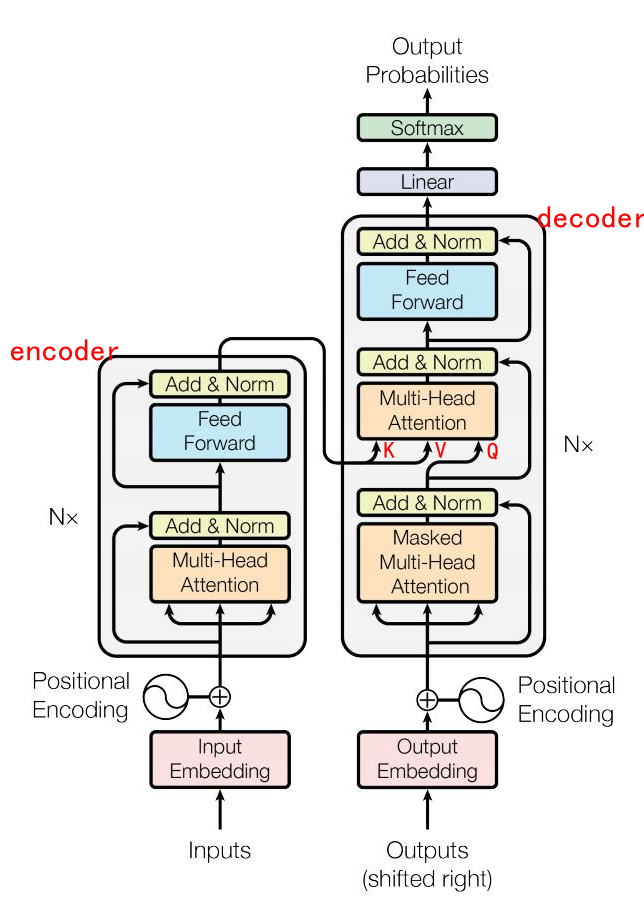
在实际的大模型中,多个Transformer结构(层)是串联(堆叠)起来的,每一层都站在前一层“巨人”的肩膀上,使得模型对信息的理解越来越深入和精准。在2017年的原始Transformer论文中,编码器和解码器各使用了6层。
图中 Multi-Head Attention就是注意力层。
Feed Forward是FFN,又名 MLP 层
|
标注名称 |
代表含义 |
在训练阶段的作用 |
在推理(预测)阶段的作用 |
|---|---|---|---|
|
Inputs |
编码器的输入,即源语言序列(如待翻译的英文句子) |
提供给编码器进行编码,生成包含源序列信息的上下文向量。
|
同训练阶段,作为编码器的输入。 |
|
Outputs (shifted right) |
解码器的输入,是目标语言序列向右偏移一位后,并在开头添加了 |
作为解码器的输入,防止模型在训练时“偷看”未来答案,实现并行训练的同时保证自回归特性。
|
不存在。解码器的输入是模型自己上一个时间步生成的结果,并逐步拼接而成。
|
|
Output Probabilities |
解码器的输出,即模型预测的下一个词的概率分布 |
与真实的下一个词计算损失(如交叉熵),用于更新模型参数。
|
根据此概率分布选择下一个词(贪婪搜索或集束搜索),并将选定的词作为下一时间步的输入,循环直至生成结束标记。
|
|
特性 |
编码器 (Encoder) |
解码器 (Decoder) |
|---|---|---|
|
核心任务 |
理解与编码:提取输入序列的全局特征,生成富含上下文信息的表示
|
生成与构建:基于编码器输出和已生成内容,自回归地生成目标序列
|
|
输入来源 |
上一编码器层的输出(首层为词嵌入 + 位置编码)
|
1. 上一解码器层的输出(首层为目标序列嵌入 + 位置编码)
|
|
内部子层 |
1. 多头自注意力层 (Self-Attention)
|
1. 掩码多头自注意力层 (Masked Self-Attention)
|
|
注意力机制 |
自注意力:Query, Key, Value均来自同一输入序列(编码器自身的前一层输出)
|
1. 掩码自注意力:Query, Key, Value均来自解码器自身已生成部分
|
|
掩码应用 |
通常无需掩码(或仅需填充掩码),可看到完整输入序列
|
必须使用因果掩码(Causal Mask),确保生成时只能看到当前位置及之前的信息,防止未来信息泄露
|
|
信息依赖 |
仅依赖源序列自身的信息
|
同时依赖已生成的目标序列和编码器提供的源序列信息
|
|
并行化 |
完全并行:可同时处理整个输入序列的所有位置
|
训练时可并行(通过掩码模拟自回归,但输入是完整的右移目标序列)
|
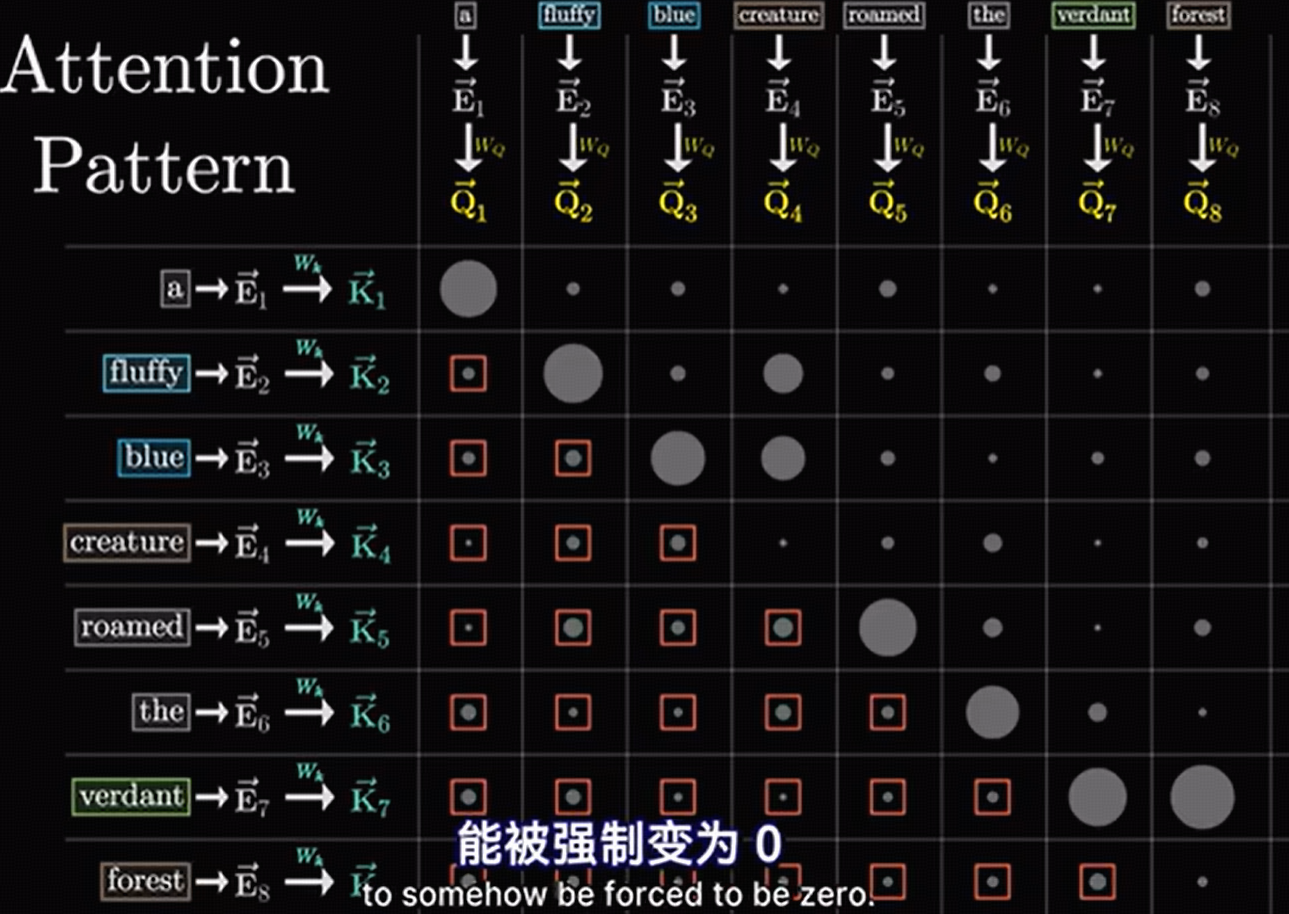
attention部分:
https://www.bilibili.com/video/BV1TZ421j7Ke
输入问题:1+2=?
假设模型:
忽略编码方式,简单认为有5个token。N=5
每个token都是一个1024维度的向量,1024 = d_model(也称为隐藏层维度)
输入X = 5行,1024列。
-
Query(Q):用来表示当前正在关注的 token 的“查询意图” —— 它想知道其他 token 跟它有多相关。后续谁将与我有联系 我找谁?
-
Key(K):用来表示其他 token 的“身份标识” —— 它告诉别人“我是谁,跟 Query 有多匹配”。之前我会和谁有联系 谁找我?
-
Value(V):才是真正承载了“信息内容”的向量 —— 一旦通过 Q 和 K 计算出注意力权重后,这些权重会被用在 V 上进行加权求和,从而得到该位置最终的输出表示。联系上之后,我们会有哪种关系, 匹配后有啥事儿?
假设模型是单头注意力的:
Wq = 1024 * 1024
Wk = 1024*1024
Wv = 1024 * 1024
Q = X * Wq 5行1024列
K = X*Wk 5行1024列
V= X*Wv 5行1024列 ,X虽然还是5行1024列,但是Wv给X注入了大模型自身的更多信息,而不是原来的赤条条的X
WQ * WK的转置 = 前后token匹配关系,归一化和softmax修饰数据。 5行5列
前后token匹配关系 * V,用匹配关系筛选V,完成信息筛选。 5行1024列

=====================================================================================================================
MLP部分:
MLP层输入[batch_size, seq_len, d_model],输出 [batch_size, seq_len, d_model])。

在Transformer结构中,经过自注意力(Self-Attention)层处理后,每个token的表示向量会独立地输入到后续的多层感知机(MLP,也称为前馈神经网络,FFN)中进行计算。
前边的Linear矩阵乘计算,向量E从权重W0里取得了某些信息,经过relu过滤出匹配度最佳的。
后边的矩阵乘,E又从W1里取出了某些信息,完成整个信息筛选。
举个例子
假设序列是["猫", "喜欢", "吃"],经过注意力层后,每个词都包含了整个序列的上下文信息(例如“吃”这个词的表示已经知道主语是“猫”)。
1.
这些表示(每个都是 d_model维的向量)会独立地输入到MLP中。
2.
MLP会对它们进行相同的权重计算(例如先扩展到 4*d_model维,经过激活函数,再压缩回 d_model维)。
3.
输出仍然是三个向量(形状 [1, 3, d_model]),但每个向量都包含了经过非线性变换的、更丰富的特征信息。
4.
最后,取最后一个token(“吃”)的输出向量,并将其映射到词表上,模型可能会计算出“鱼”的概率很高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号