
一.选题的背景
豆瓣电影网对世界知名电影都进行了排行,主要是根据观众们对这部电影的评价的高低来对电影进行等级排序,而我想观测电影的评价分数和评价人数两者那个对电影的等级影响更大。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
《Python爬虫对豆瓣Top250电影网的数据爬取以及分析》
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:豆瓣Top250
3.主题是网络爬虫设计方案概述
实现思路:在浏览器 中通过F12访问网页源代码,,分析网站源代码,找到自己所需要的数据所在的位置,提取数据,对数据进行保存到相同路径csv文件中,读取改文件,进行数据清洗,数据模型分析,数据可视化处理,绘制分布图,直方图,散点图。
技术难点:对库使用和库中函数的运用,爬取的内容的机构分析处理做数据分析,即求回归系数。由于不明原因,输出结果经常会显示超出列表范围。
三、主题页面的结构特种分析
1.对豆瓣网页面进行结构与特征分析:先找到豆瓣Top250的网址,然后找出电影的评级,图片。电影名,电影简介,电影人员介绍,等信息的标签,并对其进行准确的提取。
2.页面分析。
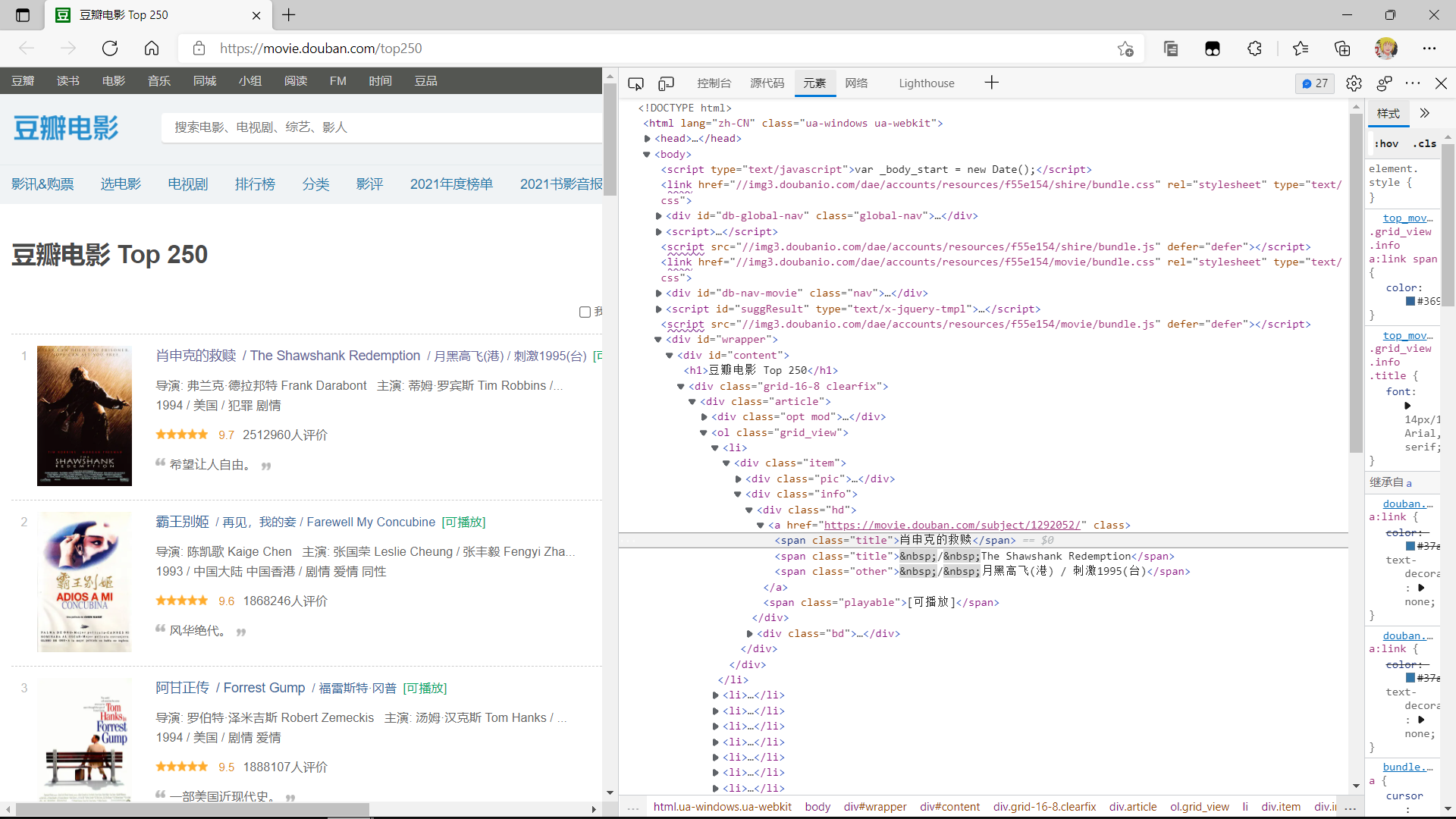
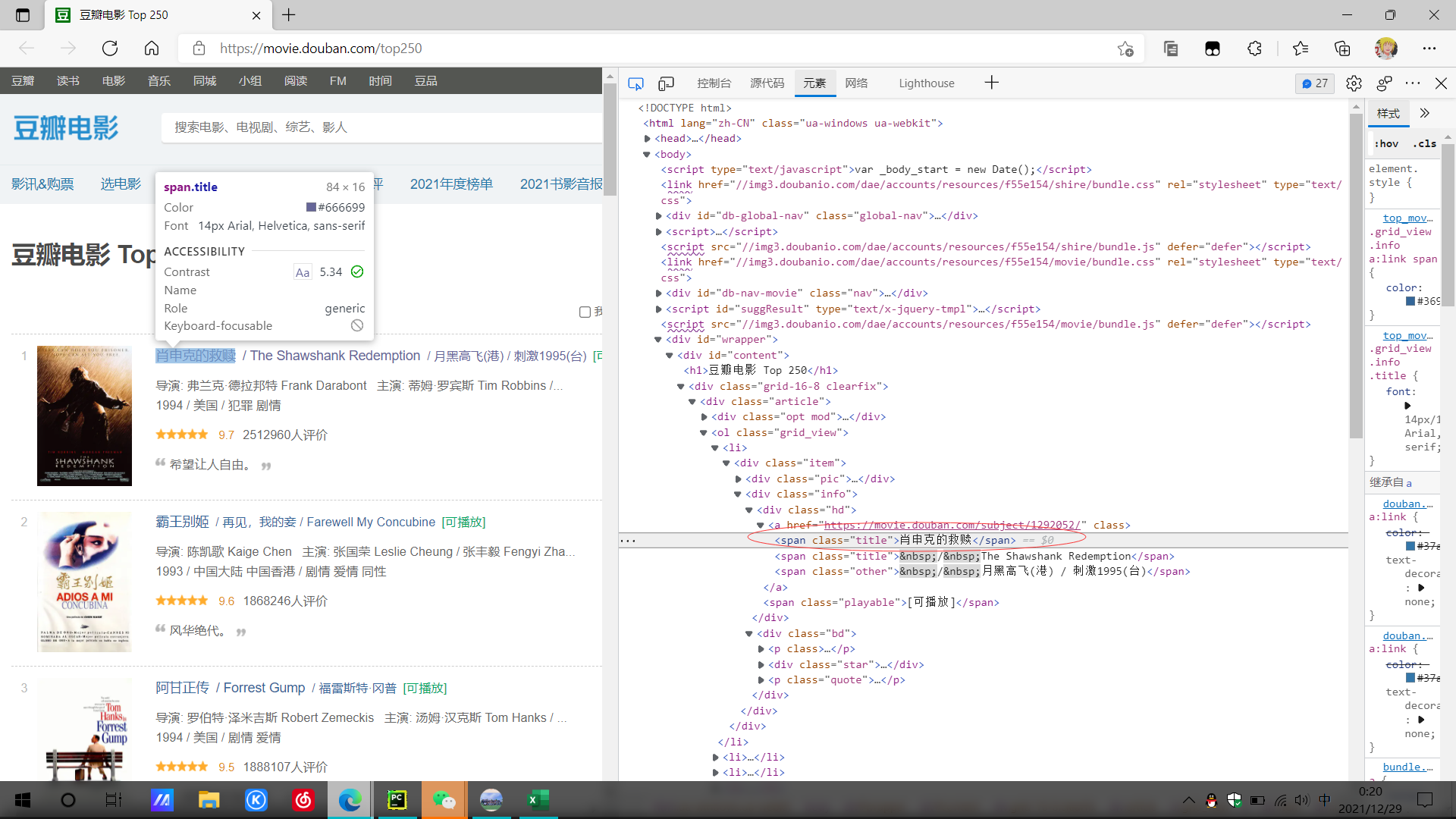
抓取自己所需要的标签,
1 from bs4 import BeautifulSoup #网页解析获取数据 2 import urllib.request #制定url。获取网页数据 3 import urllib.error 4 import re #正侧表达式un,进行文字匹配 5 import xlwt #进行excel操作 6 import sqlite3 #进行sqlit数据库操作 7 import pandas as np 8 qw=[] #定义空的表,用于存放数据。 9 we=[] 10 er=[] 11 rt=[] 12 ty=[] 13 yu=[] 14 15 def askURL(url): 16 #头 17 cookie = 'll="118204"; bid=G42QcJoRaWE; _vwo_uuid_v2=D97D607CF35477ACD7007818FB3693D61|29f3ddbf9989fb63a5ddb2567bbbc83a; __gads=ID=f5bf17d7797239d3-227aa9128ecf00d2:T=1640588801:RT=1640588801:S=ALNI_MYBWT9GYs91XjGmv6vlZ7qGL3ht_Q; __yadk_uid=wX9wcwzazXO3XN9AFd60eUUl7x7b9bjo; __utmz=30149280.1640614862.5.5.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmz=223695111.1640614862.4.4.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1640667200%2C%22https%3A%2F%2Fcn.bing.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.1607185886.1640317225.1640665257.1640667200.7; __utma=223695111.1200427924.1640531148.1640665257.1640667200.6; __utmb=223695111.0.10.1640667200; Hm_lvt_16a14f3002af32bf3a75dfe352478639=1640610451,1640668363; __utmc=30149280; __utmc=223695111; ap_v=0,6.0; __utmt=1; __utmb=30149280.4.10.1640667200; _pk_id.100001.4cf6=af16e508012adde8.1640531148.6.1640673421.1640665257.' 18 head={ 19 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62", 20 "Cookie": cookie.encode("utf-8").decode("latin1")} 21 22 request=urllib.request.Request(url,headers=head) 23 try: 24 response=urllib.request.urlopen(request) 25 html = response.read().decode("utf-8") 26 return html 27 except urllib.error.URLError as e: 28 if hasattr(e,"code"): 29 print(e.code) 30 elif hasattr(e,"reason"):
31 print(e.reason) 32 #2.解析数据 33 o = 1 34 for i in range(0,10): #调用获取页面信息的函数 35 url=f"https://movie.douban.com/top250?start={i*25}&filter="#对10页网页进行依次爬取 36 html=askURL(url) 37 soup=BeautifulSoup(html,'html.parser') 38 39 # 影片评价人数 40 findJudge=soup.find_all('div',{'class':'star'}) 41 for i in findJudge: 42 people=i.string 43 # < span > 2512760人评价 < / span > 44 k=re.findall(r'(\d*?)人评价',str(i))[0] 45 qw.append(k) 46 print(k) 47 # 影片评分 48 findRating=soup.find_all('span',{'class':'rating_num'}) 49 for i in findRating: 50 z=i.string 51 we.append(z) 52 print(z) 53 54 # 影片标题 55 findTitle =soup.find_all('span',{'class':'title'}) 56 for i in findTitle : 57 if " / " in str(i): #只爬取电影的中文名称 58 continue 59 d=i.string 60 er.append(d) 61 print(d) 62 # 影片详情链接 63 findLink =soup.find_all('div',{'class':'hd'}) 64 for i in findLink : 65 b=i.select('a')[0].get('href') 66 rt.append(b) 67 print(b) 68 69 # 影片相关内容 70 findInq=soup.find_all('div',{'class':'bd'})[1:] 71 for i in findInq: 72 y=i.select('p')[0].get_text() 73 ty.append(y) 74 print(y) 75 # 影片图片 76 findImgSrc=soup.find_all('div',{'class':'pic'}) 77 for i in findImgSrc: 78 q=i.select('img')[0].get('src') 79 request = urllib.request.Request(q) 80 response = urllib.request.urlopen(request) 81 html = response.read() 82 with open(f'.//img/{o}.jpq', "wb") as f: 83 # 写文件用bytes而不是str,所以要转码 84 f.write(html) 85 o += 1 86 #实o每次加以以达到换页的效果 87 88 # print(len(qw)) 89 # print(len(we)) 90 # print(len(er)) 91 # print(len(rt)) 92 # print(len(ty)) 93 #测试文本数量是否一致
2.保存数据
1 u=[]#建立一个空的列表用于存放数据 2 df = np.DataFrame(data=[qw,we,er,rt,ty],index=['评论人数','评分','电影名','超链接','电影人员介绍'])#将数据保存到列表中 3 df2=np.DataFrame(df.values.T,columns=df.index)#对文本进行,行换列,列换行 4 df2.to_excel('qq.xlsx')#保存数据到xlsx文件中
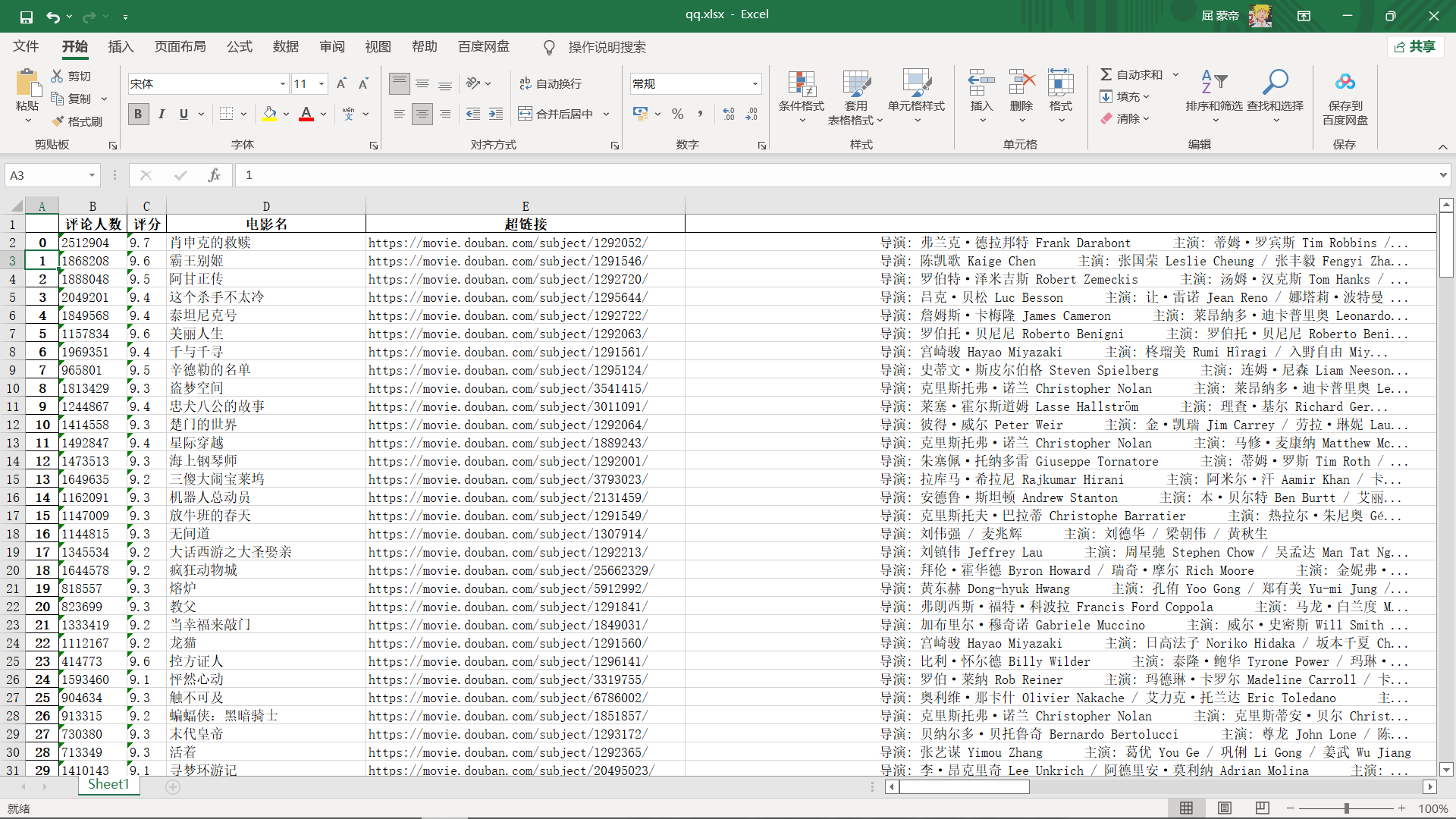
3.数据可视化
1 import pandas as pd 2 from pyecharts.charts import Bar 3 from pyecharts.faker import Faker 4 from pyecharts.globals import ThemeType 5 from pyecharts.charts import Bar 6 from pyecharts.options import global_options as opts 7 #导入所需的库 8 df=pd.read_excel('qq.xlsx')#导入数据 9 a=df['评分'].values.tolist()[:250] 10 b=df['电影名'].values.tolist()[:250] 11 s=df['评论人数'].values.tolist()[:250]
1 #——————————————————————————————————————评价等级可视化———————————————————————————————————————————————————————————— 2 c = ( 3 Bar({"theme": ThemeType.MACARONS}) 4 .add_xaxis(b) 5 .add_yaxis("评分",a) 6 # .add_yaxis("评论人数",s) 7 .set_global_opts( 8 title_opts={"text": "Bar-通过 dict 进行配置", "subtext": "我也是通过 dict 进行配置的"} 9 10 ) 11 .set_global_opts(title_opts=opts.TitleOpts(), 12 datazoom_opts=opts.DataZoomOpts(),#分段 13 xaxis_opts=opts.AxisOpts(name_rotate=60, name="电影名", axislabel_opts={"rotate": 35})#字体倾斜角度 14 ) 15 16 .render("评级.html") 17 )


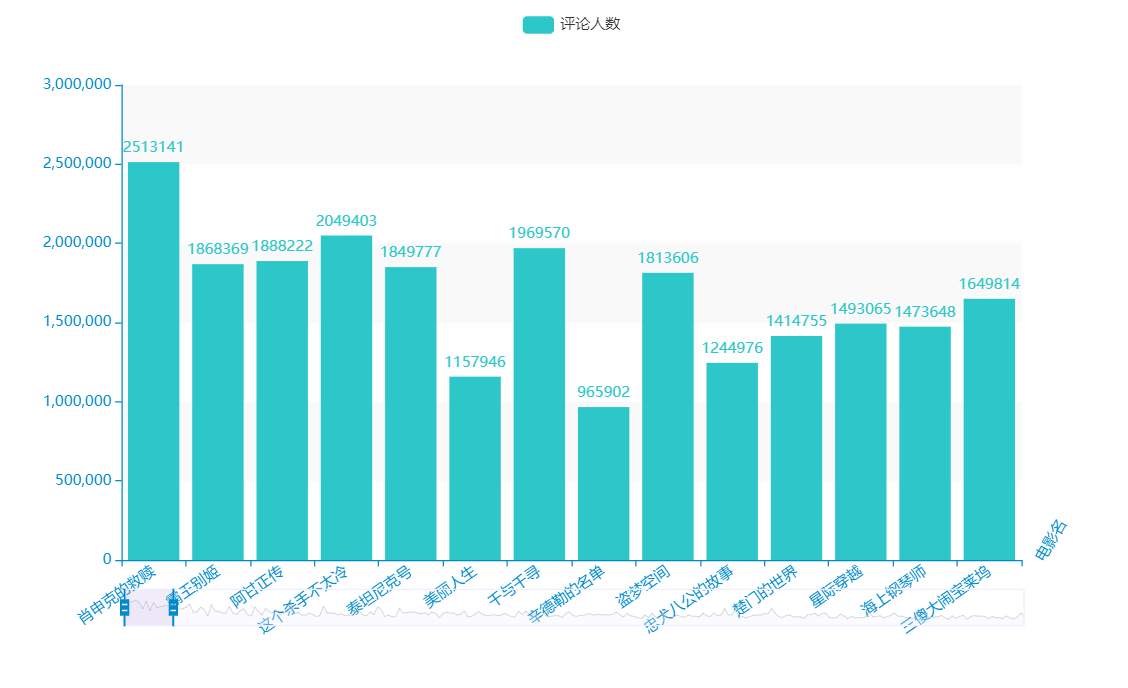
1 #————————————————————————————————————评价人数可视化—————————————————————————————————————————————————————————————— 2 3 c = ( 4 Bar({"theme": ThemeType.MACARONS}) 5 .add_xaxis(b) 6 # .add_yaxis("评分",a) 7 .add_yaxis("评论人数",s) 8 .set_global_opts( 9 title_opts={"text": "Bar-通过 dict 进行配置", "subtext": "我也是通过 dict 进行配置的"} 10 11 ) 12 .set_global_opts(title_opts=opts.TitleOpts(), 13 datazoom_opts=opts.DataZoomOpts(),#分段 14 xaxis_opts=opts.AxisOpts(name_rotate=60, name="电影名", axislabel_opts={"rotate": 35})#字体倾斜角度 15 ) 16 17 .render("评价人数.html") 18 )
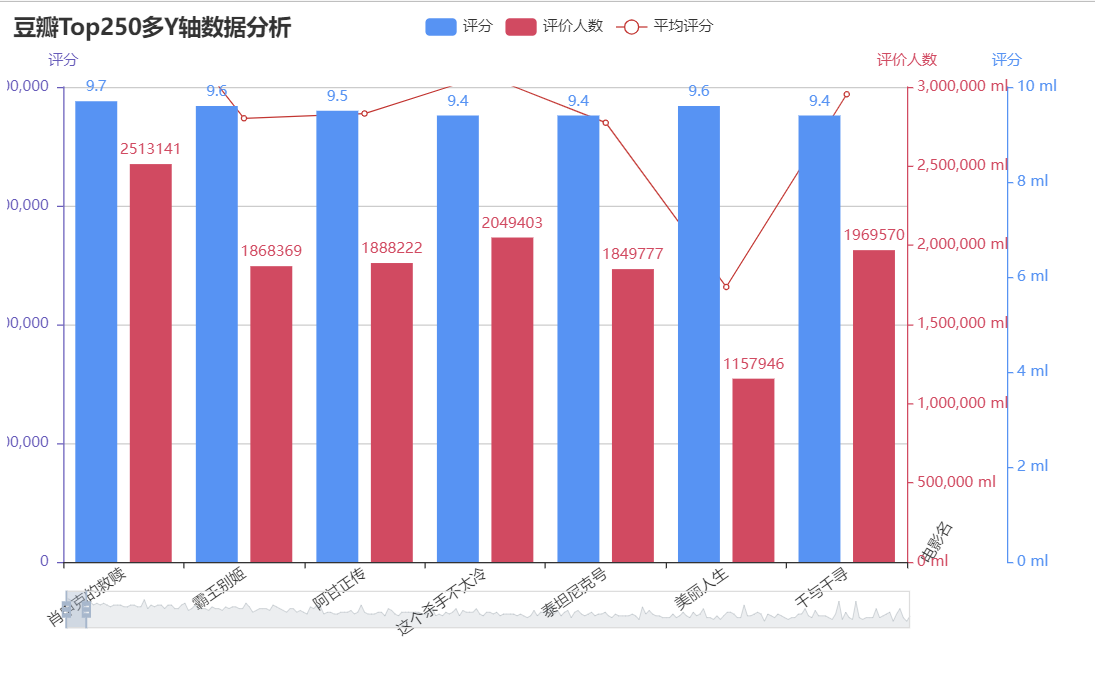
1 from pyecharts import options as opts 2 from pyecharts.charts import Bar, Grid, Line 3 import pandas as pd 4 from matplotlib import pyplot as plt 5 import numpy as np 6 7 df=pd.read_excel('qq.xlsx')#导入数据 8 b=df['电影名'].values.tolist()[:250] 9 a=df['评分'].values.tolist()[:250] 10 s=df['评论人数'].values.tolist()[:250] 11 12 bar = ( 13 Bar() 14 .add_xaxis(b) 15 .add_yaxis( 16 "评分", 17 a, 18 yaxis_index=0, 19 color="#d14a61", 20 ) 21 .add_yaxis( 22 "评价人数", 23 s, 24 yaxis_index=1, 25 color="#5793f3", 26 ) 27 .extend_axis( 28 yaxis=opts.AxisOpts( 29 name="评价人数", 30 type_="value", 31 min_=0, 32 max_=3000000, 33 position="right", 34 axisline_opts=opts.AxisLineOpts( 35 linestyle_opts=opts.LineStyleOpts(color="#d14a61") 36 ), 37 axislabel_opts=opts.LabelOpts(formatter="{value} ml"), 38 ) 39 ) 40 .extend_axis( 41 yaxis=opts.AxisOpts( 42 type_="value", 43 name="评分", 44 min_=0, 45 max_=2000000, 46 position="left", 47 axisline_opts=opts.AxisLineOpts( 48 linestyle_opts=opts.LineStyleOpts(color="#675bba") 49 ), 50 axislabel_opts=opts.LabelOpts(formatter="{value} "), 51 splitline_opts=opts.SplitLineOpts( 52 is_show=True, linestyle_opts=opts.LineStyleOpts(opacity=1) 53 ), 54 ) 55 ) 56 .set_global_opts( 57 yaxis_opts=opts.AxisOpts( 58 name="评分", 59 min_=0, 60 max_=10, 61 position="right", 62 offset=80, 63 axisline_opts=opts.AxisLineOpts( 64 linestyle_opts=opts.LineStyleOpts(color="#5793f3") 65 ), 66 axislabel_opts=opts.LabelOpts(formatter="{value} ml"), 67 ), 68 title_opts=opts.TitleOpts(title="豆瓣Top250多Y轴数据分析"), 69 tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"), 70 datazoom_opts=opts.DataZoomOpts(), # 分段 71 xaxis_opts=opts.AxisOpts(name_rotate=60, name="电影名", axislabel_opts={"rotate": 35}) # 字体倾斜角度 72 ) 73 ) 74 75 line = ( 76 Line() 77 .add_xaxis(b) 78 .add_yaxis( 79 "平均评分", 80 s, 81 yaxis_index=2, 82 color="#675bba", 83 label_opts=opts.LabelOpts(is_show=False), 84 ) 85 )
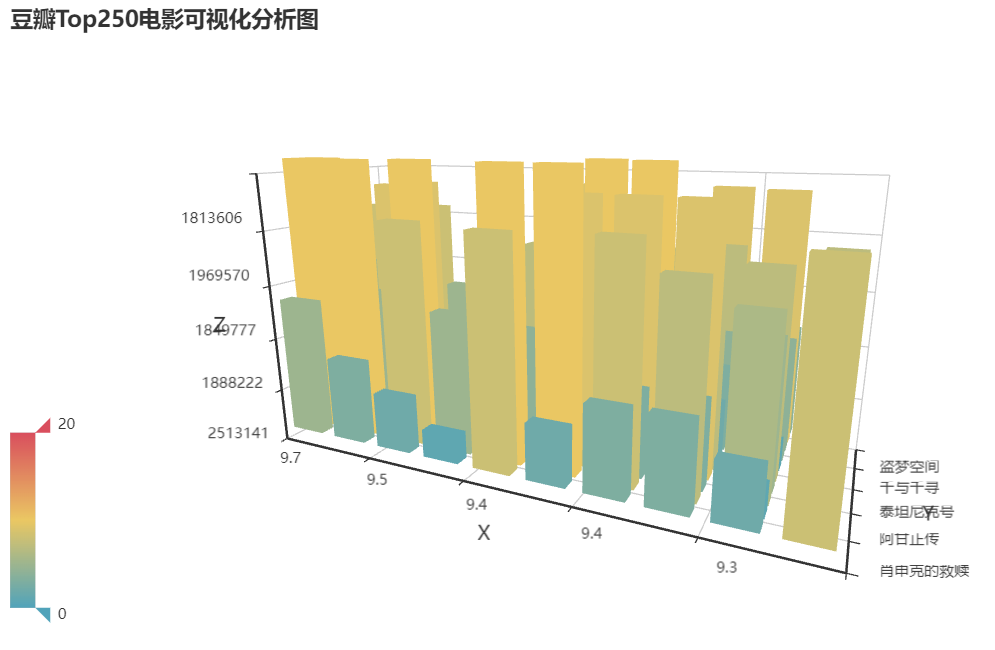
1 import random 2 import pandas as pd 3 from pyecharts import options as opts 4 from pyecharts.charts import Bar3D 5 from pyecharts.faker import Faker 6 7 #导入所需的库 8 df=pd.read_excel('qq.xlsx')#导入数据 9 a=df['评分'].values.tolist()[:10] 10 b=df['电影名'].values.tolist()[:10] 11 s=df['评论人数'].values.tolist()[:10] 12 data = [(i, j, random.randint(0, 10)) for i in range(10) for j in range(10)] 13 c = ( 14 Bar3D() 15 .add( 16 "", 17 [[d[1], d[0], d[2]] for d in data], 18 xaxis3d_opts=opts.Axis3DOpts(a), 19 yaxis3d_opts=opts.Axis3DOpts(b), 20 zaxis3d_opts=opts.Axis3DOpts(s), 21 ) 22 .set_global_opts( 23 visualmap_opts=opts.VisualMapOpts(max_=20), 24 title_opts=opts.TitleOpts(title="豆瓣Top250电影可视化分析图"), 25 ) 26 .render("bar3d_base.html") 27 )
四 、完整代码
1 from bs4 import BeautifulSoup #网页解析获取数据 2 import urllib.request #制定url。获取网页数据 3 import urllib.error 4 import re #正侧表达式un,进行文字匹配 5 from pyecharts.charts import Bar, Grid, Line 6 import pandas as pd 7 from pyecharts import options as opts 8 from pyecharts.charts import Bar3D 9 from pyecharts.globals import ThemeType 10 from pyecharts.charts import Bar 11 import random 12 import xlwt #进行excel操作 13 import sqlite3 #进行sqlit数据库操作 14 import pandas as np 15 qw=[] #定义空的表,用于存放数据。 16 we=[] 17 er=[] 18 rt=[] 19 ty=[] 20 yu=[] 21 22 def askURL(url): 23 #头 24 cookie = 'll="118204"; bid=G42QcJoRaWE; _vwo_uuid_v2=D97D607CF35477ACD7007818FB3693D61|29f3ddbf9989fb63a5ddb2567bbbc83a; __gads=ID=f5bf17d7797239d3-227aa9128ecf00d2:T=1640588801:RT=1640588801:S=ALNI_MYBWT9GYs91XjGmv6vlZ7qGL3ht_Q; __yadk_uid=wX9wcwzazXO3XN9AFd60eUUl7x7b9bjo; __utmz=30149280.1640614862.5.5.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmz=223695111.1640614862.4.4.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1640667200%2C%22https%3A%2F%2Fcn.bing.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.1607185886.1640317225.1640665257.1640667200.7; __utma=223695111.1200427924.1640531148.1640665257.1640667200.6; __utmb=223695111.0.10.1640667200; Hm_lvt_16a14f3002af32bf3a75dfe352478639=1640610451,1640668363; __utmc=30149280; __utmc=223695111; ap_v=0,6.0; __utmt=1; __utmb=30149280.4.10.1640667200; _pk_id.100001.4cf6=af16e508012adde8.1640531148.6.1640673421.1640665257.' 25 head={ 26 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62", 27 "Cookie": cookie.encode("utf-8").decode("latin1")} 28 #模仿浏览器头部 29 request=urllib.request.Request(url,headers=head) 30 try: 31 response=urllib.request.urlopen(request) 32 html = response.read().decode("utf-8") 33 return html 34 except urllib.error.URLError as e: 35 if hasattr(e,"code"): 36 print(e.code) 37 elif hasattr(e,"reason"): 38 print(e.reason) 39 #2.解析数据 40 o = 1 41 for i in range(0,10): #调用获取页面信息的函数 42 url=f"https://movie.douban.com/top250?start={i*25}&filter="#对10页网页进行依次爬取 43 html=askURL(url) 44 soup=BeautifulSoup(html,'html.parser') 45 46 # 影片评价人数 47 findJudge=soup.find_all('div',{'class':'star'}) 48 for i in findJudge: 49 people=i.string 50 # < span > 2512760人评价 < / span > 51 k=re.findall(r'(\d*?)人评价',str(i))[0] 52 qw.append(k) 53 print(k) 54 # 影片评分 55 findRating=soup.find_all('span',{'class':'rating_num'}) 56 for i in findRating: 57 z=i.string 58 we.append(z) 59 print(z) 60 61 # 影片标题 62 findTitle =soup.find_all('span',{'class':'title'}) 63 for i in findTitle : 64 if " / " in str(i): #只爬取电影的中文名称 65 continue 66 d=i.string 67 er.append(d) 68 print(d) 69 # 影片详情链接 70 findLink =soup.find_all('div',{'class':'hd'}) 71 for i in findLink : 72 b=i.select('a')[0].get('href') 73 rt.append(b) 74 print(b) 75 76 # 影片相关内容 77 findInq=soup.find_all('div',{'class':'bd'})[1:] 78 for i in findInq: 79 y=i.select('p')[0].get_text() 80 ty.append(y) 81 print(y) 82 # 影片图片 83 findImgSrc=soup.find_all('div',{'class':'pic'}) 84 for i in findImgSrc: 85 q=i.select('img')[0].get('src') 86 request = urllib.request.Request(q) 87 response = urllib.request.urlopen(request) 88 html = response.read() 89 with open(f'.//img/{o}.jpq', "wb") as f: 90 # 写文件用bytes而不是str,所以要转码 91 f.write(html) 92 o += 1 93 #实o每次加以以达到换页的效果 94 # print(len(qw)) 95 # print(len(we)) 96 # print(len(er)) 97 # print(len(rt)) 98 # print(len(ty)) 99 #测试文本数量是否一致 100 u=[]#建立一个空的列表用于存放数据 101 df = np.DataFrame(data=[qw,we,er,rt,ty],index=['评论人数','评分','电影名','超链接','电影人员介绍'])#将数据保存到列表中 102 df2=np.DataFrame(df.values.T,columns=df.index)#对文本进行,行换列,列换行 103 df2.to_excel('qq.xlsx')#保存数据到xlsx文件中 104 df=pd.read_excel('qq.xlsx')#导入数据 105 b=df['电影名'].values.tolist()[:250] 106 a=df['评分'].values.tolist()[:250] 107 s=df['评论人数'].values.tolist()[:250] 108 109 110 111 #——————————————————————————————————————评价等级可视化———————————————————————————————————————————————————————————— 112 c = ( 113 Bar({"theme": ThemeType.MACARONS}) 114 .add_xaxis(b) 115 .add_yaxis("评分",a) 116 # .add_yaxis("评论人数",s) 117 .set_global_opts( 118 title_opts={"text": "Bar-通过 dict 进行配置", "subtext": "我也是通过 dict 进行配置的"} 119 120 ) 121 .set_global_opts(title_opts=opts.TitleOpts(), 122 datazoom_opts=opts.DataZoomOpts(),#分段 123 xaxis_opts=opts.AxisOpts(name_rotate=60, name="电影名", axislabel_opts={"rotate": 35})#字体倾斜角度 124 ) 125 126 .render("评级.html") 127 ) 128 129 130 #————————————————————————————————————评价人数可视化—————————————————————————————————————————————————————————————— 131 132 c = ( 133 Bar({"theme": ThemeType.MACARONS}) 134 .add_xaxis(b) 135 # .add_yaxis("评分",a) 136 .add_yaxis("评论人数",s) 137 .set_global_opts( 138 title_opts={"text": "Bar-通过 dict 进行配置", "subtext": "我也是通过 dict 进行配置的"} 139 140 ) 141 .set_global_opts(title_opts=opts.TitleOpts(), 142 datazoom_opts=opts.DataZoomOpts(),#分段 143 xaxis_opts=opts.AxisOpts(name_rotate=60, name="电影名", axislabel_opts={"rotate": 35})#字体倾斜角度 144 ) 145 146 .render("评价人数.html") 147 ) 148 149 150 151 #——————————————————————————————————————————————豆瓣Top250多Y轴数据分析———————————————————————————————————————————————— 152 bar = ( 153 Bar() 154 .add_xaxis(b) 155 .add_yaxis( 156 "评分", 157 a, 158 yaxis_index=0, 159 color="#d14a61", 160 ) 161 .add_yaxis( 162 "评价人数", 163 s, 164 yaxis_index=1, 165 color="#5793f3", 166 ) 167 .extend_axis( 168 yaxis=opts.AxisOpts( 169 name="评价人数", 170 type_="value", 171 min_=0, 172 max_=3000000, 173 position="right", 174 axisline_opts=opts.AxisLineOpts( 175 linestyle_opts=opts.LineStyleOpts(color="#d14a61") 176 ), 177 axislabel_opts=opts.LabelOpts(formatter="{value} ml"), 178 ) 179 ) 180 .extend_axis( 181 yaxis=opts.AxisOpts( 182 type_="value", 183 name="评分", 184 min_=0, 185 max_=2000000, 186 position="left", 187 axisline_opts=opts.AxisLineOpts( 188 linestyle_opts=opts.LineStyleOpts(color="#675bba") 189 ), 190 axislabel_opts=opts.LabelOpts(formatter="{value} "), 191 splitline_opts=opts.SplitLineOpts( 192 is_show=True, linestyle_opts=opts.LineStyleOpts(opacity=1) 193 ), 194 ) 195 ) 196 .set_global_opts( 197 yaxis_opts=opts.AxisOpts( 198 name="评分", 199 min_=0, 200 max_=10, 201 position="right", 202 offset=80, 203 axisline_opts=opts.AxisLineOpts( 204 linestyle_opts=opts.LineStyleOpts(color="#5793f3") 205 ), 206 axislabel_opts=opts.LabelOpts(formatter="{value} ml"), 207 ), 208 title_opts=opts.TitleOpts(title="豆瓣Top250多Y轴数据分析"), 209 tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"), 210 datazoom_opts=opts.DataZoomOpts(), # 分段 211 xaxis_opts=opts.AxisOpts(name_rotate=60, name="电影名", axislabel_opts={"rotate": 35}) # 字体倾斜角度 212 ) 213 ) 214 215 line = ( 216 Line() 217 .add_xaxis(b) 218 .add_yaxis( 219 "平均评分", 220 s, 221 yaxis_index=2, 222 color="#675bba", 223 label_opts=opts.LabelOpts(is_show=False), 224 ) 225 ) 226 227 228 229 #——————————————————————————————————————————————豆瓣Top250电影3D可视化分析图———————————————————————————————— 230 data = [(i, j, random.randint(0, 10)) for i in range(10) for j in range(10)] 231 c = ( 232 Bar3D() 233 .add( 234 "", 235 [[d[1], d[0], d[2]] for d in data], 236 xaxis3d_opts=opts.Axis3DOpts(a), 237 yaxis3d_opts=opts.Axis3DOpts(b), 238 zaxis3d_opts=opts.Axis3DOpts(s), 239 ) 240 .set_global_opts( 241 visualmap_opts=opts.VisualMapOpts(max_=20), 242 title_opts=opts.TitleOpts(title="豆瓣Top250电影可视化分析图"), 243 ) 244 .render("bar3d_base.html") 245 )
五、总结
1.经过对爬取的豆瓣电影数据分析,电影的评分和评价人数没有直接的关系,但是又间接的关系。
大多数口碑比较好的电影评价的人数就很多。所以,看电影的时候可以先看一下评分,再看一下评价人数的多少,来判断电影的好坏。
2.写完这个之后才发现,在即在爬虫上的不足,对于网页标签的摘取,和最后数据的处理都有一定的不足,每次遇到不会的还要去网上翻阅资料。有时候程序出现错误,自己知道错误在哪,但不知道如何更改以达到自己想要的目的。
这次爬虫花费了很大的时间和经历,是我觉得自学习刚接触编程语言以来做过最令我高兴的事情。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号