看不懂JDK8的流操作?5分钟带你入门(转)
在JDK1.8里有两个非常高级的新操作,它们分别是:Lambda 表达式和 Stream 流。
Lambda表达式
让我们先说说 Lambda 表达式吧,这个表达式最大的作用就是简化语法,让代码更加易读。例如下面这个例子:
new Thread(new Runnable() { @Override public void run() { System.out.println("简单的线程实现"); } }).start();
在上面的代码里我们简单实现了一个线程,但如果使用 Lambda 表达式,我们可以这么写:
new Thread(() -> { System.out.println("Lambda可读性强一些"); }).start();
使用 Lambda 表达式之后,原先 6 行代码只需要 1 行就可以实现了,代码可读性也会强许多。但对于还没掌握 Lambda 表达式的人来说,如何看懂这个表达式却是一个问题。那么接下来我们就来看看 Lambda 表达式的语法格式吧。
一般来说,Lambda 表达式有 3 种写法。
第1种:一般语法。
(Type1 param1, Type2 param2, ..., TypeN paramN) -> { statment1; statment2; //............. return statmentM; }
这种是 Lambda 表达式的完整语法,后面几种都是对它的简化。
例如下面两种写法是等价的:
Collections.sort(names, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1.compareTo(o2); } }); Collections.sort(names, (Integer o1, Integer o2) -> { return o1.compareTo(o2); });
第2种:单参数语法。
当 Lambda 表达式的参数个数只有一个时,可以省略小括号,变成下面这种格式:
param1 -> { statment1; statment2; //............. return statmentM; }
第3种:单语句写法。
当 Lambda 表达式只包含一条语句时,可以省略大括号、return和结尾的分号。
param1 -> statment
我们上面创建 Thread 匿名类就是使用这种语法格式。
关于 Lambda 表达式,掌握这几种写法就够用了。
Stream流
Stream 流是 JDK1.8 中一个重要的特性,很多时候 Stream 流也会和 Lambda 表达式一起使用,所以掌握 Stream 流也是很重要的。
首先,我们先看这样一个例子。
for (Integer num : numList) { if (num < 20) { subList.add(num); } }
这个例子中,我们将 numList 中值小于 20 的手机到 subList 中。但如果使用 Stream 流,我们可以这么写:
subList = numList.stream().filter(num -> num < 20).collect(Collectors.toList());
我们只用了一行就实现了 5 行才能实现的功能,而这就是 Stream 流的用处之一。上面的这行代码简单地说,是这样一个逻辑:对 numList 生成一个数据流,之后对其应用一个过滤器,这个过滤器会对每一个元素(取名为num)与20进行判断,符合要求的留下,最后将符合要求的收集成一个 List 返回。
或许我这样解释之后你还不太懂 Stream 流的语法。没关系,下面我们会对 Stream 流的语法再做一个全面的解释。
在开始说 Stream 流的语法之前,我们首先要理解 Stream 流这个概念。因此我们先问自己一个问题:Stream 流到底是什么?
相对于集合(数据的集合),Stream 流其实是用于操作数据源的元素序列。集合说的是数据,而流讲的是计算。通过 Stream 流,你可以对数据进行非常复杂的查找、过滤和映射数据等操作。
那么,我们如何使用 Stream 流进行这些复杂的操作呢?
使用 Stream 流可以分为三个步骤,分别是:创建 Stream 流、中间操作、终止操作。

从上图可以看到,中间的 filter、sorted、map 都是中间操作,分别对应针对集合进行过滤、排序、映射操作。我们上面筛选出数值大于 20 的例子,就是对数据进行过滤操作,使用了 filter 这个中间操作。
在使用 Stream 流的三个步骤中,我们有几点需要重点注意:
- Stream 自己不会存储元素。
- Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
- Stream 操作是延迟执行的。这意味着他们会等到需要结果,即执行终止操作的时候才执行。
下面我们详细地来说一说这三个步骤。
创建Stream流
创建 Stream 流的方式,常见的有下面几种方式:通过集合创建、通过数组创建、通过值创建。
通过集合创建:
List<String> list = new ArrayList<>(); Stream<String> stream = list.stream();
通过数组创建:
Integer[] nums = new Integer[10]; Stream<Integer> stream = Arrays.stream(nums);
通过值创建:
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6);
除了上面三种常见的创建方式之外,还有更多种创建方式,这里不再介绍太多。
中间操作
当我们创建完 Stream 流之后,就可以针对元素做中间操作,这些中间操作有下面几种类型:筛选、映射、排序。
筛选
筛选就是只取流中部分元素,根据不同的需求,可以选择条件判断,或者只取前几个。具体情况具体选择,例如下面的这个例子:
subList = numList.stream().filter(num -> num <20).collect(Collectors.toList());
它对元素进行了筛选,只取值小于 20 的元素。
映射

映射是将原有流转变成另一个流,两个流的元素类型不同。我们看看下面这个例子:
List<User> userList = new ArrayList<>(); userList.add(new User("zhangsan", 23)); userList.add(new User("lisi", 38)); userList.add(new User("wangwu", 88)); List<String> nameList = userList.stream().map(user -> user.getName()).collect(Collectors.toList());
上面的例子中,我们将 userList 中的 User 集合,转换成 User 对象中 name 的集合,其流类型从 User 类型转成了 String 类型。上面的代码,nameList 的值为: ["zhangsan","lisi","wangwu"]。
排序
排序就是对流中的数据进行排序。例如下面这个例子:
List<Integer> list = new ArrayList<>(); list.add(23); list.add(12); list.add(65); list.add(56); List<Integer> collect = list.stream().sorted().collect(Collectors.toList()); collect.stream().forEach(list2 -> System.out.println(list2));
在上面的代码中,我们针对 list 集合做排序,默认是升序排列。我们打印出 subList 列表的值,最终其结果是: [12,23,56,65]。
终止操作
终止操作就是执行之前的中间操作,并且获取结果。也只有在终止操作发生之时,中间操作才会执行。就像我们上面例子中的 collect() 方法,就是终止操作的一种,其表示将结果收集起来。
根据终止操作的不同操作类型,可以分为 3 种操作:查找与匹配、归约、收集。
查找与匹配
查找与匹配的常用方法如下图所示:
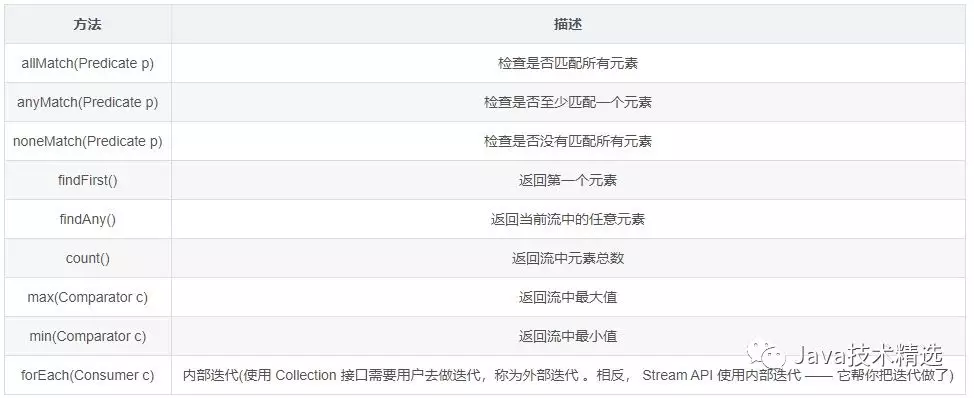
下面我们用一个例子,简单说明其使用:

我们有一个 userList 集合,我们首先筛选了所有大于 30 岁的用户,那么现在只剩下 lisi 和 wangwu。之后使用 allMatch 终止操作,判断剩下的所有用户其用户名字是否为 wangwu,最终返回的是一个 boolean 值。结果当然是 false 了,因为剩下的用户除了 wangwu 之外,还有 lisi。
规约
规约就是将流中的元素按照 BinaryOperator 中定义的操作进行运算,最后给出最终结果。常见有下面两种操作。


像上面这个操作,是将 1-10 进行相加,最终的结果是:55。注意最前面的 0 是参与运算的,所以如果你将其改成 x * y,那么结果将会是 0。
Tips:关于规约操作,我也没搞得非常懂,有了解得比较深入的同学可以留言交流一下。
收集
收集决定了如何对流执行收集操作(如收集到 List、Set、Map)。

collect 方法接收一个具体的收集对象,指明是收集到那种类型的集合中。我们可以通过 Collectors 类的静态方法,可以方便地创建常见收集器实例。

例如在上面的例子中,我们经常将结果收集到 List 集合中。
List<Integer> collect = list.stream().sorted().collect(Collectors.toList());
总结
如果能掌握好 Stream 流和 Lambda 表达式,那么可以极大地提高写作效率,提高代码可读性。但前提是需要搞清楚这两个高级特性的语法格式,不然看这些代码就像看天书一样。
这篇文章将这两种语法做了一个全面的介绍,基本上能够涵盖大部分使用场景。虽然没有针对每个方法给出例子,但是胜在结构清晰,内容全面。建议朋友们收藏作为工具使用,某个时候如果忘记用法可以翻出来看看。
参考资料
- https://blog.csdn.net/young4dream/article/details/76794659 关于流的理解不错
- https://blog.csdn.net/Keith003/article/details/80252553
- https://blog.csdn.net/liupeifeng3514/article/details/80716305 有详细的例子
- https://www.cnblogs.com/CarpenterLee/p/6550212.html 如何使用collection生成Map,这里的例子解释得很清楚。
- https://www.cnblogs.com/jalja/p/7655170.html 例子写得不错
- https://www.cnblogs.com/junjiang3/p/8998509.html lambda表达式语法格式
转自: https://mp.weixin.qq.com/s/dJbfXbjs_WhYyjr11gXqJQ

 浙公网安备 33010602011771号
浙公网安备 33010602011771号