

本次实验包括用C语言分别实现开放地址法的哈希表与链地址法的哈希表,对实现的哈希表进行大量的随即插入后随机查找已经插入的数据,然后计算出平均查找长度.
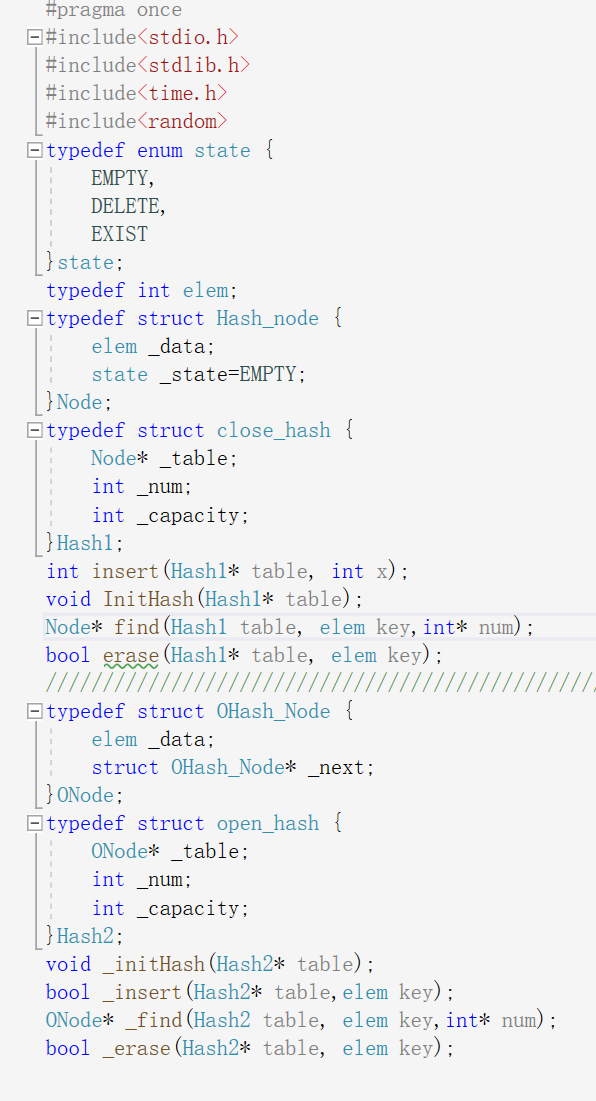
首先是开放地址法的闭散列:


只要是插入就先考虑扩容,因为哈希表的特殊性表的容量变大时,里面的数据也要重新分布,所以这里直接新开了一个哈希表调用已经实现的插入函数,在遍历旧表时将数据插入新表,然后调换地址,释放旧空间.这个表写了不可以插入重复的关键字,因为map和set不支持重复的key,然后是常规的计算位置将数据插入哈希表.
用开放地址法处理哈希冲突的哈希表在查找遇到冲突时向后探测访问到空时不知道这个位置时删除还是真空,导致本来有的数据显示为无,所以需要加一个删除的状态,在探测的同时判断需不需要向后探测.

开散列的链地址法:
插入思路一样,先判断扩容情况,再进行插入,需要注意的是:在开辟空间时开辟的是一长串连续的地址,在释放的时候也是释放这一块地址,所以在释放旧表时需要将表上挂着的链子释放掉再释放表,不然会造成严重的内存泄漏,这里为了方便,在旧表替换新表的同时释放掉旧结点.

为了避免开辟到的空间是野指针,这里需要对每个节点初始化然后就是普通的插入.
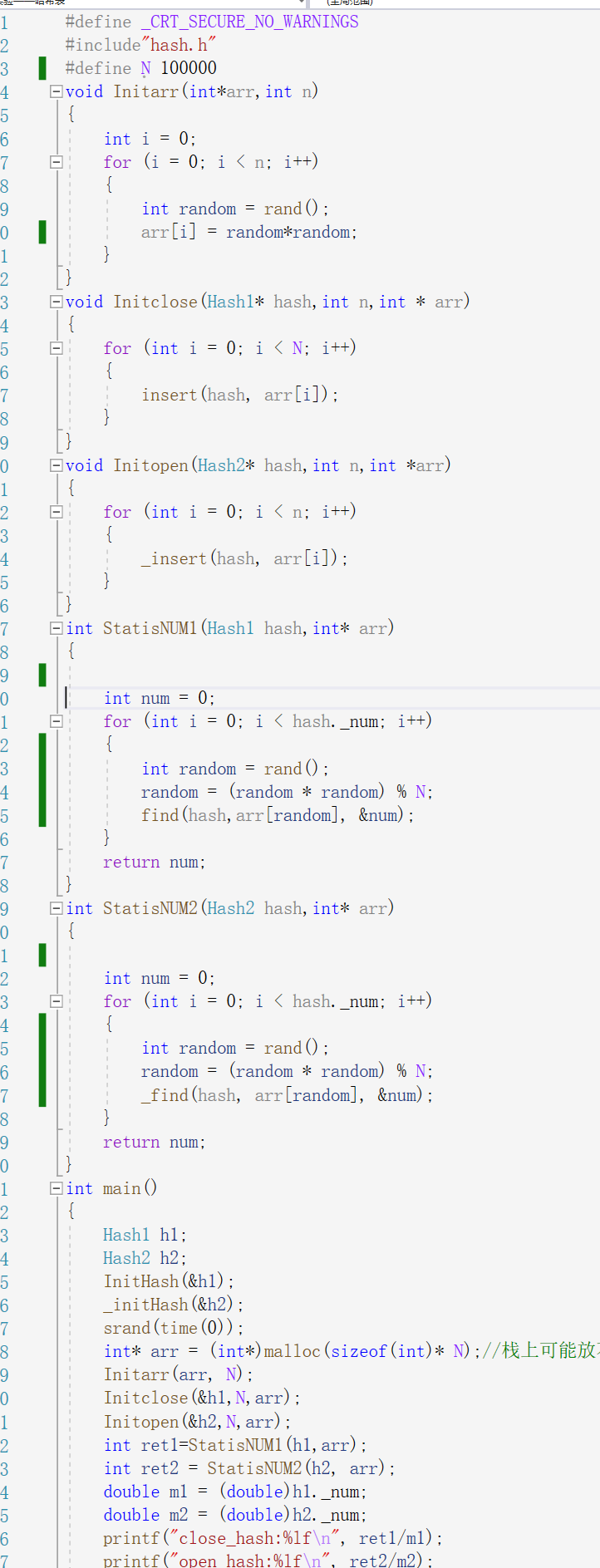
测试方案:
为了控制变量是测试结果更准确先是将生成的随机数存入一个堆空间的数组中,,之后两个表都用这个数组测试,因为随机数最多只能到3万多,也就是最多插入3万多个数据,当N为100000时就会让每个数字都放到应有的位置,且不会出现冲突,导致每次测试结果都为1,对得到的随机数进行平方处理,虽然不会使数据变多但是可以让其起冲突,更加显著的对比两表的差异.

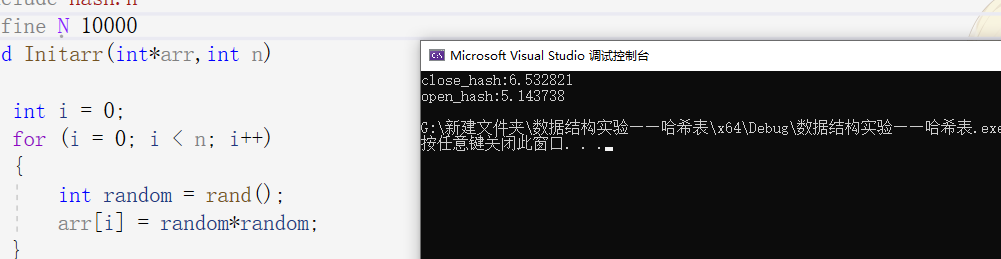


可以看到不同数据时链地址法总是要比开放地址法要查找的少一点
之前有提过布隆过滤器这个快速处理字符串查重工具,但是他给出的结果存在一定的不准确性,导致他只能在一些特定的情况下起作用.那么怎样让数据一定判断准确呢
先提出一个解决思路,可以将这些字符串平均分割成若干个大小适合的小文件.假设有一个很大的用户key,要在这里面精确找某一个key存不存在,可以将其分割到适应内存大小,然后精确查找,但是这样很慢,如果是找到两个很大文件的交集就更慢了.
所以有了哈希切割:在存入数据是就对数据作处理将其一样的key放在一个小文件中,在查找时直接对key作处理找到相应的文件很快就能找到.找到文件的交集也是这样,将两个文件以同样的方式分割.将对应的两个小文件对比,很快就能找完.
一致性哈希:上面的方法能很快的处理海量的数据,但是对于下面的问题有有困境l:
比如facebook在全球有这很大的用户体,这些用户的数据都存放在facebook的服务器中,假设有50亿用户每个用户占用100m的空间,那么就需要好多好多的服务器空间来存这些数据,所以肯定不止一台服务器,而且用户的数据随着时间也会越来越多,增加服务器台数是不可避免的,但是我们知道哈希扩容很麻烦,要是对这些数据按照上面的扩容方法,facebook肯定得停服维护好久.所以人们提出了一个新办法,在存数据是key设定为2^32这么大,取余得到的数据实际就放到编号为几的服务器中,但是又有问题了,哪里来的这么多服务器呢?其实也不用每个编号用一台服务器.,可以用一台服务器存储一个范围的编号,比如编号为30000-40000的key存入一个机器中,当这台机器存不下时,对这台机器中的数据重新按安排到两台机器中,编号30000-40000存放入新增的机器中,40000-50000放入旧机器中这样就不需要处理所有数据来达到增容的效果.这就是一致性哈希

 浙公网安备 33010602011771号
浙公网安备 33010602011771号