
机器学习入门(九)之----logistic回归(牛顿法)
多绚烂的花,多美妙的季节;
没有一朵花,能留住它的季节。
我也是一样,不停地追寻,
我终究要失去的
回到logistic回归最大似然函数这里,现在我们用牛顿法来最大化这个对数似然函数。
牛顿法求零点
牛顿法本是用来求函数零点的一个方法,一个函数的零点就是指使这个函数等于零那个自变量的取值点。
牛顿法的更新公式为,
\[\begin{equation}
\theta :=\theta-\frac{f(\theta)}{f^{\prime}(\theta)}
\end{equation}
\]
这个更新公式有一个非常自然的解释,就是在当前近似零点处的切线的零点作为下一轮零点的更好的近似。然后不停重复这个过程来不断的逼近真实的零点。这个过程如下图,
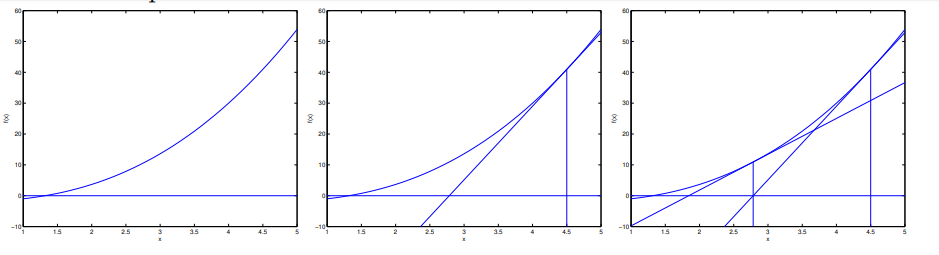
牛顿法求极值点
牛顿法是求零点的一个方法,现在求一个函数机智的就是求函数导数的零点,因此就有如下的牛顿法求极值点更新公式,
\[\begin{equation}
\theta :=\theta-\frac{\ell^{\prime}(\theta)}{\ell^{\prime \prime}(\theta)}
\end{equation}
\]
现在我们在logistic回归中要最大化的那个参数是一个向量。因此牛顿法推广到高维情形(又叫Newton-Raphson法),就有,
\[\begin{equation}
\theta :=\theta-H^{-1} \nabla_{\theta} \ell(\theta)
\end{equation}
\]
其中,函数 $\ell(\theta) $ 的Hessian矩阵$ H$ 的$ (i,j)$ 元素 定义为,
\[\begin{equation}
H_{i j}=\frac{\partial^{2} \ell(\theta)}{\partial \theta_{i} \partial \theta_{j}}
\end{equation}
\]
牛顿法迭代较少轮数下就能很快收敛,但在每一轮牛顿法一般要比梯度下降法的代价要高得多,因为他要涉及到求阶数为特征个数的矩阵逆(特征个数少时,还是很快的)。世上安得两全法。
刚用牛顿法来求logistic对数似然函数最大值点,相应的方法就叫费希尔得分(Fisher scoring.)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号