

scrapy
1. Scrapy框架
1.1 功能:
- 集成了相应功能且通用性很强的模板
- 高性能的异步下载,解析,持久化
1.2 创建scrapy项目
-
在命令里输入scrapy,有提示,说明安装好了,cmd里不行,要在anaconda里面输,应该是没加anaconda的环境变量的原因
-
切换目录
-
输入
scrapy startproject first,创建了一个first项目 -
输入cd first,进入到项目
-
输入
scrapy genspider first www.qiushibaike.com创建了quotes.py文件,里面输入了网址 -
settings配置
22行,不遵从robot协议,
ROBOTSTXT_OBEY = True改成False,避免获取不到数据19行,对请求载体的身份进行伪装,
USER_AGENT配置 -
在交互界面输入
scrapy crawl first执行,加上--nolog不打印
1.3 目录结构

- spiders:爬虫目录,如创建文件,编写爬虫解析规则
- settings.py:配置文件,如递归层数,并发数,延迟下载
- pipelines.py:数据持久化处理
- items.py:设置数据存储模板,用于结构化数据
- scrapy.cfg:项目的主配置文件
1.4 主文件写法
import scrapy
class FirstSpider(scrapy.Spider):
# 爬虫文件名,通过文件名称可以指定定位到某一个具体的爬虫文件
name = 'first'
# 允许的域名:只可以爬取指定域名下的页面数据
allowed_domains = ['www.qiushibaike.com']
# 起始url:当前工程将要爬取的页面所对应的url
start_urls = ['http://www.qiushibaike.com/']
# 对获取的页面数据进行指定内容的解析
# response:根据起始URL列表发起请求,请求成功后返回的响应对象
# parse返回值必须为迭代器或者为空
def parse(self, response):
print(response.text) # 获取响应对象的页面数据
print('执行结束')
1.5 settings
ROBOTSTXT_OBEY = False
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
2. 基础使用
指定页面的解析
糗事百科中段子的内容和作者
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.qiushibaike.com/text']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
author = div.xpath('./div/a[2]/h2/text()').extract_first() # 将selector对象中存储的数据值拿到
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
print(content)
2.1 持久化存储
2.1.1 磁盘文件
-
基于终端指令
-
保证parse返回一个可迭代对象
-
使用终端指令完成数据存储到指定磁盘文件中的操作
‘scrapy crawl qiubai -o qiubai.csv --nolog’
-
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.qiushibaike.com/text']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
data_list = []
for div in div_list:
author = div.xpath('./div/a[2]/h2/text()').extract_first() # 将selector对象中存储的数据值拿到
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
dict = {
'author': author,
'content': content,
}
data_list.append(dict)
return data_list
-
基于管道
-
items:存储解析到的页面数据
-
pipelines:处理持久化存储的相关操作
-
实现流程:
-
将解析到的页面数据存储到items对象
item文件
-
-
class QiubaiproItem(scrapy.Item):
author = scrapy.Field()
content = scrapy.Field()
- 使用yield关键字将items提交给管道文件进行处理
def parse(self,response):
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
author = div.xpath('./div/a[2]/h2/text()').extract_first()
# 将selector对象中存储的数据值拿到
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
item = QiubaiproItem()
item['author'] = author
item['content'] = content
yield item
- 在管道文件中编写代码完成数据存储的操作
class QiubaiproPipeline(object):
fp = None
def open_spider(self, spider):
self.fp = open('./qiubai_pipe.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 爬虫文件向管道提交一次item就执行一次
author = item['author']
content = item['content']
self.fp.write(author + ':' + content + '\n\n\n')
return item
def close_spider(self, spider):
self.fp.close()
- 在配置文件中开启管道操作
2.1.2 数据库
-
mysql
class QiubaiproPipeline(object): config = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '', 'db': 'qiubai', 'charset': 'utf8' } conn = None cursor = None def open_spider(self, spider): print('开始爬虫') self.conn = pymysql.connect(**self.config) def process_item(self, item, spider): sql = 'insert into qiubai values("%s","%s","%s")' % ("", item['author'], item['content']) self.cursor = self.conn.cursor() try: self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def close_spider(self, spider): print('结束爬虫') self.cursor.close() self.conn.close() -
redis
import redis class QiubaiproPipeline(object): conn = None config = { 'host': '127.0.0.1', 'port': 6379, } def open_spider(self, spider): print('开始爬虫') self.conn = redis.Redis(**self.config) def process_item(self, item, spider): dict = { 'author': item['author'], 'content': item['content'], } self.conn.lpush('data',dict) return item -
编码流程,同上,修改管道文件中的代码
2.1.3 同时保存
再自定义两个类,在settings中加上
2.2 多个URL爬取
请求的手动发送
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.qiushibaike.com/text']
start_urls = ['https://www.qiushibaike.com/text/']
url = 'https://www.qiushibaike.com/text/page/%d/'
page_num = 1
def parse(self, response):
div_list = response.xpath('//*[@id="content-left"]/div')
for div in div_list:
author = div.xpath('./div[@class="author clearfix"]/a[2]/h2/text()').extract_first()
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
item = QiubaibypagesItem()
item['author'] = author
item['content'] = content
yield item
if self.page_num <= 13:
print('爬取到了第%d页面的数据' % self.page_num)
self.page_num += 1
new_url = format(self.url % self.page_num)
yield scrapy.Request(url=new_url, callback=self.parse)
2.3 核心组件
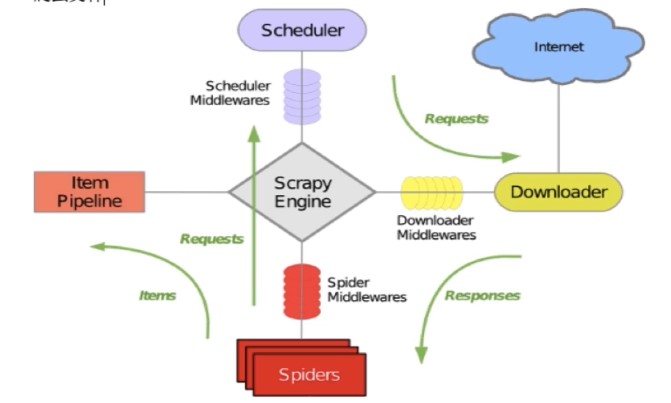
- 引擎
- 管道
- 调度器
- 下载器
- 爬虫文件
引擎监测爬虫文件中的起始url,引擎调用方法对起始url发起请求,爬虫文件获取到请求对象给引擎再转交给调度器,装到调度器队列里,调度器把请求给下载器,下载器去互联网上下载数据,把数据交给爬虫文件,爬虫文件进行页面数据解析,将数据保存到item对象中,转交给管道
![]()

3.代理和cookie
3.1 post请求
豆瓣网的个人登录,获取该用户个人主页这个二级页面的页面数据
对start_requests方法进行重写
- Request()方法中给method赋值post
- FormRequest()进行post请求的发送
3.2 cookie
豆瓣改的爬不了了
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['www.douban.com']
start_urls = ['https://www.douban.com/accounts/login']
def start_requests(self):
for url in self.start_urls:
data = {
'source': 'None',
'form_email': '18668573649@163.com',
'form_password': 'k365532902',
}
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse)
def parseBySecondPage(self, response):
fp = open('second.html', 'w', encoding='utf-8')
fp.write(response.text)
def parse(self, response):
fp = open('main.html', 'w', encoding='utf-8')
fp.write(response.text)
url = 'https://www.douban.com/people/186654449/'
yield scrapy.Request(url=url, callback=self.parseBySecondPage)
3.3 代理操作
下载中间件

自定义中间件
class MyProxy(object):
def process_request(self, request, spider):
request.meta['proxy']= 'http://39.137.77.66:8080'
settings里面开启中间件生效
DOWNLOADER_MIDDLEWARES = {
'proxyPro.middlewares.MyProxy': 543,
}
3.4 日志操作
- 日志等级:
- error
- warning
- info
- debug
- 过滤日志等级
在settings里写上LOG_LEVEL='ERROR'
对日志信息进行存储LOG_FILE='log.txt'
3.5 请求传参
爬取的数据不在同一个页面中
调用一个链接函数
class MovieSpider(scrapy.Spider):
name = 'movie'
# allowed_domains = ['www.55xia.com']
start_urls = ['https://www.55xia.com/movie']
def parseSecondPage(self, response):
actor = response.xpath(
'/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[1]/td[2]/a/text()').extract_first()
language = response.xpath(
'/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[6]/td[2]/text()').extract_first()
long_time = response.xpath(
'/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[8]/td[2]/text()').extract_first()
item = response.meta['item']
item['actor'] = actor
item['language'] = language
item['long_time'] = long_time
yield item
def parse(self, response):
div_list = response.xpath('/html/body/div[1]/div[1]/div[2]/div')
for div in div_list:
name = div.xpath('.//div[@class="meta"]/h1/a/text()').extract_first()
kind = div.xpath('.//div[@class="otherinfo"]//text()').extract()
kind=''.join(kind)
url = div.xpath('.//div[@class="meta"]/h1/a/@href').extract_first()
url = 'https:%s' % url
item = MovieproItem()
item['name'] = name
item['kind'] = kind
yield scrapy.Request(url=url, callback=self.parseSecondPage, meta={'item': item})
4. CrawlSpider
对网站全站进行爬取
4.1 创建
scrapy genspider -t crawl 爬虫名 url
4.2 使用
rules = (
Rule(LinkExtractor(allow=r'/all/hot/recent/\d{0,1}$'), callback='parse_item', follow=True),
)
LinkExtractor(allow=r'/all/hot/recent/\d{0,1}$')
实例化了一个链接提取器对象,用来提取指定的链接,allow赋值一个正则表达式,提取到的链接交给规则解析器rules实例化了一个规则解析器对象,获取链接提取器发送的链接后,会对这些链接发起请求,获取链接对应的页面内容,根据指定的规则对页面中指定的规则(callback)进行解析callback:解析follow:是否将链接提取器继续作用到链接提取器提取出的链接所表示的页面数据
5. 分布式爬虫
- 多台机器上可以执行同一个爬虫程序,实现网站数据的分布爬取
- 原生的scrapy不支持分布式爬虫
- 调度器无法共享
- 管道无法共享
- scrapy-redis组件
5.1 redis配置
配置文件56行中bind 127.0.0.1注释掉
配置文件75行中protected-mode yes改成no
5.2 使用流程
-
创建-t crawl项目
-
redis开启
-
导入
from scrapy_redis.spiders import RedisCrawlSpider,替换原有的父类 -
将strat_url注释掉,修改成redis_key='xxx',(调度器队列名称)
-
settings修改管道,
>ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 400,} -
settings修改参数
使用组件的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
调度器修改
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
是否允许暂停
SCHEDULER_PERSIST = True -
redis:如果redis服务器不在本机,需要如下配置
REDIS_HOST="redis服务的ip地址"
REDIS_PORT="6379"
5.3 爬虫程序执行
- 先定位到spider文件夹,找到py文件
scrapy runspider qiubai.py文件名称,程序停留在listening阶段,等待redis客户端输入指定- 去redis客户端上输入
lpush qiubaispider(这个是定义的redis_key) url - 在redis客户端输入
keys *查询文件夹 - 在redis客户端输入
lrange qiubai:items(上一步查到的文件夹) 0 -1显示文件
6 浏览器
6.1 处理动态加载的内容
- 创建浏览器对象
from selenium import webdriver
def __init__(self):
self.bro=webdriver.Chrome(executable_path='D:\python\chromedriver')
- settings中的
DOWNLOADER_MIDDLEWARES取消注释
6.2 具体代码
from selenium import webdriver
class WangyiSpider(scrapy.Spider):
name = 'wangyi'
start_urls = ['https://news.163.com/']
def __init__(self):
self.bro = webdriver.Chrome(executable_path='D:\python\chromedriver')
def getContent(self, response):
item = response.meta['item']
content_list=response.xpath('//div[@class="post_text"]/p/text()').extract()
content=''.join(content_list)
item['content']=content
yield item
def parseSecond(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
head = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
url = div.xpath('.//div[@class="news_title"]/h3/a/@href').extract_first()
tag = div.xpath('/html/body/div/div[3]/div[4]/div[1]/div/div/ul/li/div/div[2]/div/div[2]/div/a/text()').extract()
tags=[]
for t in tag:
t=t.strip('\n \t')
tags.append(t)
tag = ','.join(tags)
item = WangyiproItem()
item['head'] = head
item['url'] = url
item['tag'] = tag
item['title'] = response.meta['title']
yield scrapy.Request(url=url, callback=self.getContent, meta={'item': item})
def closed(self, spider):
self.bro.quit()
print('爬虫结束')
def parse(self, response):
lis = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
indexs = [3, 4]
li_list = []
for index in indexs:
li_list.append(lis[index])
for li in li_list:
url = li.xpath('./a/@href').extract_first()
title = li.xpath('./a/text()').extract_first()
yield scrapy.Request(url=url, callback=self.parseSecond, meta={'title': title})
中间件修改
class WangyiproDownloaderMiddleware(object):
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# 拦截下载器传递给spider的相应对象
if request.url in ['http://news.163.com/domestic/', 'http://news.163.com/world/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
# 页面下拉
spider.bro.execute_script(js)
time.sleep(2) # 等待加载
page_text = spider.bro.page_source
return HtmlResponse(url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request)
else:
return response
7. UA池和代理池
7.1 UA池
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
写中间件
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
import random
class RandomUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua=random.choice(user_agent_list)
request.headers.setdefault('User-Agent',ua)
user_agent_list = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
]
写settings
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
'wangyiPro.middlewares.RandomUserAgent': 542,
}
7.2 代理池
settings配置
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
'wangyiPro.middlewares.RandomUserAgent': 542,
'wangyiPro.middlewares.Proxy': 541,
}
写中间件
class Proxy(object):
def process_request(self, request, spider):
h = request.url.split(':')[0]
if h == 'https':
ip = random.choice(proxy_https)
request.meta['proxy'] = 'https://' + ip
else:
ip = random.choice[proxy_http]
request.meta['proxy'] = 'http://' + ip
proxy_http = [
'ip1',
'ip2',
]
proxy_https = [
'ip3',
'ip4',
]
8. 分布式爬虫2
基于RedisSpider
- 导包
from scrapy_redis.spiders import RedisSpider - 更换父类
- 起始
url改成redis_key - redis文件配置:注释
bind 127.0.0.1,protected-mode no - 对settings配置:
REDIS_HOST="redis服务的ip地址"
REDIS_PORT="6379"
REDIS_PARAMS={'password':''}
使用组件的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
调度器修改
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
是否允许暂停
SCHEDULER_PERSIST = True - pipeline配置:
scrapy_redis.pipelines.RedisPipeline':400, - 执行:scrapy runspider wangyi.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号