

用Teleport Ultra下载网站全部页面 爬虫
测试case,就是把Commons-FileUpload 的API下载来
上网查的时候我才发现这是一个由很多页面组成的网站,下载起来很麻烦。
怎么办呢?呵呵,一定是有办法的。Teleport Ultra这个工具就能帮我们搞定!
这是一个汉化绿版的迅雷下载链接:thunder://QUFodHRwOi8vMS5jcWR4MS5jcnNreS5jb20vMjAwOTAzL1RlbGVwb3J0VWx0cmEtdjEuNTlILnppcFpa 大小只有759K。
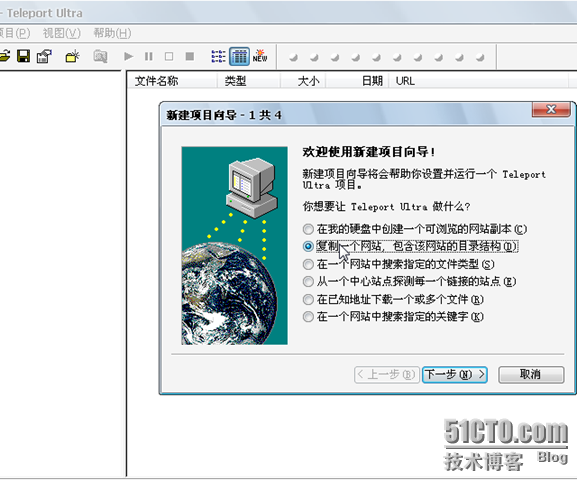
下载完成后解压缩,直接运行ultra.exe,然后选择 文件-新建项目向导

第一步这里选择第二项:复制一个网站,包含该网站的目录结构。
第二步 启始地址填刚才网页的地址:http://commons.apache.org/fileupload/apidocs/index.html
并且指定Teleport的搜索深度为6曾链接。
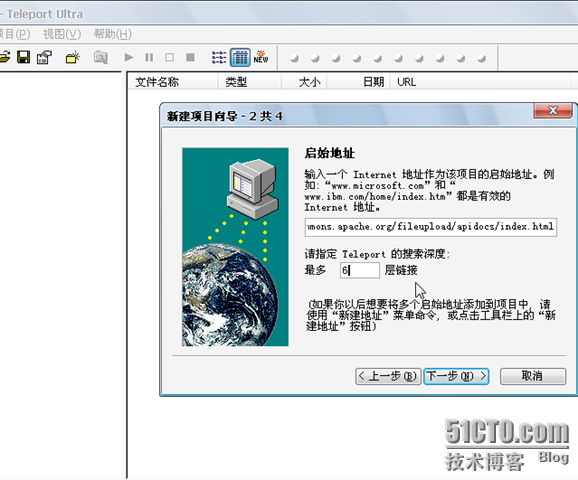
为什么填6呢?细心的朋友应该能发现,最深层Package(包)中的Class(类)的链接是http://commons.apache.org/fileupload/apidocs 后6层链接。
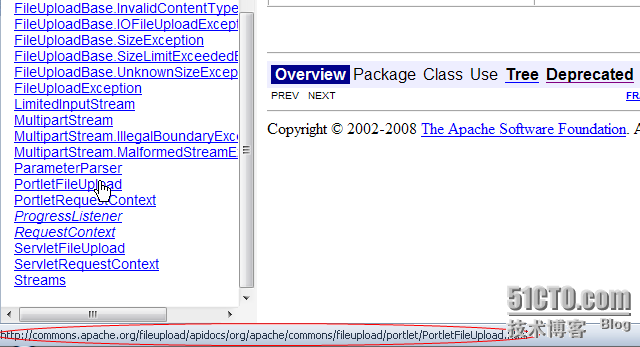
第三步 这里选择网页中媒体,因为是API,我们就直接选择 仅文本。
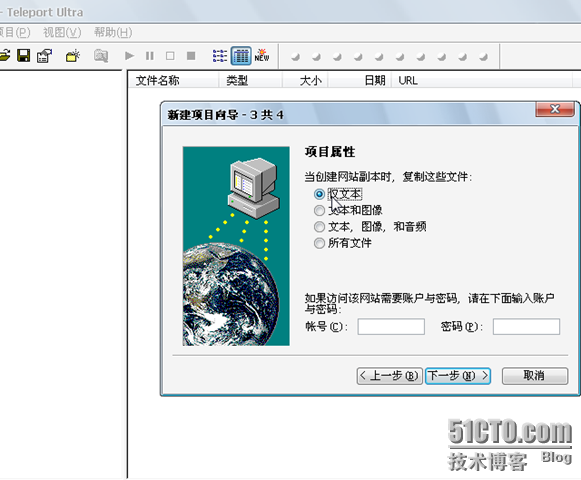
第四步 来确定一下,我们刚刚建的项目。这里有提示,点击开始按钮以运行该项目。

然后,选择一个目录来保存我们刚刚建好的项目,以及网站页面的下载地址。
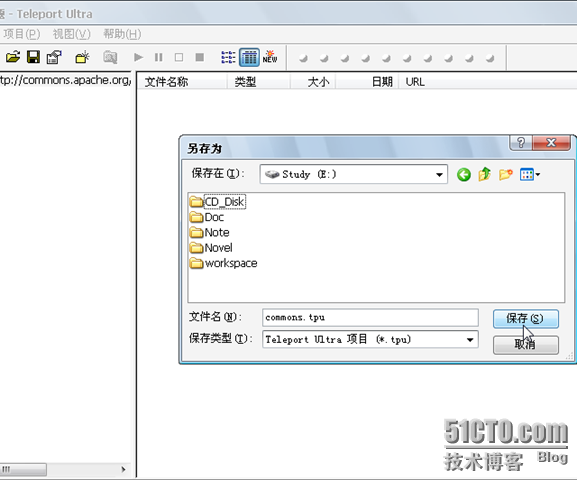
点击开始来启动项目吧。

这是项目进行中,我们能看到,网站结构也被下载到本地。

底部有显示信息,我们能了解到项目的进行状况。
下载好的就是这样的,一个Teleport Ultra的.tpu项目文件,还有就是网站的页面目录。
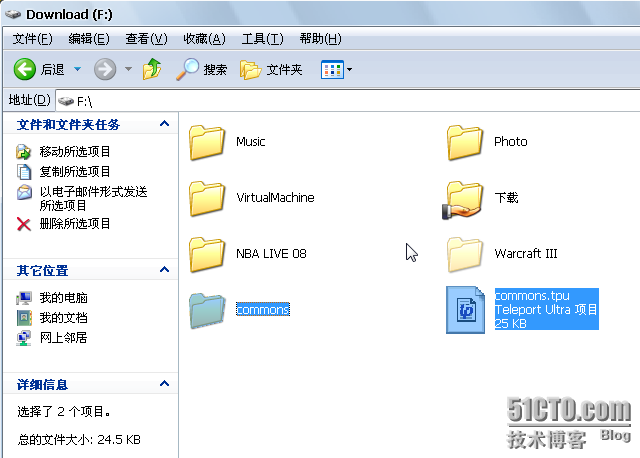
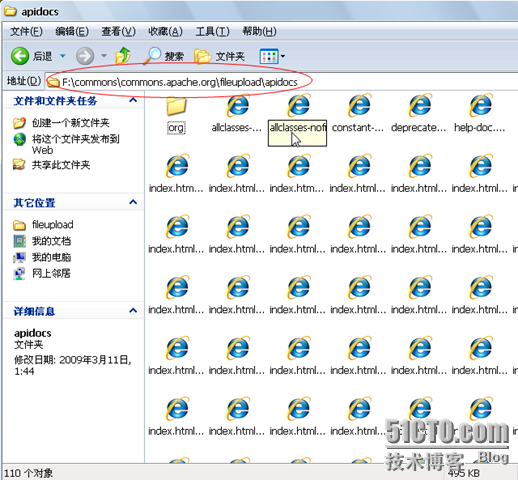
激动人心的时刻到了,去浏览器中访问吧。
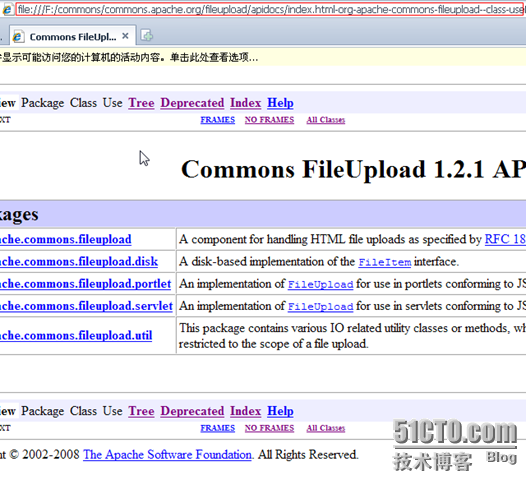
这样一来,不仅仅是Commons-FileUpload的API我们能下载到本地,几乎任何官方API我们都有了办法,JDK,MySQL等等。
现在我们下载的API是页面目录,我会继续努力,争取制作成CHM格式的API文档。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号