分布式存储系统之Ceph集群RBD基础使用
 我们知道Linux主机是由内核空间和用户空间组成;对于Linux主机来说,要想访问底层的硬盘设备,通常都是基于内核的驱动将对应磁盘设备识别成一块存储空间,然后通过用户空间程序执行内核空间的函数来实现操作磁盘;即操作磁盘的操作,最终只有内核有权限;这也意味着,如果一台Linux主机想要使用ceph之上通过RBD抽象出来的磁盘,对应内核空间必须得有一个模块(rbd.ko)能够驱动RBD抽象的硬盘;即Linux内核里的这个模块就是扮演着RBD的客户端;
我们知道Linux主机是由内核空间和用户空间组成;对于Linux主机来说,要想访问底层的硬盘设备,通常都是基于内核的驱动将对应磁盘设备识别成一块存储空间,然后通过用户空间程序执行内核空间的函数来实现操作磁盘;即操作磁盘的操作,最终只有内核有权限;这也意味着,如果一台Linux主机想要使用ceph之上通过RBD抽象出来的磁盘,对应内核空间必须得有一个模块(rbd.ko)能够驱动RBD抽象的硬盘;即Linux内核里的这个模块就是扮演着RBD的客户端;
前文我们了解了Ceph集群cephx认证和授权相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16748149.html;今天我们来聊一聊ceph集群的RBD接口使用相关话题;
RBD是ceph集群向外提供存储服务的一种接口,该接口是基于ceph底层存储集群librados api构建的接口;即RBD是构建在librados之上向外提供存储服务的;对于客户端来说RBD主要是将rados集群之上的某个存储池里的空间通过librados抽象为一块或多块独立image,这些Image在客户端看来就是一块块硬盘;那对于RBD抽象出来的硬盘,客户端该怎么使用呢?
RBD使用场景
我们知道Linux主机是由内核空间和用户空间组成;对于Linux主机来说,要想访问底层的硬盘设备,通常都是基于内核的驱动将对应磁盘设备识别成一块存储空间,然后通过用户空间程序执行内核空间的函数来实现操作磁盘;即操作磁盘的操作,最终只有内核有权限;这也意味着,如果一台Linux主机想要使用ceph之上通过RBD抽象出来的磁盘,对应内核空间必须得有一个模块(rbd.ko)能够驱动RBD抽象的硬盘;即Linux内核里的这个模块就是扮演着RBD的客户端;除了以上场景我们用Linux主机的内核模块来驱动RBD抽象出来的硬盘之外,还有一种场景;我们知道kvm虚拟机在创建虚拟机的时候可以指定使用多大内存,几颗cpu,使用何种磁盘等等信息;其中磁盘设备可以是一个文件系统里的一个磁盘镜像文件虚拟出来的硬盘;即kvm虚拟机是可以通过某种方式来加载我们指定的磁盘镜像;同样的逻辑,kvm虚拟机要想使用RBD虚拟出来的磁盘,它该怎么连入ceph使用RBD磁盘呢?其实很简单,kvm虚拟机自身并没有连入ceph的能力,它可以借助libvirt,libvirt可以通过RBD协议连入ceph集群,将rbd虚拟出的磁盘镜像供给kvm虚拟机使用;而RBD协议自身就是一个c/s架构,rbd的服务是由librbd提供,它不同于其他服务需要监听某个套接字,librbd它不需要监听任何套接字;不同于Linux主机的是,kvm虚拟机是通过libvirt这个工具使用RBD协议连接至ceph集群,而Linux主机使用使用内核模块(RBD)连接ceph集群;很显然一个是用户空间程序,一个是内核空间程序;不管是何种客户端工具以何种方式连入ceph集群使用RBD磁盘;客户端经由RBD存储到rados之上的数据,都会先找到对应存储池,然后被librados切分为等额大小的数据对象,分散的存放在rados的osd对应的磁盘上;这意味着我们需要先在ceph之上创建RBD存储池,同时对应存储池需要被初始化为一个RBD存储才能正常被客户端使用;
RBD管理命令
RBD相关的管理有如image的创建、删除、修改和列出等基础CRUD操作,也有分组、镜像、快照和回收站等相的管理需求,这些均能够通过rbd命令完成;其命令格式为:rbd [-c ceph.conf] [-m monaddr] [--cluster cluster-name] [-p|--pool pool] [command...]
1、创建并初始化RBD存储池
创建存储池:ceph osd pool create {pool-name} {pg-num} {pgp-num}
启用rbd应用:ceph osd pool application enable {pool-name} rbd
rbd初始化:rbd pool init -p {pool-name}
[root@ceph-admin ~]# ceph osd pool create ceph-rbdpool 64 64
pool 'ceph-rbdpool' created
[root@ceph-admin ~]# ceph osd pool ls
testpool
rbdpool
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
cephfs-metadatpool
cephfs-datapool
erasurepool
ceph-rbdpool
[root@ceph-admin ~]# ceph osd pool application enable ceph-rbdpool rbd
enabled application 'rbd' on pool 'ceph-rbdpool'
[root@ceph-admin ~]# ceph osd pool ls detail
pool 1 'testpool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 16 pgp_num 16 last_change 153 flags hashpspool stripe_width 0 compression_algorithm zstd compression_max_blob_size 10000000 compression_min_blob_size 10000 compression_mode passive
pool 2 'rbdpool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 last_change 142 lfor 0/140 flags hashpspool,selfmanaged_snaps max_bytes 1024000000 max_objects 50 stripe_width 0 application rbd
removed_snaps [1~3]
pool 3 '.rgw.root' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 84 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgw
pool 4 'default.rgw.control' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 87 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgw
pool 5 'default.rgw.meta' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 89 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgw
pool 6 'default.rgw.log' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 91 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgw
pool 7 'cephfs-metadatpool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 148 flags hashpspool,pool_snaps stripe_width 0 application cephfs
pool 8 'cephfs-datapool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 last_change 99 flags hashpspool stripe_width 0 application cephfs
pool 10 'erasurepool' erasure size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 last_change 130 flags hashpspool stripe_width 8192
pool 11 'ceph-rbdpool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 184 flags hashpspool stripe_width 0 application rbd
[root@ceph-admin ~]# rbd pool init -p ceph-rbdpool
[root@ceph-admin ~]#
2、创建并查看image
命令格式: rbd create --size <megabytes> --pool <pool-name> <image-name>
[root@ceph-admin ~]# rbd create --size 5G ceph-rbdpool/vol01 [root@ceph-admin ~]# rbd ls -p ceph-rbdpool vol01 [root@ceph-admin ~]#
获取指定镜像的详细信息
命令格式:rbd info [--pool <pool>] [--image <image>] [--image-id <image-id>] [--format<format>] [--pretty-format] <image-spec>
[root@ceph-admin ~]# rbd info ceph-rbdpool/vol01
rbd image 'vol01':
size 5 GiB in 1280 objects
order 22 (4 MiB objects)
id: 149196b8b4567
block_name_prefix: rbd_data.149196b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Tue Oct 4 00:48:18 2022
[root@ceph-admin ~]# rbd info ceph-rbdpool/vol01 --format json --pretty-format
{
"name": "vol01",
"id": "149196b8b4567",
"size": 5368709120,
"objects": 1280,
"order": 22,
"object_size": 4194304,
"block_name_prefix": "rbd_data.149196b8b4567",
"format": 2,
"features": [
"layering",
"exclusive-lock",
"object-map",
"fast-diff",
"deep-flatten"
],
"op_features": [],
"flags": [],
"create_timestamp": "Tue Oct 4 00:48:18 2022"
}
[root@ceph-admin ~]#
提示:size M GiB in N objects,其中M代表image空间大小;N代表将对应M大小的空间分割为多少个对象(分割的数量由条带大小决定,即单个对象的大小,默认为4M);order 22 (4 MiB objects)是块大小(条带)的标识序号,有效范围为12-25,分别对应着4K-32M之间的大小;22=10+10+2,即2的10次方乘以2的10次方乘以2的2次方,2的10次方字节就是1024B,即1k,如果order为10,则块大小为1k,由此逻辑图推算22就是4M;ID代表当前image的标识符;block_name_prefix表示当前image相关的object的名称前缀;format表示image的格式,其中2表示v2;features表示当前image启用的功能特性,其值是一个以逗号分隔的字符串列表,例如layering、exclusive-lock等;op_features表示可选的功能特性;
image特性
layering: 是否支持克隆;
striping: 是否支持数据对象间的数据条带化;
exclusive-lock: 是否支持分布式排他锁机制以限制同时仅能有一个客户端访问当前image;
object-map: 是否支持object位图,主要用于加速导入、导出及已用容量统计等操作,依赖于exclusive-lock特性;
fast-diff: 是否支持快照间的快速比较操作,依赖于object-map特性;
deep-flatten: 是否支持克隆分离时解除在克隆image时创建的快照与其父image之间的关联关系;
journaling: 是否支持日志IO,即是否支持记录image的修改操作至日志对象;依赖于exclusive-lock特性;
data-pool: 是否支持将image的数据对象存储于纠删码存储池,主要用于将image的元数据与数据放置于不同的存储池;
管理image
Image特性管理
J版本起,image默认支持的特性有layering、exclusive-lock、object-map、fast-diff和deep-flatten五个;我们可以使用 rbd create命令的--feature选项支持创建时自定义支持的特性;现有image的特性可以使用rbd feature enable或rbd feature disable命令修改;
[root@ceph-admin ~]# rbd feature disable ceph-rbdpool/vol01 object-map fast-diff deep-flatten
[root@ceph-admin ~]# rbd info ceph-rbdpool/vol01
rbd image 'vol01':
size 5 GiB in 1280 objects
order 22 (4 MiB objects)
id: 149196b8b4567
block_name_prefix: rbd_data.149196b8b4567
format: 2
features: layering, exclusive-lock
op_features:
flags:
create_timestamp: Tue Oct 4 00:48:18 2022
[root@ceph-admin ~]#
提示:如果是使用Linux内核模块rbd来连入ceph集群使用RBD虚拟出来的磁盘,对应object-map fast-diff deep-flatten这三个特性在Linux上是不支持的,所以我们需要将其禁用掉;
使用Linux内核rbd模块连入ceph集群使用RBD磁盘
1、在客户端主机上安装ceph-common程序
[root@ceph-admin ~]# yum install -y ceph-common Loaded plugins: fastestmirror Repository epel is listed more than once in the configuration Repository epel-debuginfo is listed more than once in the configuration Repository epel-source is listed more than once in the configuration Determining fastest mirrors * base: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com Ceph | 1.5 kB 00:00:00 Ceph-noarch | 1.5 kB 00:00:00 base | 3.6 kB 00:00:00 ceph-source | 1.5 kB 00:00:00 epel | 4.7 kB 00:00:00 extras | 2.9 kB 00:00:00 updates | 2.9 kB 00:00:00 (1/2): epel/x86_64/updateinfo | 1.0 MB 00:00:08 (2/2): epel/x86_64/primary_db | 7.0 MB 00:00:52 Package 2:ceph-common-13.2.10-0.el7.x86_64 already installed and latest version Nothing to do [root@ceph-admin ~]#
提示:安装上述程序包,需要先配置好ceph和epel源;
2、在ceph集群上创建客户端用户用于连入ceph集群,并授权
[root@ceph-admin ~]# ceph auth get-or-create client.test mon 'allow r' osd 'allow * pool=ceph-rbdpool'
[client.test]
key = AQB0Gztj63xwGhAAq7JFXnK2mQjBfhq0/kB5uA==
[root@ceph-admin ~]# ceph auth get client.test
exported keyring for client.test
[client.test]
key = AQB0Gztj63xwGhAAq7JFXnK2mQjBfhq0/kB5uA==
caps mon = "allow r"
caps osd = "allow * pool=ceph-rbdpool"
[root@ceph-admin ~]#
提示:对于rbd客户端来说,要想连入ceph集群,首先它对mon需要有对的权限,其次要想在osd之上存储数据,可以授权为*,表示可读可写,但需要限定在对应存储池之上;
导出client.test用户的keyring文件,并传给客户端
[root@ceph-admin ~]# ceph --user test -s
2022-10-04 01:31:24.776 7faddac3e700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.test.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
2022-10-04 01:31:24.776 7faddac3e700 -1 monclient: ERROR: missing keyring, cannot use cephx for authentication
[errno 2] error connecting to the cluster
[root@ceph-admin ~]# ceph auth get client.test
exported keyring for client.test
[client.test]
key = AQB0Gztj63xwGhAAq7JFXnK2mQjBfhq0/kB5uA==
caps mon = "allow r"
caps osd = "allow * pool=ceph-rbdpool"
[root@ceph-admin ~]# ceph auth get client.test -o /etc/ceph/ceph.client.test.keyring
exported keyring for client.test
[root@ceph-admin ~]# ceph --user test -s
cluster:
id: 7fd4a619-9767-4b46-9cee-78b9dfe88f34
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mgr01(active), standbys: ceph-mon01, ceph-mgr02
mds: cephfs-1/1/1 up {0=ceph-mon02=up:active}
osd: 10 osds: 10 up, 10 in
rgw: 1 daemon active
data:
pools: 10 pools, 464 pgs
objects: 250 objects, 3.8 KiB
usage: 10 GiB used, 890 GiB / 900 GiB avail
pgs: 464 active+clean
[root@ceph-admin ~]#
提示:这里需要说明一下,我这里是用admin host主机来充当客户端来使用,本地/etc/ceph/目录下保存的以后集群的配置文件;所以客户端主机上必须要有对应授权keyring文件,以及集群配置文件才能正常连入ceph集群;如果我们在客户端主机上能够使用ceph -s 命令指定对应用户能够查看到集群状态,说明对应keyring和配置文件是没有问题的;
3、客户端映射image
[root@ceph-admin ~]# fdisk -l Disk /dev/sda: 53.7 GB, 53687091200 bytes, 104857600 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x000a7984 Device Boot Start End Blocks Id System /dev/sda1 * 2048 1050623 524288 83 Linux /dev/sda2 1050624 104857599 51903488 8e Linux LVM Disk /dev/mapper/centos-root: 52.1 GB, 52072284160 bytes, 101703680 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/mapper/centos-swap: 1073 MB, 1073741824 bytes, 2097152 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes [root@ceph-admin ~]# rbd map --user test ceph-rbdpool/vol01 /dev/rbd0 [root@ceph-admin ~]# fdisk -l Disk /dev/sda: 53.7 GB, 53687091200 bytes, 104857600 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x000a7984 Device Boot Start End Blocks Id System /dev/sda1 * 2048 1050623 524288 83 Linux /dev/sda2 1050624 104857599 51903488 8e Linux LVM Disk /dev/mapper/centos-root: 52.1 GB, 52072284160 bytes, 101703680 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/mapper/centos-swap: 1073 MB, 1073741824 bytes, 2097152 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/rbd0: 5368 MB, 5368709120 bytes, 10485760 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 4194304 bytes / 4194304 bytes [root@ceph-admin ~]#
提示:我们使用rbd map指定用户,指定存储池和image即可连入ceph集群,将指定存储池里的image映射为本地的磁盘设备;
查看映射的image
[root@ceph-admin ~]# rbd showmapped id pool image snap device 0 ceph-rbdpool vol01 - /dev/rbd0 [root@ceph-admin ~]#
提示:这种手动命令行连入ceph的方式,一旦客户端重启,对应连接就断开了,所以如果我们需要开机自动连入ceph集群使用rbd磁盘,我们还需要将对应信息写进/etc/rc.d/rc.local文件中,并给该文件加上可执行权限即可;
手动断开映射
[root@ceph-admin ~]# rbd unmap ceph-rbdpool/vol01 [root@ceph-admin ~]# rbd showmapped [root@ceph-admin ~]#
调整image的大小
命令格式:rbd resize [--pool <pool>] [--image <image>] --size <size> [--allow-shrink] [--no-progress] <image-spec>
增大空间:rbd resize [--pool <pool>] [--image <image>] --size <size>
减少空间:rbd resize [--pool <pool>] [--image <image>] --size <size> [--allow-shrink]
[root@ceph-admin ~]# rbd create --size 2G ceph-rbdpool/vol02 [root@ceph-admin ~]# rbd ls -p ceph-rbdpool vol01 vol02 [root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK vol01 5 GiB 2 vol02 2 GiB 2 [root@ceph-admin ~]# rbd resize --size 10G ceph-rbdpool/vol02 Resizing image: 100% complete...done. [root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK vol01 5 GiB 2 vol02 10 GiB 2 [root@ceph-admin ~]# rbd resize --size 8G ceph-rbdpool/vol02 Resizing image: 0% complete...failed. rbd: shrinking an image is only allowed with the --allow-shrink flag [root@ceph-admin ~]# rbd resize --size 8G ceph-rbdpool/vol02 --allow-shrink Resizing image: 100% complete...done. [root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK vol01 5 GiB 2 vol02 8 GiB 2 [root@ceph-admin ~]#
提示:缩减空间大小不能少见到小于已用空间大小;
删除image
命令格式:rbd remove [--pool <pool>] [--image <image>] [--no-progress] <image-spec>
[root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK vol01 5 GiB 2 vol02 8 GiB 2 [root@ceph-admin ~]# rbd rm ceph-rbdpool/vol02 Removing image: 100% complete...done. [root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK vol01 5 GiB 2 [root@ceph-admin ~]#
提示:这种方式删除image以后,对应镜像就真的被删除了,如果有数据想恢复就不行了;所以这种方式不推荐;RBD提供回收站的功能,我们可以先将要删除的image移入回收站,如果确实不要了,可以再从回收站删除即可;
将image移入回收站
[root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK vol01 5 GiB 2 [root@ceph-admin ~]# rbd trash mv ceph-rbdpool/vol01 [root@ceph-admin ~]# rbd trash ls ceph-rbdpool 149196b8b4567 vol01 [root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l [root@ceph-admin ~]#
将image从回收站删除
[root@ceph-admin ~]# rbd trash ls ceph-rbdpool 149196b8b4567 vol01 149e26b8b4567 vol02 [root@ceph-admin ~]# rbd trash rm --pool ceph-rbdpool --image-id 149e26b8b4567 Removing image: 100% complete...done. [root@ceph-admin ~]# rbd trash ls ceph-rbdpool 149196b8b4567 vol01 [root@ceph-admin ~]#
提示:上述命令是删除回收站里指定image,如果想要清空回收站直接使用rbd trash purge 指定存储池,表示清空回收站指定存储池里的镜像;
将image从回收站恢复(移回到原有存储池)
[root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l [root@ceph-admin ~]# rbd trash ls ceph-rbdpool 149196b8b4567 vol01 [root@ceph-admin ~]# rbd trash restore --pool ceph-rbdpool --image-id 149196b8b4567 [root@ceph-admin ~]# rbd trash ls ceph-rbdpool [root@ceph-admin ~]# rbd ls -p ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK vol01 5 GiB 2 [root@ceph-admin ~]#
image快照
什么是快照呢?所谓快照我们可以理解为一种数据备份手段;做快照之所以快,是因为我们在做快照时不需要复制数据,只有数据发生改变时,对应快照才会把我们需要修改的数据复制到现有快照之上,然后再做修改;修改过后的数据会被保存到现有快照之上;对于原卷上的数据,是不会发生变化的;我们在读取没有发生变化的数据,是直接到原卷上读取;简单讲快照就是给原卷做了一层可写层,把原卷的内容保护起来,修改数据时,从原卷复制数据到快照,然后再修改,修改后的数据直接保存到快照,所以我们读取修改后的数据是直接读取快照上的数据;未修改的数据,访问还是直接到原卷访问;这也是为什么快照很快和快照比原卷小的原因;
创建快照命令格式: rbd snap create [--pool <pool>] --image <image> --snap <snap> 或者rbd snap create [<pool-name>/]<image-name>@<snapshot-name>
[root@ceph-admin ~]# mount /dev/rbd0 /mnt
[root@ceph-admin ~]# cd /mnt
[root@ceph-admin mnt]# ls
[root@ceph-admin mnt]# echo "hello ceph" >>test.txt
[root@ceph-admin mnt]# ls
test.txt
[root@ceph-admin mnt]# cat test.txt
hello ceph
[root@ceph-admin mnt]# rbd snap create ceph-rbdpool/vol01@vol01-snap
[root@ceph-admin mnt]# rbd snap list ceph-rbdpool/vol01
SNAPID NAME SIZE TIMESTAMP
4 vol01-snap 5 GiB Tue Oct 4 23:26:09 2022
[root@ceph-admin mnt]#
提示:我们把ceph上ceph-rbdpool存储池里的vol01映射到本地当作硬盘使用,格式化分区以后,将对应磁盘挂载到/mnt下,然后在/mnt下新建了一个test.txt的文件,然后在管理端给对应存储池里的image做了一个快照;这里需要注意的是在创建映像快照之前应停止image上的IO操作,且image上存在文件系统时,还要确保其处于一致状态;
在客户端上删除数据,并卸载磁盘和磁盘映射
[root@ceph-admin mnt]# ls test.txt [root@ceph-admin mnt]# cat test.txt hello ceph [root@ceph-admin mnt]# rm -rf test.txt [root@ceph-admin mnt]# ls [root@ceph-admin mnt]# cd [root@ceph-admin ~]# umount /mnt [root@ceph-admin ~]# rbd unmap /dev/rbd0 [root@ceph-admin ~]# rbd showmapped [root@ceph-admin ~]#
回滚快照
命令格式:rbd snap rollback [--pool <pool>] --image <image> --snap <snap> [--no-progress];
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
SNAPID NAME SIZE TIMESTAMP
4 vol01-snap 5 GiB Tue Oct 4 23:26:09 2022
[root@ceph-admin ~]# rbd snap rollback ceph-rbdpool/vol01@vol01-snap
Rolling back to snapshot: 100% complete...done.
[root@ceph-admin ~]#
提示:这里需要注意将映像回滚到快照意味着会使用快照中的数据重写当前版本的image,而且执行回滚所需的时间将随映像大小的增加而延长;
在客户端映射image,并挂载磁盘,看看对应数据是否恢复?
[root@ceph-admin ~]# rbd map --user test ceph-rbdpool/vol01 /dev/rbd0 [root@ceph-admin ~]# mount /dev/rbd0 /mnt [root@ceph-admin ~]# cd /mnt [root@ceph-admin mnt]# ls test.txt [root@ceph-admin mnt]#cat test.txt hello ceph [root@ceph-admin mnt]#
提示:可以看到现在再次挂载上磁盘,被删除的数据就被找回来了;
限制快照数量
命令格式:rbd snap limit set [--pool <pool>] [--image <image>] [--limit <limit>]
解除限制:rbd snap limit clear [--pool <pool>] [--image <image>]
[root@ceph-admin ~]# rbd snap limit set ceph-rbdpool/vol01 --limit 3 [root@ceph-admin ~]# rbd snap limit set ceph-rbdpool/vol01 --limit 5 [root@ceph-admin ~]# rbd snap limit clear ceph-rbdpool/vol01 [root@ceph-admin ~]#
提示:修改限制直接重新设置新的限制即可;
删除快照
命令格式:rbd snap rm [--pool <pool>] [--image <image>] [--snap <snap>] [--no-progress] [--force]
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
SNAPID NAME SIZE TIMESTAMP
4 vol01-snap 5 GiB Tue Oct 4 23:26:09 2022
[root@ceph-admin ~]# rbd snap rm ceph-rbdpool/vol01@vol01-snap
Removing snap: 100% complete...done.
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
[root@ceph-admin ~]#
提示:Ceph OSD会以异步方式删除数据,因此删除快照并不能立即释放磁盘空间;
清理快照:删除一个image的所有快照,可以使用rbd snap purge命令,格式如下
命令格式: rbd snap purge [--pool <pool>] --image <image> [--no-progress]
[root@ceph-admin ~]# rbd snap create ceph-rbdpool/vol01@vol01-snap
[root@ceph-admin ~]# rbd snap create ceph-rbdpool/vol01@vol01-snap2
[root@ceph-admin ~]# rbd snap create ceph-rbdpool/vol01@vol01-snap3
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
SNAPID NAME SIZE TIMESTAMP
6 vol01-snap 5 GiB Tue Oct 4 23:43:22 2022
7 vol01-snap2 5 GiB Tue Oct 4 23:43:30 2022
8 vol01-snap3 5 GiB Tue Oct 4 23:43:32 2022
[root@ceph-admin ~]# rbd snap purge ceph-rbdpool/vol01
Removing all snapshots: 100% complete...done.
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
[root@ceph-admin ~]#
快照分层
Ceph支持在一个块设备快照的基础上创建一到多个COW或COR(Copy-On-Read)类型的克隆,这种中间快照层(snapshot layering)机制提了一种极速创建image的方式;用户可以创建一个基础image并为其创建一个只读快照层,而后可以在此快照层上创建任意个克隆进行读写操作,甚至能够进行多级克隆;例如,实践中可以为Qemu虚拟机创建一个image并安装好基础操作系统环境作为模板,对其创建创建快照层后,便可按需创建任意多个克隆作为image提供给多个不同的VM(虚拟机)使用,或者每创建一个克隆后进行按需修改,而后对其再次创建下游的克隆;通过克隆生成的image在其功能上与直接创建的image几乎完全相同,它同样支持读、写、克隆、空间扩缩容等功能,惟一的不同之处是克隆引用了一个只读的上游快照,而且此快照必须要置于“保护”模式之下;COW是为默认的类型,仅在数据首次写入时才需要将它复制到克隆的image中;COR则是在数据首次被读取时复制到当前克隆中,随后的读写操作都将直接基于此克隆中的对象进行;有点类似虚拟机的链接克隆和完全克隆;

在RBD上使用分层克隆的方法非常简单:创建一个image,对image创建一个快照并将其置入保护模式,而克隆此快照即可;创建克隆的image时,需要指定引用的存储池、镜像和镜像快照,以及克隆的目标image的存储池和镜像名称,因此,克隆镜像支持跨存储池进行;
快照保护命令格式:rbd snap protect [--pool <pool>] --image <image> --snap <snap>
[root@ceph-admin ~]# rbd snap create ceph-rbdpool/vol01@vol01-snap3
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
SNAPID NAME SIZE TIMESTAMP
12 vol01-snap3 5 GiB Tue Oct 4 23:49:25 2022
[root@ceph-admin ~]# rbd snap protect ceph-rbdpool/vol01@vol01-snap3
[root@ceph-admin ~]#
克隆快照
命令格式:rbd clone [--pool <pool>] --image <image> --snap <snap> --dest-pool <dest-pool> [--dest <dest> 或者rbd clone [<pool-name>/]<image-name>@<snapshot-name> [<pool-name>/]<image-name>
[root@ceph-admin ~]# rbd clone ceph-rbdpool/vol01@vol01-snap3 ceph-rbdpool/image1 [root@ceph-admin ~]# rbd ls ceph-rbdpool image1 vol01 [root@ceph-admin ~]# rbd ls ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK image1 5 GiB ceph-rbdpool/vol01@vol01-snap3 2 vol01 5 GiB 2 vol01@vol01-snap3 5 GiB 2 yes [root@ceph-admin ~]#
提示:克隆快照,最终生成的是对应存储池里的image;所以我们需要指定对应目标的存储池和image名称;这里需要注意克隆快照,前提是快照需做保护,否则不予被克隆;
列出快照的子项
命令格式:rbd children [--pool <pool>] --image <image> --snap <snap>
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
SNAPID NAME SIZE TIMESTAMP
12 vol01-snap3 5 GiB Tue Oct 4 23:49:25 2022
[root@ceph-admin ~]# rbd children ceph-rbdpool/vol01@vol01-snap3
ceph-rbdpool/image1
[root@ceph-admin ~]#
展平克隆的image
克隆的映像会保留对父快照的引用,删除子克隆对父快照的引用时,可通过将信息从快照复制到克隆,进行image的“展平”操作;展平克隆所需的时间随着映像大小的增加而延长;要删除某拥有克隆子项的快照,必须先平展其子image;命令格式: rbd flatten [--pool <pool>] --image <image> --no-progress
[root@ceph-admin ~]# rbd ls ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK image1 5 GiB ceph-rbdpool/vol01@vol01-snap3 2 vol01 5 GiB 2 vol01@vol01-snap3 5 GiB 2 yes [root@ceph-admin ~]# rbd flatten ceph-rbdpool/image1 Image flatten: 100% complete...done. [root@ceph-admin ~]# rbd ls ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK image1 5 GiB 2 vol01 5 GiB 2 vol01@vol01-snap3 5 GiB 2 yes [root@ceph-admin ~]# rbd children ceph-rbdpool/vol01@vol01-snap3 [root@ceph-admin ~]#
提示:可以看到我们把子镜像进行展品操作以后,对父镜像的信息就没了;查看对应快照的子项也没有了;这意味着现在展品的子镜像是一个独立的镜像;
取消快照保护
命令格式:命令:rbd snap unprotect [--pool <pool>] --image <image> --snap <snap>
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
SNAPID NAME SIZE TIMESTAMP
12 vol01-snap3 5 GiB Tue Oct 4 23:49:25 2022
[root@ceph-admin ~]# rbd snap rm ceph-rbdpool/vol01@vol01-snap3
Removing snap: 0% complete...failed.
rbd: snapshot 'vol01-snap3' is protected from removal.
2022-10-05 00:05:04.059 7f5e35e95840 -1 librbd::Operations: snapshot is protected
[root@ceph-admin ~]# rbd snap unprotect ceph-rbdpool/vol01@vol01-snap3
[root@ceph-admin ~]# rbd snap rm ceph-rbdpool/vol01@vol01-snap3
Removing snap: 100% complete...done.
[root@ceph-admin ~]# rbd snap list ceph-rbdpool/vol01
[root@ceph-admin ~]#
提示:被保护的快照是不能被删除的必须先取消保护快照,然后才能删除它;其次用户无法删除克隆所引用的快照,需要先平展其每个克隆,然后才能删除快照;
KVM使用rbd image
1、准备kvm环境,在kvm宿主机上除了安装ceph-common和epel源之外,我们还需要安装安装libvirt与qemu-kvm;
yum install qemu-kvm qemu-kvm-tools libvirt virt-manager virt-install
提示:我这里直接使用adminhost来做kvm宿主机,所以ceph-common、epel源都是准备好的,只需安装qemu-kvm qemu-kvm-tools libvirt virt-manager virt-install即可;
2、启动libvirtd守护进程
[root@ceph-admin ~]# systemctl start libvirtd
[root@ceph-admin ~]# systemctl status libvirtd -l
● libvirtd.service - Virtualization daemon
Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-10-05 01:27:34 CST; 1min 32s ago
Docs: man:libvirtd(8)
https://libvirt.org
Main PID: 940 (libvirtd)
Tasks: 19 (limit: 32768)
CGroup: /system.slice/libvirtd.service
├─ 940 /usr/sbin/libvirtd
├─1237 /usr/sbin/dnsmasq --conf-file=/var/lib/libvirt/dnsmasq/default.conf --leasefile-ro --dhcp-script=/usr/libexec/libvirt_leaseshelper
└─1238 /usr/sbin/dnsmasq --conf-file=/var/lib/libvirt/dnsmasq/default.conf --leasefile-ro --dhcp-script=/usr/libexec/libvirt_leaseshelper
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq[1232]: listening on virbr0(#3): 192.168.122.1
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq[1237]: started, version 2.76 cachesize 150
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq[1237]: compile time options: IPv6 GNU-getopt DBus no-i18n IDN DHCP DHCPv6 no-Lua TFTP no-conntrack ipset auth nettlehash no-DNSSEC loop-detect inotify
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq-dhcp[1237]: DHCP, IP range 192.168.122.2 -- 192.168.122.254, lease time 1h
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq-dhcp[1237]: DHCP, sockets bound exclusively to interface virbr0
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq[1237]: reading /etc/resolv.conf
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq[1237]: using nameserver 192.168.0.1#53
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq[1237]: read /etc/hosts - 15 addresses
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq[1237]: read /var/lib/libvirt/dnsmasq/default.addnhosts - 0 addresses
Oct 05 01:27:35 ceph-admin.ilinux.io dnsmasq-dhcp[1237]: read /var/lib/libvirt/dnsmasq/default.hostsfile
[root@ceph-admin ~]#
提示:启动libvirtd之前,需要先确定对应主机是否启用了kvm模块,其次对应主机的cpu是否开启了虚拟化;或者看上面的启动日志里是否有错误,没有错误说明libvirtd正常工作;
3、在ceph集群上授权相关用户账号
[root@ceph-admin ~]# ceph auth get-or-create client.libvirt mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=ceph-rbdpool'
[client.libvirt]
key = AQBIXTxjpeYoAhAAw/ZMROyxd3E0b8i3xlOkgw==
[root@ceph-admin ~]# ceph auth get client.libvirt
exported keyring for client.libvirt
[client.libvirt]
key = AQBIXTxjpeYoAhAAw/ZMROyxd3E0b8i3xlOkgw==
caps mon = "allow r"
caps osd = "allow class-read object_prefix rbd_children, allow rwx pool=ceph-rbdpool"
[root@ceph-admin ~]#
4、将client.libvirt用户信息导入为libvirtd上的一个secret
4.1、先创建一个xml文件
[root@ceph-admin ~]# cat client.libvirt-secret.xml
<secret ephemeral='no' private='no'>
<usage type='ceph'>
<name>client.libvirt secret</name>
</usage>
</secret>
[root@ceph-admin ~]#
4.2、用virsh命令创建此secret,命令会返回创建的secret的UUID
[root@ceph-admin ~]# virsh secret-define --file client.libvirt-secret.xml Secret 92897e61-5935-43ad-abd6-9f97a5652f05 created [root@ceph-admin ~]#
提示:上述步骤是生成一个libvirt在ceph之上用于认证时存储密钥的secret;里面只包含了类型为ceph和secret的说明;
5、将ceph的client.libvirt的密钥导入到刚创建的secret
[root@ceph-admin ~]# virsh secret-set-value --secret 92897e61-5935-43ad-abd6-9f97a5652f05 --base64 $(ceph auth get-key client.libvirt) Secret value set [root@ceph-admin ~]# virsh secret-get-value --secret 92897e61-5935-43ad-abd6-9f97a5652f05 AQBIXTxjpeYoAhAAw/ZMROyxd3E0b8i3xlOkgw== [root@ceph-admin ~]# ceph auth print-key client.libvirt AQBIXTxjpeYoAhAAw/ZMROyxd3E0b8i3xlOkgw==[root@ceph-admin ~]#
提示:上述步骤是将ceph授权的用户密钥和secret做绑定,并生成一个在libvirt中用于在ceph之上认证的screct,即libvirt拿着这个screct到ceph集群上做认证;这里面就包含cpeh授权的账号密码信息;
6、准备image
[root@ceph-admin ~]# ls CentOS-7-x86_64-Minimal-1708.iso client.abc.keyring client.libvirt-secret.xml ceph-deploy-ceph.log client.admin.cluster.keyring client.test.keyring centos7.xml client.admin.keyring client.usera.keyring [root@ceph-admin ~]# rbd ls ceph-rbdpool image1 test vol01 [root@ceph-admin ~]# rbd import ./CentOS-7-x86_64-Minimal-1708.iso ceph-rbdpool/centos7 Importing image: 100% complete...done. [root@ceph-admin ~]# rbd ls ceph-rbdpool -l NAME SIZE PARENT FMT PROT LOCK centos7 792 MiB 2 image1 5 GiB 2 test 5 GiB ceph-rbdpool/vol01@vol01-snap3 2 vol01 5 GiB 2 vol01@vol01-snap3 5 GiB 2 yes [root@ceph-admin ~]#
提示:我这里是为了方便测试,直接将centos7导入的ceph-rbdpool存储池里;
7、创建VM
[root@ceph-admin ~]# cat centos7.xml
<domain type='kvm'>
<name>centos7</name>
<memory>131072</memory>
<currentMemory unit='KiB'>65536</currentMemory>
<vcpu>1</vcpu>
<os>
<type arch='x86_64'>hvm</type>
</os>
<clock sync="localtime"/>
<devices>
<emulator>/usr/libexec/qemu-kvm</emulator>
<disk type='network' device='disk'>
<source protocol='rbd' name='ceph-rbdpool/centos7'>
<host name='192.168.0.71' port='6789'/>
</source>
<auth username='libvirt'>
<secret type='ceph' uuid='92897e61-5935-43ad-abd6-9f97a5652f05'/>
</auth>
<target dev='vda' bus='virtio'/>
</disk>
<interface type='network'>
<mac address='52:54:00:25:c2:45'/>
<source network='default'/>
<model type='virtio'/>
</interface>
<serial type='pty'>
<target type='isa-serial' port='0'>
<model name='isa-serial'/>
</target>
</serial>
<console type='pty'>
<target type='virtio' port='0'/>
</console>
<graphics type='vnc' port='-1' autoport='yes'>
<listen type='address' address='0.0.0.0'/>
</graphics>
</devices>
</domain>
[root@ceph-admin ~]#
提示:上述是创建VM的配置文件,我们在里面定义好磁盘设备相关信息和其他信息就可以根据这个配置文件创建一个符合我们定义在配置文件中内容的VM;
创建虚拟机
[root@ceph-admin ~]# virsh define centos7.xml Domain centos7 defined from centos7.xml [root@ceph-admin ~]#
查看虚拟机
[root@ceph-admin ~]# virsh list --all Id Name State ---------------------------------------------------- - centos7 shut off [root@ceph-admin ~]#
启动虚拟机
[root@ceph-admin ~]# virsh start centos7 Domain centos7 started [root@ceph-admin ~]# virsh list --all Id Name State ---------------------------------------------------- 2 centos7 running [root@ceph-admin ~]#
查看虚拟机磁盘
[root@ceph-admin ~]# virsh domblklist centos7 Target Source ------------------------------------------------ vda ceph-rbdpool/centos7 [root@ceph-admin ~]#
提示:这里可以看到对应虚拟机的磁盘已经成功加载;
查看kvm宿主机端口,看看对应vnc端口是否监听?
[root@ceph-admin ~]# ss -tnl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 5 192.168.122.1:53 *:* LISTEN 0 128 *:22 *:* LISTEN 0 100 127.0.0.1:25 *:* LISTEN 0 1 *:5900 *:* LISTEN 0 128 *:111 *:* LISTEN 0 128 [::]:22 [::]:* LISTEN 0 100 [::1]:25 [::]:* LISTEN 0 128 [::]:111 [::]:* [root@ceph-admin ~]#
提示:vnc监听在宿主机的5900端口,如果有多台虚拟机都启用了vnc,那么对应第二台虚拟机就监听在5901端口,依次类推;
连接kvm宿主机的vnc端口,看看对应虚拟机启动情况
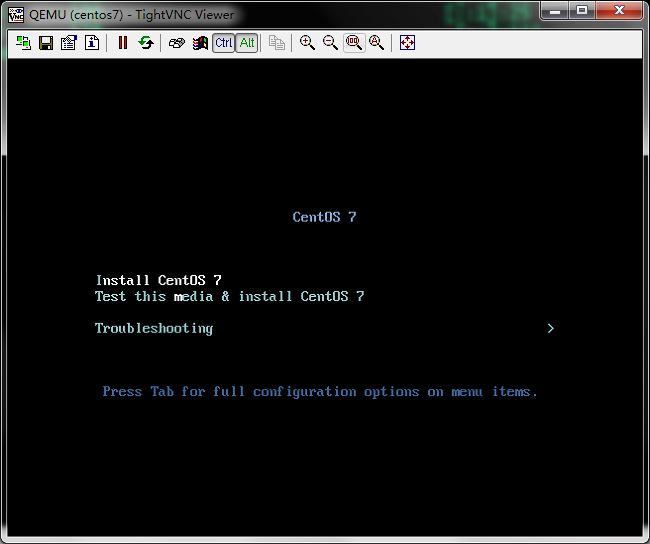
提示:可以看到我们刚才导入ceph-rbdpool的镜像,现在已被kvm虚拟机正常加载,并读取到内容;ok,到此kvm使用rbd image的测试就完成了;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号