

数据可视化实例(七): 计数图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter5/chapter5
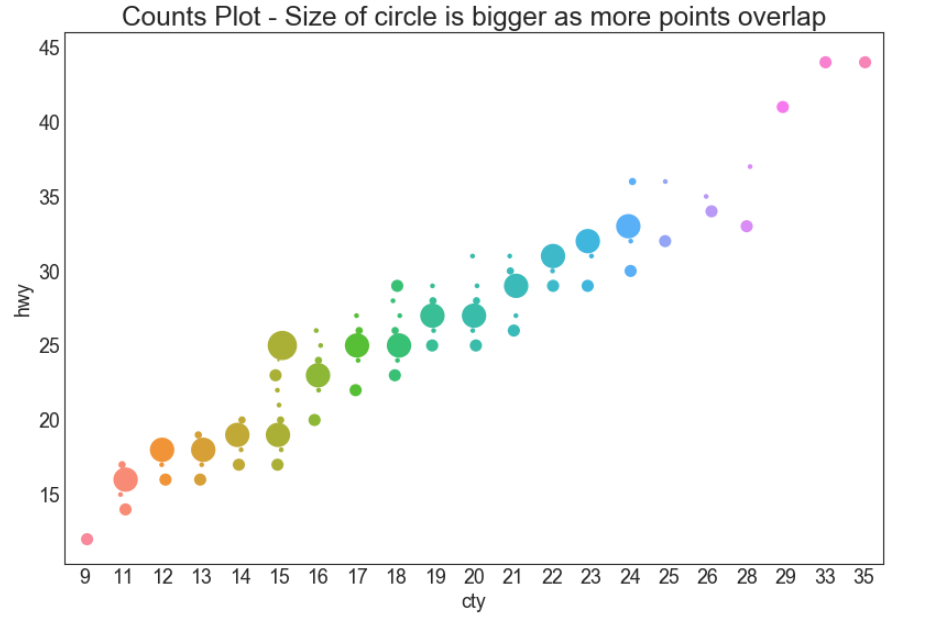
计数图 (Counts Plot)
避免点重叠问题的另一个选择是增加点的大小,这取决于该点中有多少点。 因此,点的大小越大,其周围的点的集中度越高。
导入所需要的库
import numpy as np # 导入pandas库 import pandas as pd # 导入matplotlib库 import matplotlib as mpl import matplotlib.pyplot as plt # 导入seaborn库 import seaborn as sns # 在jupyter notebook显示图像 %matplotlib inline
设定图像各种属性
large = 22; med = 16; small = 12
# 设置子图上的标题字体
params = {'axes.titlesize': large,
# 设置图例的字体
'legend.fontsize': med,
# 设置图像的画布
'figure.figsize': (16, 10),
# 设置标签的字体
'axes.labelsize': med,
# 设置x轴上的标尺的字体
'xtick.labelsize': med,
# 设置整个画布的标题字体
'ytick.labelsize': med,
'figure.titlesize': large}
# 更新默认属性
plt.rcParams.update(params)
# 设定整体风格
plt.style.use('seaborn-whitegrid')
# 设定整体背景风格
sns.set_style("white")
# step1:导入数据
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") # groupby__可对具有相同'hwy','cty'进行分组 # size__返回元素的数量 # reset_index__重新设置连续的行索引index # name_计数的列名 df_counts = df.groupby(['hwy', 'cty']).size().reset_index(name = 'counts')
# step2:绘画 Stripplot
# 设置画布 fig, ax = plt.subplots(figsize = (12, 8), dpi = 80) # 横坐标 sns.stripplot(df_counts.cty, # 纵坐标 df_counts.hwy, # 尺寸 size = df_counts.counts * 2, # 子图 ax = ax)
# step3:装饰
# 添加标题 plt.title('Counts Plot - Size of circle is bigger as more points overlap', fontsize=22) # 显示图像 plt.show()
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=True, dodge=False, orient=None, color=None, palette=None, size=5, edgecolor='gray', linewidth=0, ax=None, **kwargs)
绘制一个散点图,其中一个变量是分类。
条形图可以单独绘制,但如果您想要显示所有观察结果以及底层分布的某些表示,它也是一个盒子或小提琴图的良好补充。
输入数据可以以多种格式传递,包括:
- 表示为列表,numpy数组或pandas Series对象的数据向量直接传递给
x,y和hue参数 - 在这种情况下,
x,y和hue变量将决定数据的绘制方式。 - “wide-form” DataFrame, 用于绘制每个数字列。
- 一个数组或向量列表。
在大多数情况下,可以使用numpy或Python对象,但最好使用pandas对象,因为关联的名称将用于注释轴。另外,您可以使用分组变量的分类类型来控制绘图元素的顺序。
此函数始终将其中一个变量视为分类,并在相关轴上的序数位置(0,1,... n)处绘制数据,即使数据具有数字或日期类型也是如此。
有关更多信息,请参阅教程。
参数:x, y, hue: 数据或矢量数据中的变量名称,可选
用于绘制长格式数据的输入。查看解释示例。
data:DataFrame, 数组, 数组列表, 可选
用于绘图的数据集。如果
x和y不存在,则将其解释为宽格式。否则预计它将是长格式的。
order, hue_order:字符串列表,可选
命令绘制分类级别,否则从数据对象推断级别。
jitter:float, True/1 是特殊的,可选
要应用的抖动量(仅沿分类轴)。 当您有许多点并且它们重叠时,这可能很有用,因此更容易看到分布。您可以指定抖动量(均匀随机变量支持的宽度的一半),或者仅使用
True作为良好的默认值
dodge:bool, 可选
使用
hue嵌套时,将其设置为True将沿着分类轴分离不同色调级别的条带。否则,每个级别的点将相互叠加。
orient:“v” | “h”, 可选
图的方向(垂直或水平)。这通常是从输入变量的dtype推断出来的,但可用于指定“分类”变量何时是数字或何时绘制宽格式数据。
color:matplotlib颜色,可选
所有元素的颜色,或渐变调色板的种子。
palette:调色板名称,列表或字典,可选
用于色调变量的不同级别的颜色。应该是
color_palette(), 可以解释的东西,或者是将色调级别映射到matplotlib颜色的字典。
size:float, 可选
标记的直径,以磅为单位。(虽然
plt.scatter用于绘制点,但这里的size参数采用“普通”标记大小而不是大小^ 2,如plt.scatter。
edgecolor:matplotlib颜色,“灰色”是特殊的,可选的
ax:matplotlib轴,可选
返回Axes对象,并在其上绘制绘图。
返回值:ax:matplotlib轴
返回Axes对象,并在其上绘制绘图。
也可参看
分类散点图,其中点不重叠。可以与其他图一起使用来显示每个观察结果。带有类似API的传统盒须图。箱形图和核密度估计的组合。
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/12873356.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号