

scrapy 基础组件专题(三):爬虫中间件
一、爬虫中间件简介
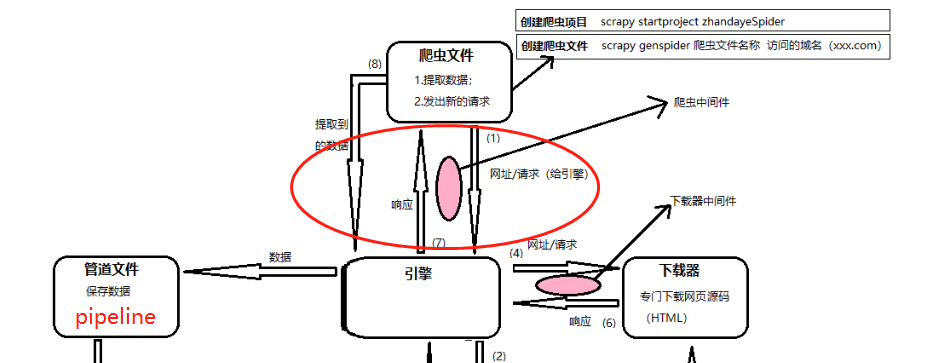
图 1-1

图 1-2
开始这一张之前需要先梳理一下这张图, 需要明白下载器中间件和爬虫中间件所在的位置
- 下载器中间件是在引擎(ENGINE)将请求推送给下载器(DOWNLOADER)时会执行到的
- 当下载器(DOWNLOADER)完成下载后, 将下载的Response对象传回给引擎(ENGLIE)时也会经过下载器中间件
- 当爬虫(SPIDER)把任务给引擎(ENGINE)的时候, 会经过爬虫中间件
- 当引擎(ENGINE)把数据传回给爬虫(SPIDER)的时候, 会经过爬虫中间件
此外:
图1-2中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
- 当运行到
yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。 - 当爬虫本身的代码出现了
Exception的时候,爬虫中间件的process_spider_exception()方法被调用。 - 当爬虫里面的某一个回调函数
parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。 - 当运行到
start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。
所以, 下载器中间件是引擎和下载器之间处理数据所使用的, 爬虫中间件是爬虫和引擎之间处理数据时使用的
二、爬虫中间件类与方法
process_spider_input(response,spider)
当response通过spider中间件时,该方法被调用,处理该response。
应该返回一个None或者抛出一个异常(exception)。
- 如果其返回None,Scrapy将会继续处理该response,调用所有其他中间件直到spider处理该response。
- 如果其抛出一个异常(exception),Scrapy将不会调用任何其他中间件的process_spider_input()方法,并调用request的errback。errback的输出将会以另一个方向被输入到中间链中,使用
process_spider_output()方法来处理,当其抛出异常时则带调用process_spider_exception()。
参数:
response(Response对象) - 被处理的response
spider(Spider对象) - 该response对应的spider
process_spider_out(response, result, spider)当Spider处理response返回result时,该方法被调用。(即spider处理response返回结果后)
process_spider_output()必须返回包含Request或Item对象的可迭代对象(iterable)。
response(Response对象) - 生成该输出的response
result(包含Reques或Item对象的可迭代对象(iterable)) - spider返回的result
spider(Spider对象) - 其结果被处理的spider
process_spider_exception(response, exception, spider)当spider或(其它spider中间件的)process_spider_input()抛出异常时,该方法被调用
process_spider_exception()必须要么返回None,要么返回一个包含Response或Item对象的可迭代对象(iterable)。
通过其返回None,Scrapy将继续处理该异常,调用中间件链中的其它中间件的process_spider_exception()
如果其返回一个可迭代对象,则中间件链的process_spider_output()方法被调用,其他的process_spider_exception()将不会被调用。
response(Response对象) - 异常被抛出时被处理的response
exception(Exception对象) - 被抛出的异常
spider(Spider对象) - 抛出异常的spiderprocess_start_requests(start_requests, spider)
该方法以spider启动的request为参数被调用,执行的过程类似于process_spider_output(),只不过其没有相关联的response并且必须返回request(不是item)。
其接受一个可迭代的对象(start_requests参数)且必须返回一个包含Request对象的可迭代对象。
当在您的spider中间件实现该方法时,您必须返回一个可迭代对象(类似于参数start_requests)且不要遍历所有的start_requests。
该迭代器会很大(甚至是无限),进而导致内存溢出。
Scrapy引擎再其具有能力处理start_requests时将会拉起request,因此start_requests迭代器会变得无限,而由其它参数来停止spider(例如时间限制或者item/page计数)。
参数:
start_requests(b包含Request的可迭代对象)
- start requests
spider(Spider对象)
- start request所属的spider
三、编写自己的爬虫中间件
编写一个简单的爬虫, 实现两个需求
- 将所有返回的Response(响应)的响应码改为500
- 统计解析出来的item的数量
# spider.py # -*- coding: utf-8 -*- import scrapy from ccidcom.items import CcidcomItem class CcidcomspiderSpider(scrapy.Spider): name = 'ccidcomSpider' def start_requests(self): self.logger.info('-----------spider.start_requests----------') yield scrapy.Request('http://www.ccidcom.com/yaowen/index.html') def parse(self, response): self.logger.info('--------spider.parse--------') article_list = response.css('div.article-item') for article in article_list: item = CcidcomItem() item['title'] = article.css('a font::text').get() item['url'] = response.url yield item def parse_baidu(self, response): pass # items.py import scrapy class CcidcomItem(scrapy.Item): title = scrapy.Field() url = scrapy.Field()
编写爬虫中间件
# middlewares.py from scrapy import signals from ccidcom.items import CcidcomItem class CcidcomSpiderMiddleware(object): item_number = 0 ... def process_spider_input(self, response, spider): spider.logger.info('--------spider_input-----------') # 将响应码强制改为500 response.status = 500 return None def process_spider_output(self, response, result, spider): spider.logger.info('--------spider_output-start-----------') for i in result: if type(i) == CcidcomItem: self.item_number += 1 yield i spider.logger.info('--------spider_output-end-----------') spider.logger.info('item抓取到的数量:{}'.format(self.item_number)) def process_spider_exception(self, response, exception, spider): pass def process_start_requests(self, start_requests, spider): spider.logger.info('--------start_requests-----------') for r in start_requests: yield r ...
启用爬虫中间件
# settings.py SPIDER_MIDDLEWARES = { 'ccidcom.middlewares.CcidcomSpiderMiddleware': 543, }
执行的顺序
- 1.爬虫中间件的
process_start_requests方法 - 2.爬虫的
start_requests方法 - 3.爬虫中间件的
process_spider_input方法 - 4.爬虫中间件的
process_spider_output方法 - 5.爬虫的
parse方法 - 6.爬虫中间件的
process_spider_output方法
好像有点乱, 为啥process_spider_output会被运行了两次呢?而且还是第一次只输出了spider_output-start, 最后才输出了spider_output-end?
其实咱们跟着代码走一遍,就很好理解了
- 代码执行到了爬虫中间件的
process_start_requests方法, 输出了start_requests, 但是参数start_requests其实是spider的start_requests方法的生成器, 所以只有执行到for r in start_requests, 才真正开始执行spider的start_requests方法 - 交给下载器完成下载
- 下载后引擎将Response传给爬虫中间件的
process_spider_input方法 process_spider_input方法会调用process_spider_output方法, 并且将发起请求时Request的callback指定的方法, 变为process_spider_output的result参数, 这时也输出了spider_output-start- 当
process_spider_output方法运行到for i in result:时, 则真正开始执行Request对象指定的callback方法, 并且变为了生成器, yield回引擎 - 当
process_spider_output执行完result后, 就输出了spider_output-end.
以上就是整个爬虫中间件的运行流程。
# middlewares.py from scrapy import signals from ccidcom.items import CcidcomItem class CcidcomSpiderMiddleware(object): item_number = 0 ... def process_spider_input(self, response, spider): spider.logger.info('--------spider_input-----------') # 将响应码强制改为500 response.status = 500 return None def process_spider_output(self, response, result, spider): spider.logger.info('--------spider_output-start-----------') for i in result: if type(i) == CcidcomItem: self.item_number += 1 yield i spider.logger.info('--------spider_output-end-----------') spider.logger.info('item抓取到的数量:{}'.format(self.item_number)) def process_spider_exception(self, response, exception, spider): pass def process_start_requests(self, start_requests, spider): spider.logger.info('--------start_requests-----------') for r in start_requests: yield r ...
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/12638436.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号