
Pytorch 第一个程序
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets #这里指定当前数据集为torchvision
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as plt1. DataLoader
是Pytorch用来加载数据的常用的类,返回一个可遍历的数据集对象
传入参数:
-
dataset (Dataset) – dataset from which to load the data.
-
batch_size (int, optional) – how many samples per batch to load (default:
1). -
shuffle (bool, optional) – set to
Trueto have the data reshuffled at every epoch (default:False)
2. torchvision
是一个包,里面包含了很多常用的视觉数据集。类似的还有torchtext, torchaudio,...
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data", # 指定保存数据集文件夹路径
train=True, # 指定是否是训练数据集
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)1. torchvision.datasets里的所有datasets(这里是FashionMNIST)都是torch.utils.data.Dataset的子类,因为这些子类都写了__getitem__和__len__,所以可以被传入torch.utils.data.DataLoader。
2. FashionMNIST的属性有:
-
root (string) – Root directory of dataset where
FashionMNIST/processed/training.ptandFashionMNIST/processed/test.ptexist. -
train (bool, optional) – If True, creates dataset from
training.pt, otherwise fromtest.pt. -
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
-
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g,
transforms.RandomCrop
3. torchvision.transforms.ToTensor()
把图片库(PIL)里的图片或者numpy数组转化成tensor.
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1) or if the numpy.ndarray has dtype = np.uint8
for i in test_data:
print(len(i),type(i)) # 查看一条数据的样子,类型
print(i[1],type(i[1])) # 查看这一条数据里,标签的值和数据类型
print(type(i[0]),i[0].shape,i[0]) #查看这一条数据里,数据的数据类型,形状,数据本身
break这段代码查看数据集里每一条数据是什么样,结果如下:
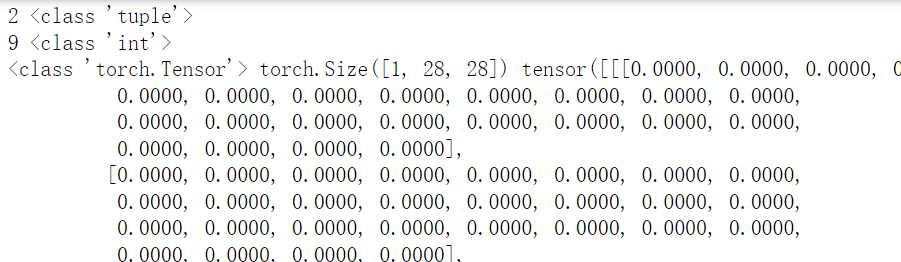
1. 每一条数据是有两个元素的元组, 第一个元素是数据,第二个元素是标签
2. 数据(i[0])的type是tensor,shape是 [1,28,28],说明是一张28*28像素的灰度 ([1,28,28]里的1) 图片; 标签是int的9,说明这个图片代表9
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
print('type of dataloader:',type(test_dataloader),'\n')
print('test data has',len(test_data),'items') # 测试集有多少条数据
print('test dataloader has',len(test_dataloader),'items','\n') # 测试集的dataloader有多少条数据
for x,y in test_dataloader:
print('type of items in dataloader:',type(x))
print('shape of x:', x.shape, type(x))
print('shape of y:', y.shape, type(y))
break结果如下:
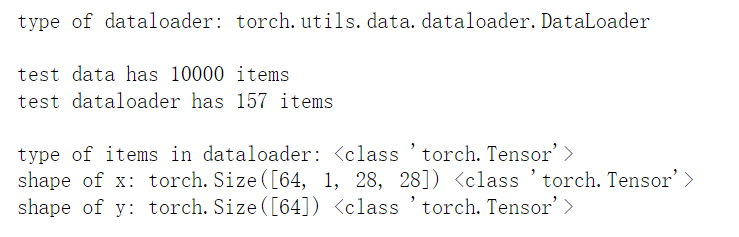
1. 把datasets.FashionMNIST数据集里的每一个数据,按64个为一批次,每次打包64个数据作为一整个数据塞进DataLoader,
我们可以看到原始测试集有10000条数据,经过64个包装成一批之后,到dataloader里成了157批 (157*64 = 10048)
也就是说,dataloader里每一个item都是64条原始数据。因此x的形状是[64,1,28,28],64个图像数据;y的形状是[64], 64个标签。
class DNN(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28,512),
nn.ReLU(),
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512,10),
nn.ReLU()
)
def forward(self,x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = DNN().to('cpu')
print(model)一、def __init__(self)
1. Pytorch里定义一个神经网络的类,都要继承于nn.Module,这个nn.Module是所有神经网络模型(包括自带的nn.Sequential(), nn.Conv2d, nn.Flatten, nn.ReLU, nn.Linear...和自己编写的神经网络模型类)的基类。
2. nn.Flatten()用于创建一个flatten层,将维度轴上所有的数,展平成一个一维tensor,例如[[[1,2],[3,4]],[[5,6],[7,8]]] --> [1,2,3,4,5,6,7,8]。
3. nn.Linear()用于创建一个全链接层(密集连接层)。全连接层的输出是一个向量(一维tensor)
4. nn.ReLU()用于创建一个线性整流层,是激活函数。
5. 也可以写成这样,所有的层都放sequential:
class DNN(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28,512),
nn.ReLU(),
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512,10),
nn.ReLU()
)
def forward(self,x):
logits = self.net(x)
return logits二、def forward(self, x)
1. forward():在nn.Module类里被定义,子类重写此方法,此方法表示前向传播的过程。注意这个方法必须被重写!!!因为在__call__()里会用到
2. 传入参数为x,self.flatten, self.linear_relu_stack都是__init__里定义的两个实例变量,但是在这里却像函数一样被调用,被给予传入参数x,是因为self.flatten, self.linear_relu_stack这两个实例是callable的,由于其对应的类Flatten, Sequence定义了__call__()方法。(参照第一种写法)
三、写好这段之后就建立好了一个计算图,并且这个结构可以复用多次。
四、print(model)

def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch,(X,y) in enumerate(dataloader):
X,y = X.to('cpu'),y.to('cpu')
# compute predicted y and loss
pred = model(X)
loss = loss_fn(pred,y)
# back propagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# show the loss every 100 batches
if batch % 100 == 0:
loss, current = loss.item(), batch*len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")1. len(dataloader.dataset) 返回的是:所有的批次里所有的数据点有几个

2. enumerate(dataloader)
返回类似 [(0,(Tensor1, 9)), (1,(Tensor2, 0), ..., (n, (Tensorn+1, 8))] 这种结构的数据
所以batch对应着当前是第几个batch, (X,y)对应着(Tensor, label)
3. torch.Tensor.to(device)
如果当前的tensor已经有正确的torch.dtype和torch.device,那么to()仍然返回当前这个tensor对象;否则返回符合torch.dtype,torch.device规定的tensor.
4. 给这个callable的model传入参数X(用于训练的train_dataloader里的一个mini batch)
5. loss_fn是传入参数,传入的一个nn.XXXX(例如nn.CrossEntropyLoss)类的实例 (一个损失函数对象)。
6. optimizer.zero_grad() 优化器对象的zero_grad()方法,会设置所有参数的梯度初始值为0,因为一个batch的loss关于W的导数是这个batch里所有数据点的loss关于W的导数的累加和。d(W)/d(X) = d(W)/d(x1)+...+ d(W)/d(xn),所以要设置d(W)/d(X)初始值为0,从0开始加。
7. loss.backward() 反向传播,自动求导,计算梯度(loss这个对象在创建的时候(loss = loss_fn(pred, y) # pred = model(X))会有传入参数,指定对哪个model求模型参数梯度,model里的参数tensor应该都被写了requires_grad = True)
8. optimizer.step() 更新一次参数: $W^{(i+1)}=W^{(i)}-\eta \nabla e_{0(W)}$
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")1. model.eval() 相当于 model.train(False) 设置当前model模式为evaluation模式(测试模式),因为有一些层(如Dropout, BN)在训练和测试的时候是不一样的。只是不进行反向传播,但是没有禁用autograd
2. with torch.no_grad(): 用于停止autograd工作,从而节省了GPU算力和显存,但是并不会影响dropout和BN层的行为。
3. loss_fn(pred, y).item() 返回一个python float数据(值就是损失值),特别注意,除了loss.backward()以外,获取loss数值的时候最好都用loss.item(),详情可见this
4. correct += (pred.argmax(1) == y).type(torch.float).sum().item()
如果按这种形式“torch.argmax(input, dim, keepdim=False)”写的话,就是"torch.argmax(pred, dim=1)"
dim这个参数可以有两个值0,1:0是按照列,1是按照行;作为argmax的传入参数,dim=1代表按行选出最大值所在的列
示意图如下,图里pred那边数字代表index,y的数字是不同类别经过map之后的标签(0,1,2,...)
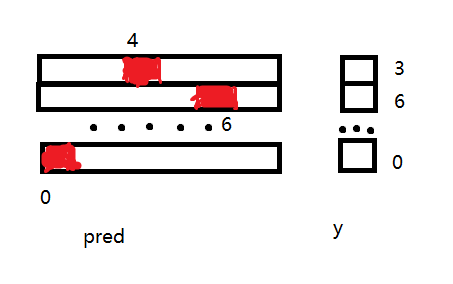
因此当前代码里的pred.argmax(1) 会返会类似Tensor([4,6,...,0])的Tensor,而y也是类似形状的tensor,因此二者可以用==比较。
这个条件表达式的返回值类似Tensor([False,True,...,True]),里面全是布尔值,每个位置的布尔值是pred和y对应位置元素做==运算的结果,因此里面有几个True,就说明所有测试数据里预测对了多少个。
.type(torch.float)将tensor里的布尔值转换成tensor.float,然后.sum()加起来,.item()只获取值,最后correct变量里存的就是测试集里正确预测的数据点个数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号