
文本向量化笔记(二)
神经网络语言模型是经典的三层前馈神经网络结构,其中包括三层:输入层、隐藏层和输出层。
为解决词袋模型数据稀疏问题,输入层的输入为低维度的、紧密的词向量,输入层的操作就是将词序列中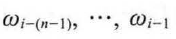 的每个词向量按顺序拼接,
的每个词向量按顺序拼接,

在输入层得到式( 7.2 )的x 后,将x 输入隐藏层得到h , 再将h 接人输出层得到最后的输出变量y , 隐藏层变量h 和输出变量y 的计算如下二式所示:

上式中H 为输入层到隐藏层的权重矩阵,其维度为 ;U 为隐藏层到输出层的权重矩阵,其维度为
;U 为隐藏层到输出层的权重矩阵,其维度为 ,|V|问表示词表的大小,其他绝对值符号类似;
,|V|问表示词表的大小,其他绝对值符号类似;
b 为模型中的偏置项。
NNLM 模型中计算量最大的操作就是从隐藏层到输出层的矩阵运算Uh 。
输出变量y 是一个|V|维的向量,该向量的每一个分量依次对应下一个词为词表中某个词的可能性。
用y(ω) 表示由NNLM 模型计算得到的目标词ω 的输出量,为保证输出y(ω)的表示概率值,需要对输出层进行归一化操作。
一般会在输出层之后加入softmax 函数,将y 转成对应的概率值,具体如式所示:
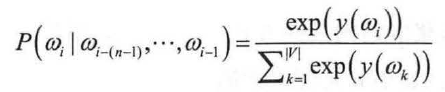
由于NNLM 模型使用低维紧凑的词向量对上文进行表示,这解决了词袋模型带来的数据稀疏飞语义鸿沟等问题,显然NNLM 模型是一种更好的n 元语言模型;
另一方面,在相似的上下文语境中, NNLM 模型可以预测出相似的目标词,而传统模型无法做到这一点。
例如,在某语料中A = "一只小狗躺在地毯上"出现了2000 次,而B="一只猫躺在地毯上"出现了1 次。根据频率来计算概率, P(A) 要远远大于P(B) ,而语料A 和B唯一的区别在于猫和狗,这两个词无论在词义和语法上都相似,而P(A) 远大于P(B) 显然是不合理的。
如果采用NNLM 计算则得到的P(A) 和P(B) 是相似的,这因为NNLM模型采用低维的向量表示词语,假定相似的词其词向量也应该相似;
如前所述,输出的y(ωi) 代表上文出现词序列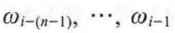 的情况下,下一个词为ωi 的概率,因此在语料库D中最大化y(ωi) 便是NNLM 模型的目标函数,如式所示:
的情况下,下一个词为ωi 的概率,因此在语料库D中最大化y(ωi) 便是NNLM 模型的目标函数,如式所示:
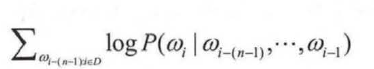
一般使用随机梯度下降算法对NNLM 模型进行训练。在训练每个batch 时,随机从语料库D 中抽取若干样本进行训练,梯度迭代公式如式所示:
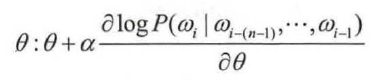
其中, α 是学习率; e 是模型中涉及的所有参数,包括NNLM 模型中的权重、偏置以及输入的词向量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号