
【深度学习数学基础:线性代数】2. 矩阵的重要数值量
2. 矩阵的重要数值量
2.1 行列式
行列式是表现矩阵特性的重要数值量之一,矩阵\(\boldsymbol{A}\)的行列式记作\(|\boldsymbol{A}|\)或\(\det(\boldsymbol{A})\),让可以是正的,负的或者是0,只有方阵才有行列式,行列式计算的标准方法需要用到代数余子式(上节课说过),其计算量大的惊人。一个\(25\times 25\)型方阵,若用每秒运行1万亿次乘法的超计算机来求,大概需要50万年才能求出其行列式的值。但是我们有很多快速计算方法。
- 行列式通过矩阵的代数余余子式计算得到,最简单的\(2\times 2\)型矩阵的行列式计算:
-
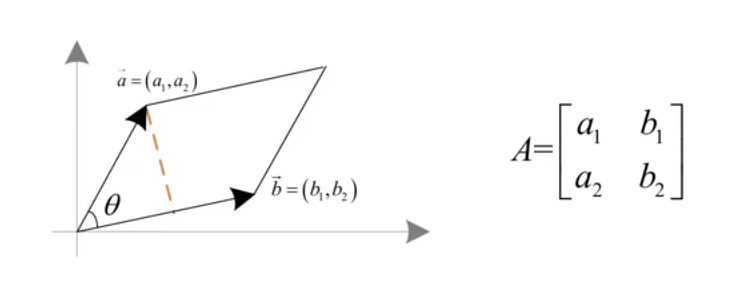
行列式的绝对值等于两向量围成平行四边形的面积(三个向量就是体积并以此类推):
![image]()
【证明】
已知平行四边形面积为 \(S=\|\boldsymbol{a}\|\|\boldsymbol{b}\| \sin \theta\),根据内积有 $$ \boldsymbol{a} \cdot \boldsymbol{b} = |\boldsymbol{a}||\boldsymbol{b}| \cos \theta = a_{1} b_{1} + a_{2} b_{2} \quad \rightarrow \quad \cos \theta = \frac{a_{1} b_{1} + a_{2} b_{2}}{|\boldsymbol{a}||\boldsymbol{b}|} $$根据 \(\sin ^{2} \theta + \cos ^{2} \theta = 1\) 可得
\[\begin{aligned} \sin \theta = \sqrt{1 - \cos ^{2} \theta} & = \sqrt{\frac{\left(a_{1}^{2} + a_{2}^{2}\right)\left(b_{1}^{2} + b_{2}^{2}\right)}{\left(a_{1}^{2} + a_{2}^{2}\right)\left(b_{1}^{2} + b_{2}^{2}\right)} - \frac{\left(a_{1} b_{1} + a_{2} b_{2}\right)^{2}}{\left(a_{1}^{2} + a_{2}^{2}\right)\left(b_{1}^{2} + b_{2}^{2}\right)}} \\ & = \sqrt{\frac{a_{1}^{2} b_{1}^{2} + a_{1}^{2} b_{2}^{2} + a_{2}^{2} b_{1}^{2} + a_{2}^{2} b_{2}^{2} - a_{1}^{2} b_{1}^{2} - 2 a_{1} b_{1} a_{2} b_{2} - a_{2}^{2} b_{2}^{2}}{\left(a_{1}^{2} + a_{2}^{2}\right)\left(b_{1}^{2} + b_{2}^{2}\right)}} \\ & = \sqrt{\frac{a_{1}^{2} b_{2}^{2} - 2 a_{1} b_{2} a_{2} b_{1} + a_{2}^{2} b_{1}^{2}}{\left(a_{1}^{2} + a_{2}^{2}\right)\left(b_{1}^{2} + b_{2}^{2}\right)}} \\ & = \frac{\left|a_{1} b_{2} - a_{2} b_{1}\right|}{\|\boldsymbol{a}\|\|\boldsymbol{b}\|} \end{aligned} \]所以有
\[S = \|\boldsymbol{a}\|\|\boldsymbol{b}\| \sin \theta = \|\boldsymbol{a}\|\|\boldsymbol{b}\| \frac{\left|a_{1} b_{2} - a_{2} b_{1}\right|}{\|\boldsymbol{a}\|\|\boldsymbol{b}\|} = \left|a_{1} b_{2} - a_{2} b_{1}\right| \] -
行列式的性质:
- 假设\(\boldsymbol{A}\)是\(n\times n\)型方阵,行列式运算满足:\(\left|\boldsymbol{A}^{\top}\right| = |\boldsymbol{A}|\),\(|\lambda \boldsymbol{A}| = \lambda^{n}|\boldsymbol{A}|\),\(|\boldsymbol{A}\boldsymbol{B}| = |\boldsymbol{A}||\boldsymbol{B}|\)
- 若 \(\boldsymbol{A}\) 可逆则 \(\left|\boldsymbol{A}^{-1}\right| = \dfrac{1}{|A|}\);若 \(\boldsymbol{A}\) 不可逆(\(|\boldsymbol{A}| = 0\))则称 \(A\) 为奇异矩阵。(\(\boldsymbol{A}\)不可逆\(\Leftrightarrow|\boldsymbol{A}|=0\);\(\boldsymbol{A}\)可逆\(\Leftrightarrow|\boldsymbol{A}|\ne 0\))
- 交换矩阵的某两行或某两列,行列式反号
- 基于 \(A\) 通过矩阵乘法对几何图形做线性变换,则:
- \(|A| > 1\):扩展图形的面积,\(|A| < 1\):收缩图形面积
- \(|A| = 1\):保持面积(但不代表不改变图形形状),\(|A| = 0\):将图形压缩到低维子空间
2.2 秩
秩反映了矩阵行、列向量的无关性,从抽象角度来说它反应了矩阵包含的信息量
若矩阵\(\boldsymbol{A}\)中有行列式不等于零的\(r\)阶子式\(D\)且没有行列式不等于零的\(r+1\)阶子式,则\(D\)为\(\boldsymbol{A}\)的最高阶非零子式,数\(r\)称为矩阵\(\boldsymbol{A}\)的秩,记作\(R(\boldsymbol{A})\)(或\(\operatorname{rank}(\boldsymbol{A}), r(\boldsymbol{A})\)),规定零矩阵的秩等于零。
【注】何为子式:
一、子式的核心:从矩阵里"剪小方块"算行列式
子式可以理解为:从矩阵中挑若干行和列,交叉位置的元素组成小矩阵,再算这个小矩阵的行列式。
- 例子:假设矩阵
\[ \boldsymbol{A} = \left( \begin{array}{ccc} a & b & c \\ d & e & f \\ g & h & i \end{array} \right) \]挑第1、2行和第1、2列,得到小矩阵:
\[ \left( \begin{array}{cc} a & b \\ d & e \end{array} \right) \]它的行列式是 \(a×e - b×d\),这个数就是矩阵 \(\boldsymbol{A}\) 的一个二阶子式。
二、子式的"阶数":挑多少行列就是多少阶
- 一阶子式:挑1行1列,即矩阵中的某个元素本身,如 (a) 的子式就是 (a);
- 二阶子式:挑2行2列,如上面的例子;
- n阶子式:从n×m矩阵中挑k行k列(k≤min(n,m)),组成k×k小矩阵的行列式。
三、子式的作用:用"小方块"判断矩阵的"信息量"
矩阵的秩由最高阶非零子式决定:
- 若最大的非零子式是k阶,则矩阵的秩为k。
- 例子:矩阵
\[ \boldsymbol{A} = \left( \begin{array}{cccc} 3 & 1 & 0 & 2 \\ 1 & -1 & 2 & -1 \\ 1 & 3 & -4 & 4 \end{array} \right) \]
- 能找到二阶子式非零,如 \(\left| \begin{array}{cc}3 & 1 \\ 1 & -1\end{array} \right| = -4\);
- 所有三阶子式(挑3行3列)的行列式都是0,故最高阶非零子式是2阶,秩为2。
四、类比理解:像"裁剪照片"选关键信息
- 矩阵 → 数字照片,子式 → 裁剪出的小方块;
- 一阶子式 → 照片中的一个像素;
- 高阶子式 → 更大的裁剪区域;
- 最高阶非零子式 → 能保留"有效信息"的最大裁剪块,决定了矩阵的"信息丰富度"(秩)。
关键总结
- 子式=挑行列→小矩阵→算行列式;
- 阶数=挑的行列数,一阶子式就是元素本身;
- 用途:通过最高阶非零子式确定矩阵的秩,判断矩阵中的独立信息量。
【注】子式也可以取不相邻的行列,比如:设4×4矩阵:
\[\boldsymbol{A} = \left( \begin{array}{cccc} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \\ 13 & 14 & 15 & 16 \end{array} \right) \]选取不相邻的行和列:
- 挑行:跳过第2行,选第1行和第3行(不相邻);
- 挑列:跳过第1列和第3列,选第2列和第4列(不相邻)。
挑出的交叉元素组成2×2小矩阵:\[\left( \begin{array}{cc} \boldsymbol{A}_{1,2} & \boldsymbol{A}_{1,4} \\ \boldsymbol{A}_{3,2} & \boldsymbol{A}_{3,4} \end{array} \right) = \left( \begin{array}{cc} 2 & 4 \\ 10 & 12 \end{array} \right) \]这个小矩阵的行列式也是这个大矩阵行列式的子式。
总结为:任取\(k\)行\(k\)列,它们交叉处的元素构成一个子式。
假设\(\boldsymbol{A}=\left(\begin{array}{cccc}3 & 1 & 0 & 2 \\ 1 & -1 & 2 & -1 \\ 1 & 3 & -4 & 4\end{array}\right)\),因为一共有12个元素,所以有12个一阶子式\({ }^{14}\),很容易找到行列式不等于0的一阶子式,例如\(\operatorname{det}(3)=3 \neq 0\)。\(\boldsymbol{A}\)中一共有\(C_{3}^{2} C_{4}^{2}=3 \times 6=18\)个二阶子式,也很容易找到行列式不为0的子式,如\(\left|\begin{array}{cc}3 & 1 \\ 1 & -1\end{array}\right|=-4 \neq 0\)。\(\boldsymbol{A}\)中共有\(C_{3}^{3} C_{4}^{3}=4\)个三阶子式,但这四个三阶子式都为零,所以\(R(\boldsymbol{A})=2\)。
用定义求矩阵的秩计算过程非常复杂,初等变换不改变矩阵的秩,可以通过初等变换来求。初等变换包括三种:
- 交换矩阵中的两行(列)
- 数乘矩阵中的某一行(列)
- 数乘矩阵中的某一行(列)再加到其它行(列)
【注】\(r[0]\)代表的是下标为0的行,以此类推。\(r[0]\times (-3) + r[2]\)表示下标为0的行乘以-3后加到下标为2的行上,最后改变的下标为2的行。
任意矩阵的行秩等于列秩(即线性无关的行向量数等于线性无关的列向量数),秩具有如下性质:
- \(0 \leq r\left(\boldsymbol{A}_{m \times n}\right) \leq \min (m, n)\)
- \(r\left(\boldsymbol{A}^{\top}\right)=r(\boldsymbol{A})\)
- 若\(\boldsymbol{P}, \boldsymbol{Q}\)可逆,则\(r(\boldsymbol{P A Q})=r(\boldsymbol{A})\)
- \(r_{\text {row }}(\boldsymbol{A})=r_{\text {col }}(\boldsymbol{A})=r(\boldsymbol{A})\)
- 总是有\(r\left(\boldsymbol{A}^{\top} \boldsymbol{A}\right)=r\left(\boldsymbol{A} \boldsymbol{A}^{\top}\right)=r(\boldsymbol{A})\)
列满秩阵左可逆,行满秩阵右可逆。若方阵满秩则为可逆阵。
【注】\(r_{row}\)是行秩,\(r_{col}\)是列秩。
2.3 迹
【补】矩阵的特征值:
一、特征值的核心:矩阵变换中的“缩放因子”
假设你有一个矩阵 \(\boldsymbol{A}\),它可以对向量进行“线性变换”(比如旋转、缩放、拉伸)。
特征值就是这样一个数 \(\lambda\):存在某个非零向量 \(\boldsymbol{x}\),使得矩阵 \(\boldsymbol{A}\) 对 \(\boldsymbol{x}\) 的变换效果,等价于直接将 \(\boldsymbol{x}\) 缩放 \(\lambda\) 倍,即:
\[\boldsymbol{A}\boldsymbol{x} = \lambda\boldsymbol{x} \]这里的 \(\boldsymbol{x}\) 称为 特征向量,\(\lambda\) 就是对应的 特征值。
二、几何意义:找到“方向不变”的变换
直观理解:大多数向量被矩阵 \(\boldsymbol{A}\) 变换后,方向会改变(比如从 \((1,0)\) 变成 \((2,3)\))。
特殊情况:如果存在向量 \(\boldsymbol{x}\) 变换后方向不变(或相反),只是长度缩放了 \(\lambda\) 倍,那么 \(\lambda\) 就是特征值,\(\boldsymbol{x}\) 就是特征向量。
例如:矩阵 \(\boldsymbol{A} = \left(\begin{array}{cc}2 & 0 \\ 0 & 3\end{array}\right)\) 对向量 \(\boldsymbol{x} = (1,0)\) 的变换是 \((2,0)\),即缩放了 2 倍,所以 \(\lambda=2\) 是特征值。
三、数学定义与计算
特征方程:
由 \(\boldsymbol{A}\boldsymbol{x} = \lambda\boldsymbol{x}\) 变形为 \((\boldsymbol{A} - \lambda\boldsymbol{I})\boldsymbol{x} = \mathbf{0}\),其中 \(\boldsymbol{I}\) 是单位矩阵。 因为 \(\boldsymbol{x}\) 是非零向量,所以矩阵 \((\boldsymbol{A} - \lambda\boldsymbol{I})\) 必须不可逆(否则只有零解),即其行列式为 0: $$ \det(\boldsymbol{A} - \lambda\boldsymbol{I}) = 0 $$ 这个方程称为 特征方程,解出的 \(\lambda\) 就是特征值,也叫特征根,有多个重复的特征根叫作重特征根,有几个重复的特征值就叫作几重特征根。
例子(2×2矩阵):
设 \(\boldsymbol{A} = \left(\begin{array}{cc}1 & 2 \\ 3 & 0\end{array}\right)\),特征方程为:
\[\det\left(\begin{array}{cc}1-\lambda & 2 \\ 3 & -\lambda\end{array}\right) = (1-\lambda)(-\lambda) - 6 = \lambda^2 - \lambda - 6 = 0 \]解得特征值 \(\lambda = 3\) 和 \(\lambda = -2\)。
四、特征值的关键性质
和与积:
所有特征值的和等于矩阵的迹(对角线元素之和),即 \(\lambda_1 + \lambda_2 + \dots + \lambda_n = \operatorname{tr}(\boldsymbol{A})\);
所有特征值的积等于矩阵的行列式,即 \(\lambda_1\lambda_2\dots\lambda_n = \det(\boldsymbol{A})\)。
物理意义:
在机器学习中,特征值常用于 主成分分析(PCA),通过最大特征值对应的特征向量,找到数据变化最大的方向(主成分)。
五、一句话总结
特征值是矩阵在“拉伸/压缩”变换中保持向量方向不变的“缩放因子”,通过解特征方程 \(\det(\boldsymbol{A} - \lambda\boldsymbol{I}) = 0\) 得到,是理解矩阵变换本质的核心概念。
矩阵的迹是针对方阵而言的:\(n \times n\)型矩阵\(\boldsymbol{A}\)的对角元素之和称为\(\boldsymbol{A}\)的迹(trace),记作\(\operatorname{tr}(\boldsymbol{A})\)
迹具有如下一些性质:
- \(\operatorname{tr}(\boldsymbol{A} \pm \boldsymbol{B}) = \operatorname{tr}(\boldsymbol{A}) \pm \operatorname{tr}(\boldsymbol{B})\),\(\operatorname{tr}(\lambda\boldsymbol{A}) = \lambda\operatorname{tr}(\boldsymbol{A})\),\(\operatorname{tr}(\boldsymbol{A}^{\top}) = \operatorname{tr}(\boldsymbol{A})\)
- 若\(\boldsymbol{U}\)是\(m \times n\)型、\(\boldsymbol{V}\)是\(n \times m\)型,则\(\operatorname{tr}(\boldsymbol{U}\boldsymbol{V}) = \operatorname{tr}(\boldsymbol{V}\boldsymbol{U})\)
- 若令\(\boldsymbol{U}=\boldsymbol{A}\),\(\boldsymbol{V}=\boldsymbol{B}\boldsymbol{C}\)或\(\boldsymbol{U}=\boldsymbol{A}\boldsymbol{B}\),\(\boldsymbol{V}=\boldsymbol{C}\),只要能进行矩阵乘就有\(\operatorname{tr}(\boldsymbol{A}\boldsymbol{B}\boldsymbol{C}) = \operatorname{tr}(\boldsymbol{B}\boldsymbol{C}\boldsymbol{A}) = \operatorname{tr}(\boldsymbol{C}\boldsymbol{A}\boldsymbol{B})\)
- 迹等于特征值之和,即\(\operatorname{tr}(\boldsymbol{A}) = \lambda_{1} + \lambda_{2} + \cdots + \lambda_{n}\)
- 若\(\boldsymbol{A}, \boldsymbol{B}\)均为\(m \times m\)型矩阵且\(\boldsymbol{B}\)非奇异(可逆),则有\(\operatorname{tr}(\boldsymbol{B}\boldsymbol{A}\boldsymbol{B}^{-1}) = \operatorname{tr}(\boldsymbol{B}^{-1}\boldsymbol{A}\boldsymbol{B}) = \operatorname{tr}(\boldsymbol{A}\boldsymbol{B}\boldsymbol{B}^{-1}) = \operatorname{tr}(\boldsymbol{A})\)
2.4 范数
矩阵范数与向量范数类似(方阵,非方阵都可以定义范数),采用公理化定义,其中一种是 p 矩阵范数:
三种典型的 p 范数包括:
- L₁ 范数:\(\|\boldsymbol{A}\|_{1} = \sum_{i=1}^{m} \sum_{j=1}^{n} \left|a_{i j}\right|\)
- Frobenius 范数(相当于向量的距离):\(\|\boldsymbol{A}\| = \left( \sum_{i=1}^{m} \sum_{j=1}^{n} \left|a_{i j}\right|^{2} \right)^{1 / 2}\)
- 最大范数(\(p = \infty\)):\(\|\boldsymbol{A}\|_{\infty} = \max _{i, j} \left\{ \left|a_{i j}\right| \right\}\)
此外,设有矩阵 \(\boldsymbol{A}\),\(\boldsymbol{A}^{\top}\boldsymbol{A}\) 的最大特征值的平方根称为 \(\boldsymbol{A}\) 的 谱范数:
【补】矩阵的奇异值:
注释:矩阵的奇异值是线性代数中的重要概念,在机器学习、图像处理等领域有广泛应用。
奇异值的核心:矩阵变换的"缩放密码"
矩阵可以对向量做线性变换(如旋转、拉伸),而奇异值描述了矩阵在各个方向上的"最大缩放能力"。
- 直观类比:矩阵变换就像用放大镜看图片,奇异值相当于不同方向上的"放大倍数"。最大奇异值是图片被拉伸最厉害的程度,最小奇异值是拉伸最弱的程度。
从特征值到奇异值:适配任意矩阵的"缩放因子"
- 特征值的局限:只能用于方阵,描述方阵对特征向量的缩放;
- 奇异值的突破:适用于任意矩阵\(\boldsymbol{A}\)(无论是否为方阵),定义为\(\boldsymbol{A}^{\top}\boldsymbol{A}\)或\(\boldsymbol{A}\boldsymbol{A}^{\top}\)的特征值的平方根。
- 设\(\boldsymbol{A}\)是\(m×n\)矩阵,\(\boldsymbol{A}^{\top}\boldsymbol{A}\)是\(n×n\)方阵,其特征值\(\lambda_1 \geq \lambda_2 \geq \dots \geq \lambda_n \geq 0\),则\(\sqrt{\lambda_i}\)就是\(\boldsymbol{A}\)的奇异值,记作\(\sigma_1 \geq \sigma_2 \geq \dots \geq \sigma_n\)。
几何意义:矩阵变换的"拉伸程度"
- 任意向量\(\boldsymbol{x}\)被矩阵\(\boldsymbol{A}\)变换后,长度满足:
\[\sigma_{\min}\|\boldsymbol{x}\| \leq \|\boldsymbol{A}\boldsymbol{x}\| \leq \sigma_{\max}\|\boldsymbol{x}\| \]其中\(\sigma_{\max}\)是最大奇异值,\(\sigma_{\min}\)是最小奇异值。- 例子:若\(\boldsymbol{A}\)是缩放矩阵\(\left(\begin{array}{cc}3 & 0 \\ 0 & 1\end{array}\right)\),则奇异值就是3和1,分别对应x轴方向拉伸3倍,y轴方向拉伸1倍。
奇异值分解(SVD):矩阵的"基本组成"
奇异值可以通过奇异值分解得到:\[\boldsymbol{A} = \boldsymbol{U}\boldsymbol{\Sigma}\boldsymbol{V}^{\top} \]
- 正交矩阵简介:\(\boldsymbol{U}\)和\(\boldsymbol{V}\)是正交矩阵,其特点是矩阵的列向量两两正交(点积为0,点积就是内积,叫法不同)且长度为1。正交矩阵对应"旋转变换",不会改变向量的长度和夹角。例如,二维旋转矩阵\(\left(\begin{array}{cc}\cos\theta & -\sin\theta \\ \sin\theta & \cos\theta\end{array}\right)\)就是正交矩阵。
- \(\boldsymbol{\Sigma}\)是对角矩阵,对角线元素就是奇异值\(\sigma_1, \sigma_2, \dots\)(对应缩放)。
- 直观理解:矩阵\(\boldsymbol{A}\)的变换可拆分为:旋转→按奇异值缩放→再旋转。
奇异值的应用:抓住矩阵的"关键信息"
- 数据压缩:较大的奇异值对应矩阵的主要信息,忽略小奇异值可压缩数据(如图片压缩);
- 主成分分析(PCA):最大奇异值对应的方向是数据变化最大的方向;
- 矩阵近似:用前k个最大奇异值对应的部分可近似原矩阵,减少计算量。
一句话总结
奇异值是矩阵在不同方向上的"缩放因子",通过\(\boldsymbol{A}^{\top}\boldsymbol{A}\)的特征值平方根得到,能描述矩阵变换的强度,是理解矩阵性质(如重要性、压缩性)的核心概念,尤其在机器学习和数据处理中应用广泛。
【注】\(\boldsymbol{A}\)的谱范数其实是\(\boldsymbol{A}\)的奇异值,而非最大特征值
2.5 条件数
矩阵条件数是衡量矩阵在数值计算中"病态程度"的指标,本质上描述矩阵对输入扰动的放大能力。设\(\boldsymbol{A}\)为可逆方阵,其条件数定义为:
- 常用范数:计算时通常选用\(\text{L}_1\)范数或\(\text{L}_{\infty}\)范数(减少计算量)。
- 直观意义:若\(\boldsymbol{A}\)的条件数很大,即使输入向量有微小扰动,经过\(\boldsymbol{A}\)变换后也可能产生显著误差。
对于非方阵\(\boldsymbol{A}\),条件数通过奇异值定义:
-
\(\sigma_{\max}\)和\(\sigma_{\min}\)分别为\(\boldsymbol{A}\)的最大奇异值和最小奇异值,反映矩阵在不同方向上的缩放差异。
-
条件数小(接近1):矩阵变换稳定,输入扰动对输出影响小(如\(\operatorname{cond}(\boldsymbol{A})=1\)时,矩阵为正交矩阵,变换无误差放大)。
-
条件数大:矩阵"病态",输入微小变化可能导致输出剧烈波动。
- 例子:若\(\operatorname{cond}(\boldsymbol{A})=1000\),输入有1%的扰动,输出误差可能放大至10%。
条件数通过矩阵范数或奇异值之比,量化了矩阵变换对误差的放大能力,条件数越小,矩阵在数值计算中的稳定性越高。
【注】在学术论文中会遇到这样的表述:条件数较小表示矩阵是良条件的(well-conditioned),条件数较大表示矩阵是病态的(ill-conditioned)
2.6 其它重要数值量
其它重要数值量
- 特征值特征向量:在后文中专门介绍
- 奇异值奇异向量:在SVD中专门介绍
- 谱半径:矩阵最大的特征值,在后文中专门介绍
- 正、负、零惯性指数:正、负、零特征值数量, \(n\) 重特征根计算时算 \(n\) 次,正负惯性指数之和等于矩阵的秩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号