(九)假设检验
学习假设检验的基础知识,包括如何设置假设检验。
统计学家规定了关于可能性或不可能性的三个常规级别:如果达到样本均值的概率小于,0.05 即 5%,0.01 即 1% 或 0.001 即 0.1%,那么通常被视为不太可能发生。概率小于 0.1% 的情况是非常不可能的,这些叫做 α 水平。
现在做一道快速测试题来理解 α 水平是什么,我们重点讨论下 α 水平 0.05 以下哪些说法是正确的?
以下哪些说法是正确的? □ 如果达到特定样本均值的概率小于 α 水平, 它“不太可能”发生。 □ 如果样本均值的 z 值大于 z* 那么“不太可能”发生。 □ 第三个选项是如果达到特定样本均值的概率是“不太可能”,那么样本均值位于橘色区域。 □ α 水平对应的是橘色区域。


AB α 水平是用来判断某个事物可能或不可能发生的标准,如果概率小于 α 水平,则被视为不太可能, 如果样本均值的 z 值大于 z*则表明选中该样本均值的概率甚至更小,因此第二个选项也对,如果 z 值大于 z* 的样本均值被视为不可能,但是如果落在黄色区域,则表明是可能发生的,因此第三个选项不对,最后一个选项 α 水平是 0.05,即 5%,对应的是绿色区域,不是橘色区域
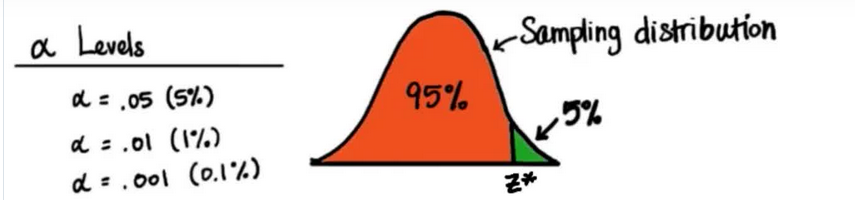
我们规定,获得特定样本均值的概率小于 α 水平时,该均值落入的这个末端叫做临界区。这个将临界区与其他区域分开的 z 值,叫做 z 临界值。
如果样本均值的 z 值大于 z 临界值,我们可以证明样本统计数据与普通的或未经处理的总体不一样。
假设这个红色临界区的概率是 0.05 即 5%,也就是说 α 水平是 0.05 那么这个 Z 临界值是多少?
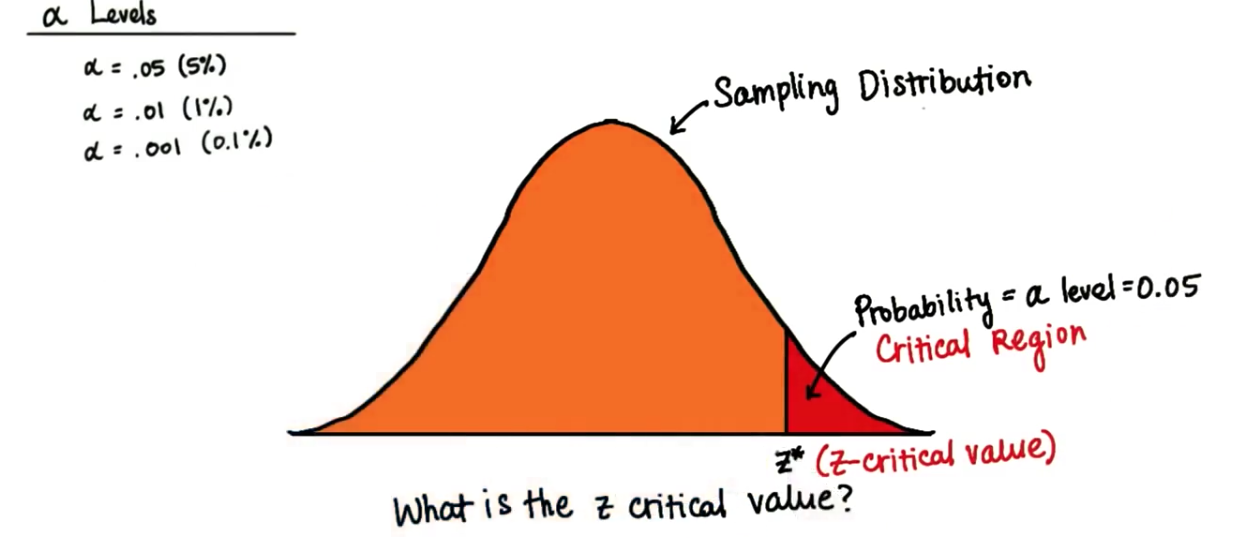
使用 Z 表,如果 5% 大于这个 Z 值,那么表明 95% 必须小于这个 Z 值,我们从表格中找到 0.95,对应的Z值大约是1.64或1.65
样本均值概率小于 0.01 时被视为不太可能发生,那么表示这个临界值的 Z 值是多少?
根据Z表格得出大约为2.33
样本均值概率小于 0.001 时被视为不太可能发生,那么表示这个临界值的 Z 值是多少?
3.08
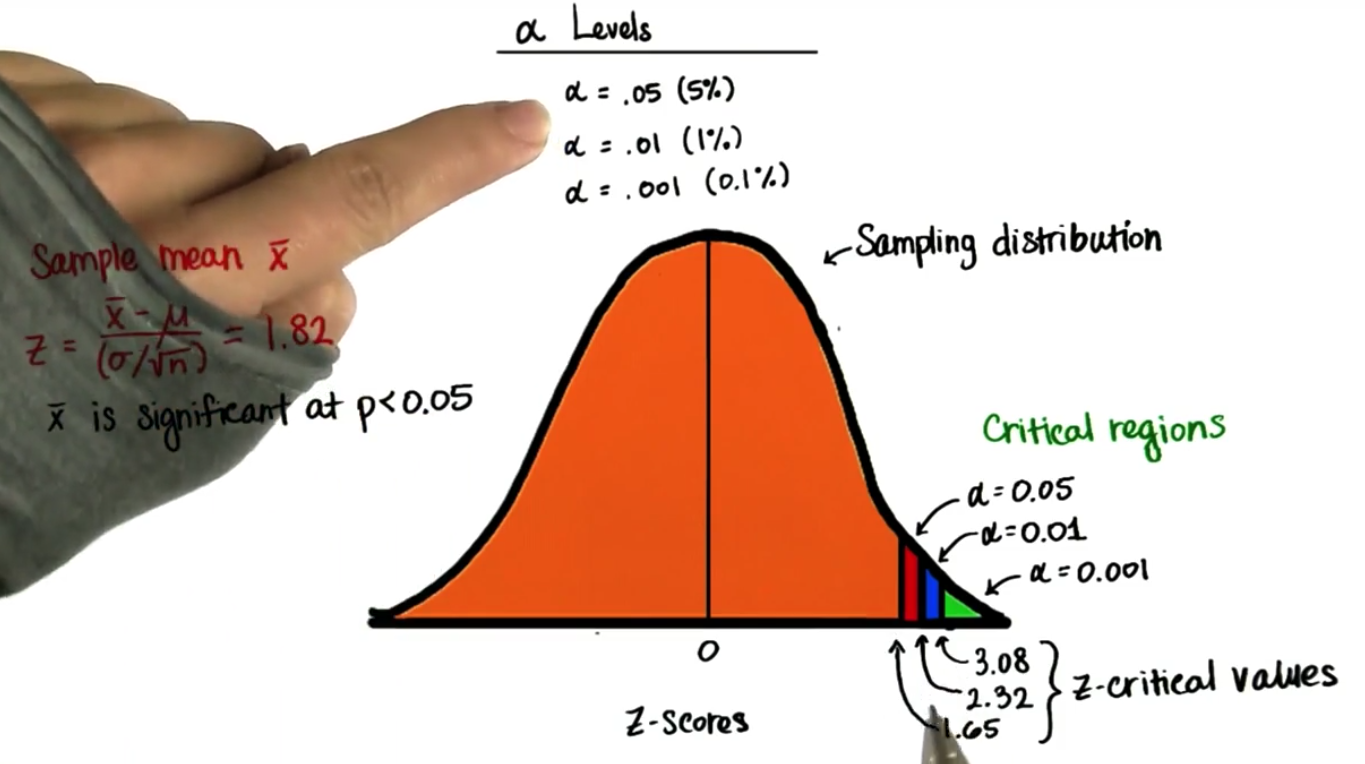
我们将找到样本均值,算出在样本均值分布,即抽样分布上的 z 值,然后看看这个均值位于何处,假设均值位于任何一个临界区表明不太可能发生,
如果位于绿色区域即最小的临界区,我们将报告最小的 α 水平,因为这表明我们的样本统计数据与总体参数非常不同,因此证明很有可能采取了任何形式的人为处理措施,例如我们算出某些样本量为 n 的样本均值,并算出 z 值,我们减去 μ 然后除以抽样分布的标准偏差,假设 z 值是 1.82,我们可以说这在比例小于 0.05 时具有统计显著意义,因为如果看看这个 z 值会落在分布上的哪个位置,会发现它落在 1.65 和 2.32 之间,所以这个 z 值 1.82 位于这个红色区域的某个位置,表明获得这个样本均值的概率小于 0.05,但是并不小于 0.01,所以它仅在比例小于 0.05 时具有统计显著意义,注意 0.05 是 α 水平。
如果比较难以理解,可以将这一切想象成玩飞镖,从地面到靶眼的标准高度,是 5 英尺、8 英寸,人要距离镖靶 7 英尺 ,9/4 英寸,镖靶制作者需要判断镖靶应该是多大,目标越大,甚至是墙的话,就越容易击中,但也更有可能是偶然击中的,目标越小越难击中,但是一旦击中,我们就更加确信我们不是偶然击中的,所以靶眼应该足够的大,使我们有可能击中,但是又足够的小,当我们击中后,是因为我们的技术,必须存在一个平衡点,镖靶上的这些目标就类似于临界区每个区域的界限类似于不同的 α 水平,我们可以轻松地获得位于这个区域的均值,但是如果均值位于 z 为 1.65 的区域之外,那么获得该均值的概率小于 α 水平 0.05,不太可能是偶然发生的,如果均值在 z 值为 2.32 的区域之外,那么更不太可能发生,此时的概率是 0.01,非常不太可能是偶然发生的,如果均值在 z 值为 3.08 之外的区域那么就相当于击中靶眼了。
再看一个例子
用一首歌来讲解这个概念,并且我们想知道是否有助于学员学习知识并提高他们的参与度,假设在我唱歌后,观看了这节课的 20 名学员报告的参与度均值为 7.13,注意他们是按照从 1 到 10 的范围为自己的参与度打分,
然后我们算出这 20 名学员的平均分数结果是 7.13,我们暂时先不讨论学习程度,首先,该样本均值的 z 值应该是多少?提醒下,我们假设总体均值是 7.5,总体标准偏差是 0.64,当我们算出样本均值的 z 值后,我们
将其与整个抽样分布进行比较。
-2.59 我们的样本由 20 名学员组成,样本均值和总体均值相同,标准误差即抽样分布的标准偏差是总体标准偏差除以样本量的平方根。结果约为 0.14 ,=(7.13-7.5)/0.14=-2.59
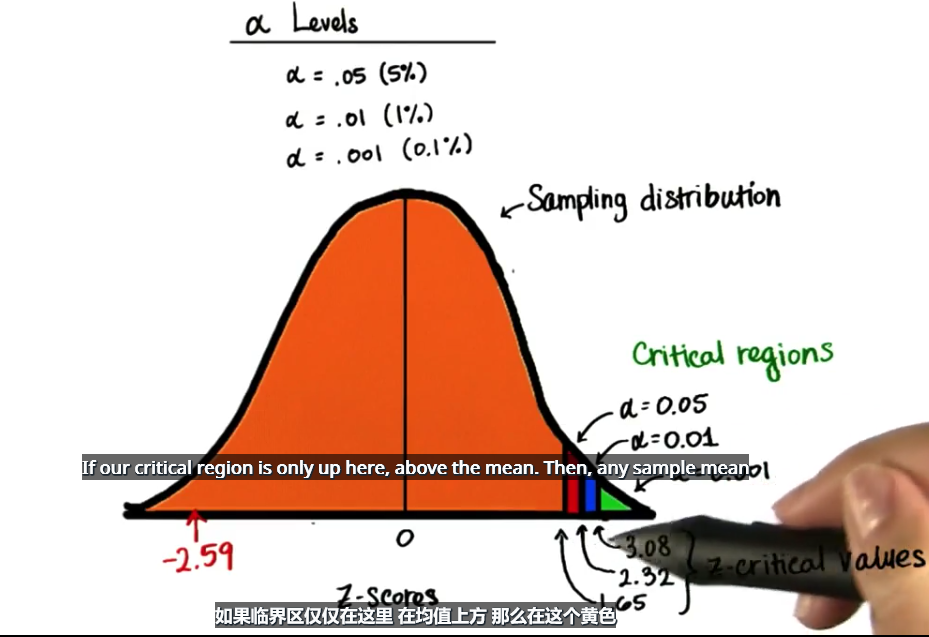
如果临界区仅仅在这里 在均值上方,那么在这个黄色或橘色区域的任何样本均值都将被视为可能发生,但是 z 值为 -2.59 的情况也能被视为可能发生吗?我们将临界区分成两半,同样我们先重点讨论 α 水平 0.05,如果将 0.05 分成两半,那么每端是 2.5%,如下图所示,那么现在的 Z 临界值就变了,这里的 Z 值应该是多少呢?
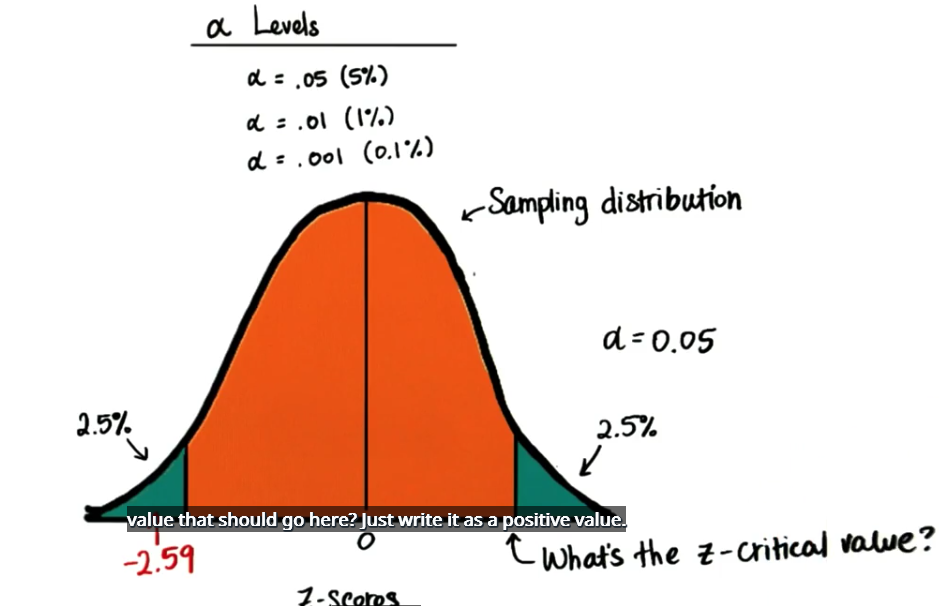
通过Z表格可以查出小于 2.5%(左边) 对应的Z值是-1.96,因为这个分布是对称的表明右边的这个 Z 临界值是正的 1.96。
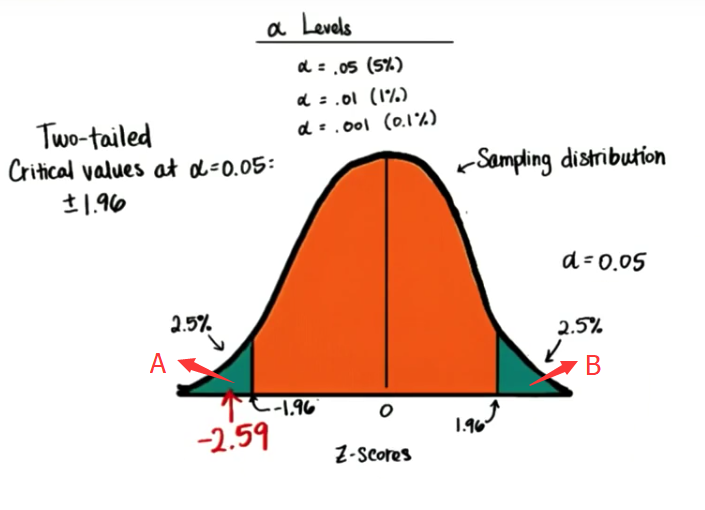
现在临界区既在A区,又在B区,而不是仅在一端,如果我们采用这个 α 水平并进行双尾检验看看达到这个样本均值是否有可能,我们可以怎么说?
对于样本均值 x-bar = 7.13(z 值等于 - 2.59),我们可以得出什么结论? A.□ 不太可能获得 7.13 的参与度均值 B.□ 参与度均值 7.13 不在临界区内 C.□ 可以证明我唱的歌降低了学员的参与度 D.□ 参与度均值 7.13 在概率小于 0.05 时具有统计显著意义
可以看到 -2.59 小于 α 水平是 0.05 时的临界值 -1.96,因为它在A临界区内,所以我们可以说不太可能达到 7.13 的参与度均值,但是这个参与度均值的确位于临界区内,有证据表明我唱的歌降低了学员的参与度,或许我在上课时还是应该以讲解为主,我们也可以说,参与度均值 7.13 在概率小于 0.05 时具有统计显著意义,在两个方向获得距离均值这么远的参与度分数的概率,小于 0.05 这基本上就是双尾检验的含义。
我们现在来算算另外两个 α 水平的双尾检验的 Z 临界值,α 水平为0.01和0.001时的Z值是多少
0.01对应的Z值是±2.57,0.001对应的Z值是±3.32。
这意味着什么?根据我们对可能或不可能的条件定义,如果我们获取临界区的样本均值,根据单尾检验或是双尾检验,那么我们可以判断,我们很有可能没有偶然地获得这个样本均值,注意在双尾检验中,Z 临界值和用来计算置信区间的 Z 值是相同的,这里只是将同一概念应用到了不同的情形,在进行统计检验时,我们会自己设定判断条件,也就是说,我们将自己选择一个 α 水平,然后规定如果获得特定样本均值的概率小于该 α 水平,那么就证明有效,通常我们会选择α 水平 0.05,对于 α 水平 0.05,在单尾检验和双尾检验这两种情形下都存在两种可能的结果,样本均值要么位于临界区之外,要么位于临界区之内,我们将这两种结果称为零假设,并用 H0(零假设)或 Ha(对立假设)来表示,其他的表示方式可以是 H1,但我将用 Ha 表示对立假设。
零假设认为当前总体参数和在某种干预后出现的新总体参数之间没有显著差异,我们将表示为当前总体参数μ 等于干预后的总体参数。这里说的等于并非完全等于,我们只是说它俩并没有显著差异。
对立假设猜测存在显著差异,当前总体均值将比干预后的总体均值小或大 或者二者之间不相等,我们不会预测干预的效果。
对于零假设,当我们猜测这两个参数之间没有显著差异时,样本均值将位于临界区之外,在下图白色区域,同时请注意,对于单尾检验,临界区可能在左端 而不是右端,对立假设猜测存在显著差异,表明样本均值将位于临界区的某个位置
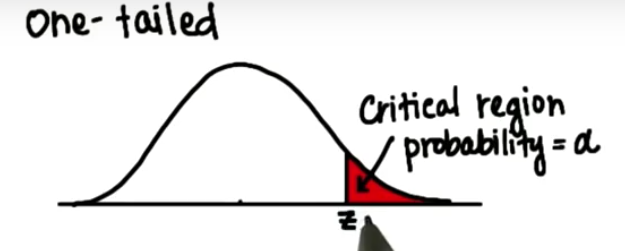
我们无法证明零假设是对的,我们只能获取证据来拒绝零假设,我们来看个简单的示例
假设我们的零假设是大多数狗都有 4 条腿,我们将大多数定义为超过 50% 的狗,这个 50% 就类似于我们为做出决策而设定的α 水平类似,对立假设是指大多数狗都有不到 4 条腿,注意,这就类似于单尾检验,我们没有猜
测大多数狗具有不同数量的腿,而不是 4 条,我们猜错的是大多数狗有不到 4 条腿,所以存在判断方向,现在假设抽出 10 只狗,发现它们都有 4 条腿,我们证明了零假设是对的,大多数狗都有 4 条腿吗?
没有 我们有证据表明大多数狗有 4 条腿,因为在我们的样本中,所有的狗都有 4 条腿,但是我们没有证明大多数狗有 4 条腿,在这种情形下,我们也没有证明对立假设,但根据我们的样本,我们也无法拒绝零假设
现在假设有 10 只狗的样本,其中 6 只有 3 条腿,这样能拒绝零假设,即大多数狗有 4 条腿吗?
能够 完全根据我们的样本,我们发现大多数狗有不到 4 条腿,如果这就是样本结果,那么我们就可以拒绝零假设,并倾向于对立假设。
我们再延伸下这些概念,将其应用到更加复杂的情形,
按照 1 到 10 分的范围对你的参与度和学习程度打分,在分析该数据前请注意一点,这里并没有清晰地定义参与度和学习程度,例如,如果某人只有时间看一节课程,然后就忙别的了,他们的参与度可能是 1,但并不能表明他
们不喜欢所观看的内容,所以大家的打分结果存在各种主观原因,这个示例很好地证明了置信区间并非在经过某种干预后分析数据的最佳方式,因为大家给的分数没有实际的含义,但总体来说,我们可以判断分数越高表明越好,
这时候假设检验就派上用场了,首先我们来熟悉下这些数据,下图是显示学员回答结果的直方图,对于下面的这个示例,我们重点讨论参与度,参与度的均值和标准偏差是多少?
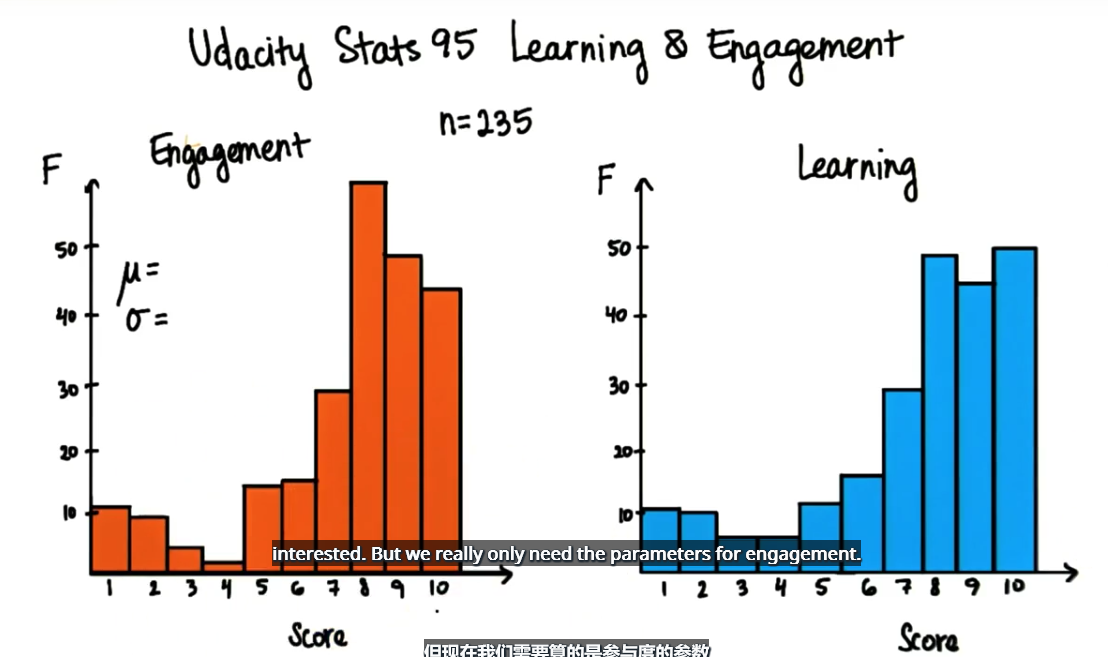
均值是 7.47 标准偏差是 2.41
假设我们想知道一首关于课程内容的歌曲,对参与度有何影响,我们将设置一个假设检验,将当前的总体与经过这一处理或干预后我们预测的新总体进行对比。注意,在假设检验中,我们会有零假设和对立假设。零假设是指干预后的总体和当前总体参数之间没有显著差别;对立假设可以是以下三种情况,当前总体比干预后的小,比干预后的大或只是不同。
零假设是什么?
在课堂上唱歌会:
A.□ 让学生参与的更高
B.□ 不会让学生参与度更高
C.□ 改变高参与度学生的人数
D.□ 参与度不变
E.□ 让学生参与度更低
BD
对立假设是什么?
在课堂上唱歌会:
A.□ 让学生参与的更高
B.□ 不会让学生参与度更高
C.□ 改变高参与度学生的人数
D.□ 参与度不变
E.□ 让学生参与度更低
ACE
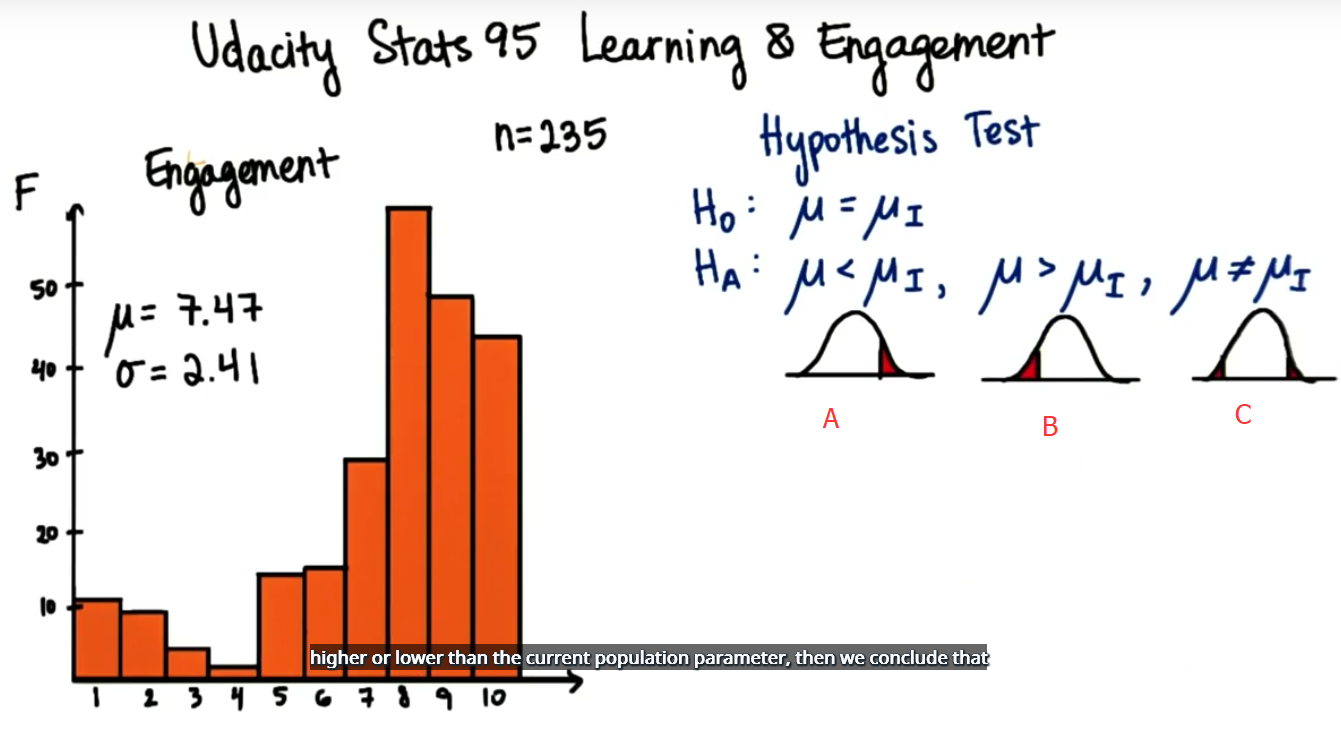
上图中AB两种对立假设是单尾检验,如果我们的样本均值位于这里的临界区,比当前总体均值显著要高,那么我们猜测干预后的总体参数将比当前的高,类似地,如果我们的样本均值位于小于当前总体参数的临界区,则干预后的总体参数将比当前的低,最后,如果我们的样本均值位于高于或低于当前总体参数的临界区 那么可以得出结论:新的总体将显著不同。
当我们要预测处理效应的方向时,我们选择单尾检验,即方向性假设检验。例如,当我们预测这节课中描述概念的歌曲是否会提高或降低参与度;当我们不需要预测处理效应的方向时,我们会选择双尾检验,即非方向性检验。通常,我们选择双尾检验,因为它们更加保守,当它为真时,我们不太可能会拒绝零假设。
正如你之前看到的,我们可能对方向预测错了,我们可能预测处理措施会提高参与度,实际上降低了参与度,在这种情况下,我们应该采取双尾检验,如果我们只是采取正面的单尾检验,我们可能忽视了处理措施与我们的预期背道而驰的情形,该一般规则的特例是我们对比新的处理措施和既有的处理措施,在这种情形下,我们通常只关心新的处理措施是否比旧措施效果要好,我们不关心新措施是否更糟糕,这时候我们会使用单尾方向性检验。
假设我们不知道该歌曲对参与度的影响,可能会降低学员的参与度,也可能提高参与度,因此在这里写上 μsong,因为歌曲是干预措施,我们将尝试检验该参数是否将比已经算出的参数显著不同,下一步是设定做出决策的判断条
件,我们的决策是拒绝或无法拒绝零假设,我们必须选择 α 水平,我们通常使用的是 0.05,表明对于双尾检验,右边是 2.5%,即 0.025,左端的比例也是 0.025,然后算出 Z 临界值,最后算出样本均值的 Z 值,看看它
是否位于临界区,然后据此判断是否拒绝零假设。 拒绝零假设的意思是什么? A.□ 样本均值在临界区域之内还是之外? B.□ 样本均值的 Z 值小于还是大于 Z 临界值? C.□ 得到样本均值的概率小于还是大于 α 水平?
A.之内
B.大于
C.小于

现在假设有一个由 30 名学员组成的样本,他们都可以观看这节音乐形式的课程,后来他们报告的参与度均值是 8.3,这个值位于所有样本量为 30 的样本均值分布的哪个位置?要回答这道题,请注意这个正态分布表示的是样
本均值分布,注意样本均值的均值应该和总体均值相同, 标准偏差应该等于总体标准偏差除以平方根 n,Z 值是多少?
Z 值等于样本均值减去总体均值再除以该分布的标准偏差,而标准偏差就等于标准误差,算出结果约为 1.89
现在我们已经算出该样本均值的 Z 值,那么在 α 水平 0.05 这里,对于双尾检验,我们是拒绝零假设还是不能拒绝零假设呢?
我们的 z 值是 1.89,小于 z 值 1.96,因此,我们的样本均值将位于上图的白色区域,即某个位于总体均值周围的95% 样本均值之一,因此我们不能拒绝 H0,即零假设。没有足够的证据可以证明在推出音乐形式的课程后,新的总体参数将与现在的总体参数显著不同,也就是说 根据我们的样本,我们猜测参与度将保持不变。
但是,如果样本均值还是 8.3,但是随机样本量是 50 呢?那么该样本均值会落在这个样本均值分布的哪个位置?同样的,请算出 Z 值。
(8.3-7.47)/(2.41/√50 ̄)结果约为 2.44
现在针对 α 水平 0.05 提出同样的问题,我们是拒绝零假设还是无法拒绝零假设?
这次 z 值是 2.44 大于 Z 临界值,表明我们的样本均值位于这里的红色区域某个位置,样本量为 50 的样本达到该样本均值的概率非常的小,小于 2.5%,这就是我们在双尾检验中需要知道的信息,因此我们将拒绝零假设。我们有证据证明歌曲对参与度有影响,用公式表达为 P(表示概率)小于 0.05(我们的 α 水平),因为从样本量为 50 的样本中获得该样本均值的概率小于我们的 α 水平

 浙公网安备 33010602011771号
浙公网安备 33010602011771号